Download

1 / 38
380 likes | 433 Vues
Explore advanced computer architecture concepts focusing on ISA, addressing modes, operand design, and instruction encoding. Learn the evolution and types of architectures. Study the influence on ISA and operand classifications.

E N D
Advanced Computer Architecture5MD00 / 5Z033Instruction Set Design Henk Corporaal www.ics.ele.tue.nl/~heco/courses/aca TUEindhoven November 2010
Lecture overview • ISA and Evolution • Architecture classes • Addressing • Operands • Operations • Encoding • RISC • SIMD extensions ACA H.Corporaal
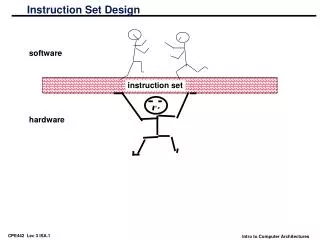
software instruction set architecture hardware Instruction Set Architecture • The instruction set architecture serves as the interface between software and hardware • It provides the mechanism by which the software tells the hardware what should be done • Architecture definition:“the architecture of a system/processor is (a minimal description of) its behavior as observed by its immediate users”
Instruction Set Design Issues • Where are operands stored? • registers, memory, stack, accumulator • How many explicit operands are there? • 0, 1, 2, or 3 • How is the operand location specified? • register, immediate, indirect, . . . • What type & size of operands are supported? • byte, int, float, double, string, vector. . . • What operations are supported? • basic operations: add, sub, mul, move, compare . . . • or also very complex operations?
Operands • How are operands designated? • fixed – always in the same place • by opcode – always the same for groups of instructions • by a field in the instruction – requires decode first • What is the format of the data? • binary • character • decimal (packed and unpacked) • floating-point – IEEE 754 (others used less and less) • size – 8-, 16-, 32-, 64-, 128-bit, • or vectors of above types and sizes • What is the influence on the ISA (= Instruction-Set Architecture)? ACA H.Corporaal
Operand Locations ACA H.Corporaal
Classifying ISAs Accumulator (before 1960): 1 address add A acc ¬ acc + mem[A] Stack (1960s to 1970s): 0 address add tos ¬ tos + next Memory-Memory (1970s to 1980s): 2 address add A, B mem[A] ¬ mem[A] + mem[B] 3 address add A, B, C mem[A] ¬ mem[B] + mem[C] Register-Memory (1970s to present): 2 address add R1, A R1 ¬ R1 + mem[A] load R1, A R1 ¬ mem[A] Register-Register (Load/Store) (1960s to present): 3 address add R1, R2, R3 R1 ¬ R2 + R3 load R1, R2 R1 ¬ mem[R2] store R1, R2 mem[R1] ¬ R2 ACA H.Corporaal
Evolution of Architectures Single Accumulator (EDSAC 1950) Accumulator + Index Registers (Manchester Mark I, IBM 700 series 1953) Separation of Programming Model from Implementation High-level Language Based Concept of a Processor Family (B5000 1963) (IBM 360 1964) General Purpose Register Machines Complex Instruction Sets Load/Store Architecture (CDC 6600, Cray 1 1963-76) (Vax, Intel 8086 1977-80) RISC (Mips,Sparc,88000,IBM RS6000, . . .1987+)
Addressing Modes • Types • Register – data in a register • Immediate – data in the instruction • Memory – data in memory • Calculation of Effective Address • Direct – address in instruction • Indirect – address in register • Displacement – address = register or PC + offset • Indexed – address = register + register • Memory Indirect – address at address in register • Question: What is the influence on ISA? ACA H.Corporaal
Types of Addressing Mode (VAX) Addressing Mode Example Action 1. Register direct Add R4, R3 R4 <- R4 + R3 2. Immediate Add R4, #3 R4 <- R4 + 3 3. Displacement Add R4, 100(R1) R4 <- R4 + M[100 + R1] 4. Register indirect Add R4, (R1) R4 <- R4 + M[R1] 5. Indexed Add R4, (R1 + R2) R4 <- R4 + M[R1 + R2] 6. Direct Add R4, (1000) R4 <- R4 + M[1000] 7. Memory Indirect Add R4, @(R3) R4 <- R4 + M[M[R3]] 8. Autoincrement Add R4, (R2)+ R4 <- R4 + M[R2] R2 <- R2 + d 9. Autodecrement Add R4, (R2)- R4 <- R4 + M[R2] R2 <- R2 - d 10. Scaled Add R4, 100(R2)[R3] R4 <- R4 + M[100 + R2 + R3*d] • Studies by [Clark and Emer] indicate that modes 1-4 account for 93% of all operands on the VAX
Operations • Types • ALU – Integer arithmetic and logical functions • Data transfer – Loads/stores • Control – Branch, jump, call, return, traps, interrupts • System – O/S calls, virtual memory management • Floating point – Floating point arithmetic • Decimal – Decimal arithmetic (BCD: binary coded decimal) • String – moves, compares, search, etc. • Graphics – Pixel/vertex operations • Vector – Vector (SIMD) functions • more complex ones • Addressing • Which addressing modes for which operands are supported? ACA H.Corporaal
Relative Frequency of Control Instructions • Design hardware to handle branches quickly, since these occur most frequently
Frequency of Operand Sizeson 32-bit Load-Store Machines • For floating-point want good performance for 64 bit operands. • For integer operations want good performance for 32 bit operands • Recent architectures also support 64-bit integers
Instruction Encoding • Variable • Instruction length varies based on opcode and address specifiers • For example, VAX instructions vary between 1 and 53 bytes, while x86 instruction vary between 1 and 17 bytes. • Good code density, but difficult to decode and pipeline • Fixed • Only a single size for all instructions • For example MIPS, Power PC, Sparc all have 32 bit instructions • Not as good code density, but easier to decode and pipeline • Hybrid • Have multiple format lengths specified by the opcode • For example, IBM 360/370 • Compromise between code density and ease of decode
Instruction Encoding ACA H.Corporaal
Example: MIPS Operands mostly at fixed positions Fixed instruction size; few formats ACA H.Corporaal
Compilers and ISA • Compiler Goals • All correct programs compile correctly • Most compiled programs execute quickly • Most programs compile quickly • Achieve small code size • Provide debugging support • Multiple Source Compilers • Same compiler can compile different languages • Multiple Target Compilers • Same compiler can generate code for different machines • 'cross-compiler'
Compiler basics: trajectory Source program Preprocessor Compiler Error messages Assembler Library code Loader/Linker Object program ACA H.Corporaal
Compiler basics:structure / passes Source code Lexical analyzer token generation check syntax check semantic parse tree generation Parsing Intermediate code data flow analysis local optimizations global optimizations Code optimization code selection peephole optimizations Code generation making interference graph graph coloring spill code insertion caller / callee save and restore code Register allocation Sequential code Scheduling and allocation exploiting ILP Object code ACA H.Corporaal
:= id + id * id 60 Compiler basics: structure Simple compilation example position := initial + rate * 60 Lexical analyzer temp1 := intoreal(60) temp2 := id3 * temp1 temp3 := id2 + temp2 id1 := temp3 id := id + id * 60 Syntax analyzer Code optimizer temp1 := id3 * 60.0 id1 := id2 + temp1 Code generator movf id3, r2 mulf #60, r2, r2 movf id2, r1 addf r2, r1 movf r1, id1 Intermediate code generator ACA H.Corporaal
Designing ISA to Improve Compilation • Provide enough general purpose registers to ease register allocation ( at least 16) • Provide regular instruction sets by keeping the operations, data types, and addressing modes largely orthogonal • Provide primitive constructs rather than trying to map to a high-level language • Allow compilers to help make the common case fast
A "Typical" RISC • 32-bit fixed length instruction • Only few instruction formats • 32 32-bit GPRs (general purpose registers) • 3-address, reg-reg-reg / reg-imm-reg arithmetic instruction • Single address mode for load/store: base + displacement • no indirection • Simple branch conditions • Pipelined implementation • Separate Instruction and Data level-1 caches • Delayed branch ? ACA H.Corporaal
Comparison MIPS with 80x86 • How would you expect the x86 and MIPS architectures to compare on the following ? • CPI on SPEC benchmarks • Ease of design and implementation • Ease of writing assembly language & compilers • Code density • Overall performance • What other advantages/disadvantages are there to the two architectures?
Instruction Set ExtensionsSubword parallelism • Support graphics and multimedia applications • Intel’s MMX Technology (introduced in 1997) • Intel’s Internet Streaming SIMD Extensions (SSE – SSE4) • AMD’s 3DNow! Technology • Sun’s Visual Instruction Set • Motorola’s and IBM’s AltiVec Technology • These extensions improve the performance of • Computer-aided design • Internet applications • Computer visualization • Video games • Speech recognition ACA H.Corporaal
MMX Data Types MMX Technology supports operations on the following 64-bit integer data types: Packed byte (eight 8-bit elements) Packed word (four 16-bit elements) Packed double word (two 32-bit elements) Packed quad word (one 64-bit elements) ACA H.Corporaal
SIMD Operations • MMX Technology allows a Single Instruction to work on Multiple pieces of Data (SIMD) PADD[W]: Packed add word • In the above example, 4 parallel adds are performed on 16-bit elements • Most MMX instructions only require a single cycle A3 A2 A1 A0 B3 B2 B1 B0 A3+B3 A2+B2 A1+B1 A0+B0 ACA H.Corporaal
Saturating Arithmetic • Both wrap-around and saturating adds are supported • With saturating arithmetic, results that overflow/underflow are set to the largest/smallest value PADD[W]: Packed wrap-around add PADDUS[W]: Packed saturating add ACA H.Corporaal
Pack and Unpack Instructions • Pack and unpack instructions provide conversion between standard data types and packed data types PACKSS[DW]: Pack signed, with saturating, double to packed word ACA H.Corporaal
Multiply-Add Operations • Many graphics applications require multiply-accumulate operations • Vector Dot Products: a • b • Matrix Multiplies • Fast Fourier Transforms (FFTs) • Filter implementations PMADDWD: Packed multiply-add word to double ACA H.Corporaal
Vector Dot Product • A dot product on an 8-element vector can be performed using 9 MMX instructions • Without MMX 40 instructions are required 0 a0*c0+..+ a3*c3 0 a4*c4+..+ a7*c7 a0*c0+..+ a7*c7 ACA H.Corporaal
Packed Compare Instructions • Packed compare instructions allow a bit mask to be set or cleared • This is useful when images with certain qualities need to be extracted ACA H.Corporaal
MMX Instructions • MMX Technology adds 57 new instructions to the x86 architecture. • Some of these instructions include (b=byte;w=32-bit;d=64-bit) • PADD(b, w, d) Packed addition • PSUB(b, w, d) Packed subtraction • PCMPE(b, w, d) Packed compare equal • PMULLw Packed word multiply low • PMULHw Packed word multiply high • PMADDwd Packed word multiply-add • PSRL(w, d, q) Pack shift right logical • PACKSS(wb, dw) Pack data • PUNPCK(bw, wd, dq) Unpack data • PAND, POR, PXOR Packed logical operations ACA H.Corporaal
Application Without MMX With MMX Speedup Video 155.52 268.70 1.72 Image Processing 159.03 743.90 4.67 3D geometry 161.52 166.44 1.03 Audio 149.80 318.90 2.13 Overall 156.00 255.43 1.64 MMX Performance Comparison ACA H.Corporaal
MMX Technology Summary • MMX technology extends the Intel x86 architecture to improve the performance of multimedia and graphics applications. • It provides a speedup of 1.5 to 2.0 for certain applications. • MMX instructions are hand-coded in assembly or implemented as libraries to achieve high performance. • MMX data types use the x86 floating point registers to avoid adding state to the processor. • Makes it easy to handle context switches • Makes it hard to perform MMX and floating point instructions at the same time • Only increase the chip area by about 5%. ACA H.Corporaal
Questions on MMX • What are the strengths and weaknesses of MMX Technology? • How could MMX Technology potentially be improved? • How did the developers of MMX preserve backward compatibility with the x86 architecture? • Why was this important? • What are the disadvantages of this approach? • What restrictions/limitations are there on the use of MMX Technology? ACA H.Corporaal
Internet Streaming SIMD Extensions (SSE) • Help improve the performance of video and 3D applications • Are designed for streaming data, which is used once and then discarded. • 70 new instructions beyond MMX Technology • Adds 8 new 128-bit vector registers (XMM0 – XMM7) • Provide the ability to perform multiple floating point operations • Four parallel operations on 32-bit numbers • Reciprocal and reciprocal root instructions - normalization • Packed average instruction – Motion compensation • Provide data prefetch instructions • Make certain applications 1.5 to 2.0 times faster ACA H.Corporaal
Beyond SSE • SSE2: SIMD on any data type from 8-bit int to 64-bit double, using XMM vector registers • SSE4: dot-product operation • AVX (Advanced Vector Extensions): 2011 • 16 256-bit vector registers, YMM0-YMM15 • later extended to 512 and 1024 bits • 3 operand instructions (instead of 2, with one implicit register operand) • 2011: in Intel Sandy Bridge and AMD Bulldozer architectures ACA H.Corporaal