Download
1 / 18
180 likes | 456 Vues
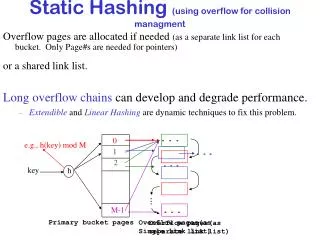
. Overflow pages(as separate link list). Overflow pages(as Single link list). Static Hashing (using overflow for collision managment. Overflow pages are allocated if needed (as a separate link list for each bucket. Only Page#s are needed for pointers). or a shared link list.

E N D
. . . Overflow pages(as separate link list) Overflow pages(as Single link list) Static Hashing (using overflow for collision managment Overflow pages are allocated if needed (as a separate link list for each bucket. Only Page#s are needed for pointers) or a shared link list. Long overflow chains can develop and degrade performance. • Extendible and LinearHashing are dynamic techniques to fix this problem. 0 e.g., h(key) mod M 1 2 key h M-1 Primary bucket pages
Other Static Hashing overflow handling methods Overflow can be handled by open addressing also (more commonly used for internal hash tables where a bucket is a allocation of main memory. In Open Addressing, upon collision, search forward in the bucket sequence for the next open record slot. 0 1 2 3 4 5 6 rec e.g., h(key) mod M Then to search, apply h. If not found, search sequentially ahead until found (circle around to search start point)! rec rec rec key h h(rec_key)=1 Collision! 2? no 3? yes rec bucket pages
Other overflow handling methods Overflow can be handled by re-hashing also. In re-hashing, upon collision, apply next hash function from a sequence of hash functions.. Then to search, apply h. If not found, apply next hash function until found or list exhausted. 0 1 2 3 4 5 6 h0(key) rec rec rec then h1 then h2 ... h rec These methods can be combined also. bucket pages
Extendible Hashing Idea: Use directory of pointers to buckets, • split just the bucket that overflowed • double the directory when needed Directory is much smaller than file, so doubling it is cheap. Only one page of data entries is split. Nooverflowpage! Trick lies in how hash function is adjusted!
LOCAL DEPTH 2 Bucket A 16* 4* 12* 32* 2 2 Bucket B 00 5* 1* 21* 13* 01 2 10 Bucket C 10* 11 2 DIRECTORY Bucket D 15* 7* 19* Exampleblocking factor(bfr)=4(# entries per bucket) GLOBAL DEPTH = gd To find the bucket for a new key value, r, take just the last global depth bits of h(r), not all of it! (last 2 bits in this example) (for simplicity we let h(r)=r here) E.g., h(5)=5=101binary thus it's in bucket pointed in the directory by 01. Local depth of a bucket: # of bits used to determine if an entry belongs to bucket Global depth of directory: Max # of bits needed to tell which bucket an entry belongs to (= max of local depths) DATA PAGES Apply hash function, h, to key value, r Follow pointer of last 2 bits of h(r). Insert:If bucket is full, splitit (allocate 1 new page, re-distribute over those 2 pages).
LOCAL DEPTH 1 Bucket A 4* Examplehow did we get there? GLOBAL DEPTH = gd 1 0 Bucket B 0 1 First insert is 4: h(4) = 4 = 100binary in bucket pointed in the directory by 0. DIRECTORY DATA PAGES
LOCAL DEPTH 1 Bucket A 16* 4* 12* 32* Example GLOBAL DEPTH = gd 1 1 Bucket B 0 1* 1 Insert: 12, 32, 16 and 1 h(12) = 12 = 1100binary in bucket pointed in the directory by 0. h(32) = 32 = 10 0000binary in bucket pointed in the directory by 0. DIRECTORY h(16) = 16 = 1 0000binary in bucket pointed in the directory by 0. h(1) = 1 = 1binary in bucket pointed in the directory by 1. DATA PAGES
LOCAL DEPTH 1 Bucket A 16* 4* 12* 32* Example GLOBAL DEPTH = gd 1 1 Bucket B 0 5* 21* 13* 1* 1 Insert: 5, 21 and 13 h(5) = 5 = 101binary in bucket pointed in the directory by 1. h(21) = 21 = 1 0101binary in bucket pointed in the directory by 1. DIRECTORY h(13) = 13 = 1101binary in bucket pointed in the directory by 1. DATA PAGES
0 0 2 1 0 Bucket C 10* 1 1 LOCAL DEPTH 2 Bucket A 16* 4* 12* 32* Example GLOBAL DEPTH = gd 2 1 9th insert: 10 h(10) = 10 = 1010binary in bucket pointed in the directory by 0. Collision! Bucket B 0 5* 21* 13* 1* 1 Split bucket A into A and C. Double directory (by copying what is there DIRECTORY and adding a bit on the left). Reset one pointer. DATA PAGES Redistribute values among A and C (if necessary Not necessary this time since all 2's bits correct: 4 = 100 12 = 1100 32 =100000 16 = 10000 10 = 1010
2 0 0 2 1 0 Bucket C 10* 1 1 2 1 Bucket D 15* 7* 19* DATA PAGES LOCAL DEPTH 2 Bucket A 16* 4* 12* 32* Example GLOBAL DEPTH = gd Inserts: 15, 7 and 19 2 1 h(15) = 15 = 1111binary Bucket B 0 5* 21* 13* 1* h(15) = 7 = 111binary 1 h(19) = 15 = 1 0011binary DIRECTORY Split bucket B into B and D. No need to double directory because the local depth of B is less than the global depth. Reset one pointer Redistribute values among B and D (if necessary, not necessary this time). Reset local depth of B and D
3 3 1 0 00 00 01 01 1 0 1 0 10 10 11 11 0 1 3 Bucket E 4* 12* (`split image' of Bucket A) Split A. Double directory and reset 1 pointer. Insert h(20)=20=10100 Bucket pointed to by 00 is full! 2 LOCAL DEPTH Redistribute contents of A Bucket A 4* 12* 32* 16* GLOBAL DEPTH 2 2 Bucket B 5* 21* 13* 1* 2 Bucket C 10* 2 Bucket D 15* 7* 19*
Points to Note • 20 = binary 10100. Last 2 bits (00) tell us r belongs in either A or A2, but not which one. Last 3 bits needed to tell which one. • Local depth of a bucket: # of bits used to determine if an entry belongs to this bucket. • Global depth of directory: Max # of bits needed to tell which bucket an entry belongs to (= max of local depths) • When does bucket split cause directory doubling? • Before insert, local depth of bucket = global depth. Insert causes local depth to become > global depth; directory is doubled by copying it over and `fixing’ pointer to split image page. • Use of least significant bits enables efficient doubling via copying of directory!)
Comments on Extendible Hashing • If directory fits in memory, equality search answered with one disk access; else two. • Directory grows in spurts, and, if the distribution of hash values is skewed, directory can grow large. • Multiple entries with same hash value cause problems! • Delete: If removal of data entry makes bucket empty, can be merged with its `split image’. • As soon as each directory element points to same bucket as its (merged) split image, can halve directory.
Linear Hash File Starts with M buckets (numbered 0, 1, ..., M-1 and initial hash function, h0=modM (or more general, h0(key)=h(key)modM for any hash ftn h which maps into the integers Use Chaining to shared overflow-pages to handle overflows. At the first overflow, split bucket0 into bucket0 and bucketM and rehash bucket0 records using h1=mod2M. Henceforth if h0 yields value0, rehash using h1=mod2M At the next overflow, split bucket1 into bucket1 and bucketM+1 and rehash bucket1 records using h1=mod2M. Henceforth if h0 yields value1, use h1 ... When all of the original M buckets have been split (M collisions), then rehash all overflow records using h1. Relabel h1 as h0, (discarding the old h0 forever) and start a new "round" by repeating the process above for all future collisions (i.e., now there are buckets 0,...,(2M-1) and h0 = MOD2M). To search for a record, let n = number of splits so far in the given round, if h0(key) is not greater than n, then use h1, else use h0.
Bucket pg 0 45 1 99 2 23 3 78 4 98 Insert h0(8)mod5(8)=3 Insert h0(27)mod5(27)=2 C! 00,5, mod10rehash 0; n=0 27|JONES |MHD |MN 8|SINGH |FGO |ND Insert h0(15)mod5(15)=0n 15|LOWE |ZAP |ND h1(15)mod10(15)=5 Insert h0(31)mod5(31)=1 ! 33,8; mod10rehash 3; n=3 Insert h0(32)mod5(32)=2 ! 11,6, mod10rehash 1; n=1 Insert h0(39)mod5(39)=4 ! 22,7; mod10rehash 2; n=2 Insert h0(36)mod5(36)=1 ! 44,9; mod10rehash 4; n=4! 36|SCHOTZ|CORN |IA 31|ROSE |MIAME|OH 32|FARNS |BEEP |NY 39|TULIP |DERLK|IN | | | 21 15|LOWE |ZAP |ND | | | Linear Hash ex. M=5 23 22|ZHU |SF |CA 25|CLAY |OUTBK|NJ 45 | | | 5 21 6 101 | | | 7 104 8 105 33|GOOD |GATER|FL | | | 02|BAID |NY |NY 78 9 107 8|SINGH |FGO |ND | | | 14|THAISZ|KNOB |NJ 98 24|CROWE |SJ |CA 11|BROWN |NY |NY 99 21|BARBIE|NY |NY | | | 101 | | | | | | 104 | | | | | | 105 | | | | | | 107 | | | 27|JONES |MHD |MN 39|TULIP |DERLK|IN OF 36|SCHOTZ|CORN |IA 32|FARNS |BEEP |NY 31|ROSE |MIAME|OH
Bucket pg 0 45 1 99 2 23 3 78 4 98 Insert h0(10)mod10(10)=0 10|RADHA |FGO |ND | | | 25|CLAY |OUTBK|NJ 21 15|LOWE |ZAP |ND | | | LHex. 2nd rnd M=10h0mod10 23 22|ZHU |SF |CA 10|RADHA |FGO |ND 45 | | | 5 21 h027=7 | | | 6 101 7 104 h032=2 Collision! rehash mod20 8 105 | | | 33|GOOD |GATER|FL 02|BAID |NY |NY 78 9 107 h039=9 | | | 10 109 11 110 h031=1 Collision! rehash mod20 14|THAISZ|KNOB |NJ 98 h036=6 24|CROWE |SJ |CA 11|BROWN |NY |NY | | | 99 21|BARBIE|NY |NY | | | 101 ETC. | | | | | | | | | 104 110 | | | | | | OF 8|SINGH |FGO |ND | | | 105 27|JONES |MHD |MN | | | 32|FARNS |BEEP |NY | | | 107 39|TULIP |DERLK|IN | | | 31|ROSE |MIAME|OH | | | 109 36|SCHOTZ|CORN |IA | | |
Summary • Hash-based indexes: best for equality searches, cannot support range searches. • Static Hashing can lead to performance degradation due to collision handling problems. • Extendible Hashing avoids performance problems by splitting a full bucket when a new data entry is to be added to it. (Duplicates may require overflow pages.) • Directory to keep track of buckets, doubles periodically. • Can get large with skewed data; additional I/O if this does not fit in main memory.
v1 v2 v3 v4 v5 . . . vn Distribution skew . . . v1 v2 v3 v4 v5 . . . vn Count skew . . . v1 v2 v3 v4 v5 . . . vn Dist & Count skew count count count values values values Summary • Linear Hashing avoids directory by splitting buckets round-robin, and using overflow pages. • Overflow pages not likely to be long. • Duplicates handled easily. • Space utilization could be lower than Extendible Hashing, since splits not concentrated on `dense’ data areas. • skewed occurs when the hash values of the data entries are not uniform!


















