Fabric Management
280 likes | 521 Vues
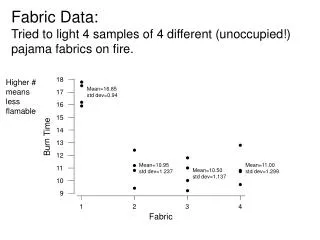
Fabric Management. Massimo Biasotto, Enrico Ferro – INFN LNL. Legnaro CMS Farm Layout. 2001 40 Nodes 4000 SI95 9 TB. 1. 8. 2. 2001-2-3 up to 190 Nodes. N 24. N 24. N1. N 24. N1. N1. F ast E th. F ast E th. F ast E th. SWITCH. SWITCH. SWITCH. To WAN 34 Mbps 2001

Fabric Management
E N D
Presentation Transcript
Fabric Management Massimo Biasotto, Enrico Ferro – INFN LNL
Legnaro CMS Farm Layout 2001 40 Nodes 4000 SI95 9 TB 1 8 2 2001-2-3 up to 190 Nodes N24 N24 N1 N24 N1 N1 FastEth FastEth FastEth SWITCH SWITCH SWITCH To WAN 34 Mbps 2001 155 Mbps 2002 32 – GigaEth 1000 BT 2001 11 Servers 3.3 TB S16 S1 S11 Sx – Disk Server Node Dual PIII – 1 GHz Dual PCI (33/32 – 66/64 512 MB 4x75 GB Eide Raid disks (exp up to 10) 1x20 GB disk O.S. Nx – Computational Node Dual PIII – 1 GHz 512 MB 3x75 GB Eide disk + 1x20 GB for O.S.
Datagrid • Project structured in many “Work Packages”: • WP1: Workload Management • WP2: Data Management • WP3: Monitoring Services • WP4: Fabric Management • WP5: Mass Storage Management • WP6: Testbed • WP7: Network • WP8-10: Applications • 3 year project (2001-2003). • Milestones: month 9 (Sept 2001), month 21 (Sept 2002), month 33 (Sept 2003)
Overview • Datagrid WP4 (Fabric Management) overview • WP4 software architecture • WP4 subsystems and components • Installation and software management • Current prototype: LCFG • LCFG architecture • LCFG configuration and examples
WP4 overview • Partners: CERN, INFN (Italy), KIP (Germany), NIKHEF (Holland), PPARC (UK), ZIB (Germany) • WP4 website:http://hep-proj-grid-fabric.web.cern.ch/hep-proj-grid-fabric/ • Aims to deliver a computing fabric comprised of all the necessary tools to manage a centre providing Grid services on clusters of thousands of nodes
WP4 structure • WP activity divided in 6 main ‘tasks’ • Configuration management (CERN + PPARC) • Resource management (ZIB) • Installation & node management (CERN + INFN + PPARC) • Monitoring (CERN + INFN) • Fault tolerance (KIP) • Gridification (NIKHEF) • Overall WP4 functionality structured into units called ‘subsystems’, corresponding to the above tasks
Architecture overview • WP4 architectural design document (draft): • http://hep-proj-grid-fabric.web.cern.ch/hep-proj-grid-fabric/architecture/eu/default.htm • Still work in progress: open issues that need further investigation • Functionalities classified into two main categories: • User job control and management • handled by Gridification and Resource Management subsystems • Automated system administration • handled by Configuration Mgmt, Installation Mgmt, Fabric Monitoring and Fault Tolerance subsystems
ResourceBroker(WP1) Other Wps Grid InfoServices(WP3) WP4 subsystems Grid User FabricGridification Data Mgmt(WP2) Monitoring &Fault Tolerance ResourceManagement Local User Farm A (LSF) Farm B (PBS) Grid DataStorage(WP5) ConfigurationManagement (Mass storage, Disk pools) Installation &Node Mgmt - provides the tools for gathering and storing performance, functional and environmental changes for all fabric elements; - central measurement repository provides health and status view of services and resources; - fault tolerance correlation engines detect failures and trigger recovery actions. Architecture overview - Interface between Grid-wide services and local fabric; - Provides local authentication, authorization and mapping of grid credentials. - provides transparent access to different cluster batch systems; - enhanced capabilities (extended scheduling policies, advanced reservation, local accounting). - provides the tools to install and manage all software running on the fabric nodes; - bootstrap services; software repositories; Node Management to install, upgrade, remove and configure software packages on the nodes. - provides a central storage and management of all fabric configuration information; - central DB and set of protocols and APIs to store and retrieve information.
Resource Management diagram Accepts job requests, verifies credentials and schedules the jobs Assigns resources to incoming job requests, enhancing fabric batch systems capabilities (better load balancing, adapts to resource failures, considers maintenance tasks) Stores static and dynamic information describing the states of the RMS and its managed resources proxies provide uniform interface to underlying batch systems (LSF, Condor, PBS)
MR MSA Monitoring & Fault Tolerance diagram Monitoring User Interface - graphical interface to the Measurement Repository Human operator host Measurement Repository - stores timestamped information; it consists of local caches on the nodes and a central repository server MS MS MS MUI Fault Tolerance Correlation Engine - processes measurements of metrics stored in MR to detect failures and possibly decide recovery actions Central repository Service master node Data Base MR server FTCE Actuator Dispatcher - used by FTCE to dispatch Fault Tolerance Actuators; it consists of an agent controlling all actuators on a local node Local node cache FTCE AD Control flow Fault Tolerance Actuator - executes automatic recovery actions Data flow Monitoring Sensor Agent - collects data from Monitoring Sensors and forwards them to the Measurement Repository FTA MS Monitoring Sensor - performs measurement of one or several metrics;
Configuration Management diagram Cache Configuration Manager: downloads node profiles from CDB and stores them locally Configuration Database: stores configuration information and manages modification and retrieval access Configuration Database Client Node Local Process Cache Configuration Manager A P I High Level Description Low Level Description
Configuration DataBase Low LevelDescription High LevelDescription cmsserver1 /etc/exports /app cmsnode1, cmsnode2, .. All computing nodes of CMS Farm #3 use cmsserver1 as Application Server cmsnode3 /etc/fstab cmsserver1:/app /app nfs.. cmsnode2 /etc/fstab cmsserver1:/app /app nfs.. cmsnode1 /etc/fstab cmsserver1:/app /app nfs..
Installation Management diagram Software Repository - central fabric store for Software Packages Bootstrap Service - service for initial installation of nodes Node Management Agent - manages installation, upgrade, removal and configuration of software packages
Monitoring Local Repository Config DB Local Cache Monitoring Local Repository Monitoring Local Repository Config DB Local Cache Config DB Local Cache Distributed design • Distributed design in the architecture, in order to ensure scalability: • individual nodes as much autonomous as possible • local instances of almost every subsystem: operations performed locally where possible • central steering for control and collective operations Monitoring Central Repository Central Config DB
Scripting layer • All subsystems are tied together using a high level ‘scripting layer’: • allows administrators to code and automate complex fabric-wide management operations • coordination in execution of user jobs and administrative task on the nodes • scripts can be executed by Fault Tolerance subsystem to automate corrective actions • All subsystems provide APIs to control their components • Subsystems keep their independence and internal coherence: the scripting layer only aims at connecting them for building high-level operations
Maintenance tasks • Control function calls to NMA are known as ‘maintenance tasks’ • non intrusive: can be executed without interfering with user jobs (e.g. cleanup of log files) • intrusive: for example kernel upgrades or node reboots • Two basic node states from the administration point of view • production: node is running user jobs or user services (e.g. NFS server). Only non intrusive tasks can be executed • maintenance: no user jobs or services. Both intrusive and non intrusive tasks can be executed • Usually a node is put into maintenance status only when it is idle, after draining the job queues or switching the services to another node. But there can be exceptions to immediately force the status change.
Installation & Software Mgmt Prototype • The current prototype is based on a software tool originally developed by the Computer Science Department of Edinburgh University: LCFG (Large Scale Linux Configuration)http://www.dcs.ed.ac.uk/home/paul/publications/ALS2000/ • Handles automated installation, configuration and management of machines • Basic features: • automatic installation of O.S. • installation/upgrade/removal of all (rpm-based) software packages • centralized configuration and management of machines • extendible to configure and manage custom application software
<inet> <allow cfg:template="allow_$ tag_$ daemon_$"> <allow_RECORD cfg:name="telnet"> <allow>192.168., 192.135.30.</allow> </allow_RECORD> ..... </auth> <user_RECORD cfg:name="mickey"> <userhome>/home/MickeyMouseHome</userhome> <usershell>/bin/tcsh</usershell> </user_RECORD> XML profiles Config files +inet.services telnet login ftp +inet.allow telnet login ftp sshd +inet.allow_telnet ALLOWED_NETWORKS +inet.allow_login ALLOWED_NETWORKS +inet.allow_ftp ALLOWED_NETWORKS +inet.allow_sshd ALL +inet.daemon_sshd yes ..... +auth.users myckey +auth.userhome_mickey /home/mickey +auth.usershell_mickey /bin/tcsh LCFG Config Files Read Profile Load Profile HTTP rdxprof ldxprof /etc/shadow Profile Generic /etc/group Object Make XML Profile Component /etc/passwd .... mickey:x:999:20::/home/Mickey:/bin/tcsh .... Web Server Local cache /etc/services XML Profile LCFG Objects /etc/inetd.conf Profile /etc/hosts.allow in.telnetd : 192.168., 192.135.30. in.rlogind : 192.168., 192.135.30. in.ftpd : 192.168., 192.135.30. sshd : ALL Object Client nodes Server inet auth LCFG diagram Abstract configuration parameters for all nodes stored in a central repository A collection of agents read configuration parameters and either generate traditional config files or directly manipulate various services
LCFG Config Files Read Profile Load Profile HTTP rdxprof ldxprof Profile Generic Object Make XML Profile Component Web Server Local cache XML Profile LCFG Objects Client nodes Server LCFG: future development Current Prototype Future Evolution Cache HTTP Cache API API Manager Manager Configuration Database Profile Generic Object Component Web Server XML Profile Cache LCFG Objects
LCFG configuration (I) • Most of the configuration data are common for a category of nodes (e.g. diskservers, computing nodes) and only a few are node-specific (e.g. hostname, IP-address) • Using the cpp preprocessor it is possible to build a hierarchical structure of config files containing directives like #define, #include, #ifdef, comments with /* */, etc... • The configuration of a typical LCFG node looks like this: #define HOSTNAME pc239 /* Host specific definitions */ #include "site.h" /* Site specific definitions */ #include "linuxdef.h" /* Common linux resources */ #include "client.h" /* LCFG client specific resources */
LCFG configuration (II) From "site.h" #define LCFGSRV grid01 #define URL_SERVER_CONFIG http://grid01/lcfg #define LOCALDOMAIN .lnl.infn.it #define DEFAULT_NAMESERVERS 192.135.30.245 [...] From "linuxdef.h" update.interfaces eth0 update.hostname_eth0 HOSTNAME update.netmask_eth0 NETMASK [...] From "client.h" update.disks hda update.partitions_hda hda1 hda2 update.pdetails_hda1 free / update.pdetails_hda2 128 swap auth.users mickey auth.usercomment_mickey Mickey Mouse auth.userhome_mickey /home/Mickey [...]
LCFG: configuration changes • Server-side: when the config files are modified, a tool (mkxprof) recreates the new xml profile for all the nodes affected by the changes • this can be done manually or with a daemon periodically checking for config changes and calling mkxprof • mkxprof can notify via UDP the nodes affected by the changes • Client-side: another tool (rdxprof) downloads the new profile from the server • usually activated by an LCFG object at boot • can be configured to work as • daemon periodically polling the server • daemon waiting for notifications • started by cron at predefined times
LCFG: what’s an object? • It's a simple shell script (but in future it will probably be a perl script) • Each object provides a number of “methods” (start, stop, reconfig, query, ...) which are invoked at appropriate times • A simple and typical object behaviour: • Started by profile object when notified of a configuration change • Loads its configuration from the cache • Configures the appropriate services, either translating config parameters into a traditional config file or directly controlling the service (e.g. starting a daemon with command-line parameters derived from configuration).
LCFG: custom objects • LCFG provides the objects to manage all the standard services of a machine: inet, syslog, auth, nfs, cron, ... • Admins can build new custom objects to configure and manage their own applications: • define your custom “resources” (configuration parameters) to be added to the node profile • include in your script the object “generic”, which contains the definition of common function used by all objects (config loading, log, output, ...) • overwrite the standard methods (start, stop, reconfig, ...) with your custom code • for simple objects usually just a few lines of code
LCFG: Software Packages Management • Currently it is RedHat-specific: heavily dependent on the RPM tool • The software to install is defined in a file on the server containing a list of RPM packages (currently not yet merged in the XML profile) • Whenever the list is modified, the required RPM packages are automatically installed/upgraded/removed by a specific LCFG object (updaterpms), which is started at boot or when the node is notified of the change
Root Image complete with LCFG environment mounted via NFS Start object “install”: disk partitioning, network,... installation of required packages copy of LCFG configuration reboot Load minimal config data via DHCP: IP Address, Gateway, LCFG Config URL Load complete configuration via HTTP LCFG: node installation procedure LCFG Config Files XML Profiles IP address Config URL DHCP Server LCFG Server WEB Server After reboot LCFG objects complete the node configuration First boot via floppy or via network Initialization script starts Root Imagewith LCFGenvironment Software Packages NFS Server Software Repository Client Node
LCFG: summary • Pros: • In Edinburgh it has been used for years in a complex environment, managing hundreds of nodes • Supports the complete installation and management of all the software (both O.S. and applications) • Extremely flexible and easy to customize • Cons: • Complex: steep learning curve • Prototype: the evolution of this tool is not clear yet • Lack of user-friendly tools for the creation and management of configuration files: errors can be very dangerous!
Future plans • Future evolution not clearly defined: it will depend also on results of forthcoming tests (1st Datagrid milestone) • Integration of current prototype with Configuration Management components • Config Cache Manager and API released ad prototypes but not yet integrated with LCFG • Configuration DataBase • complete definition of node profiles • user-friendly tools to access and modify config information • Development of still missing objects • system services (AFS, PAM, ...) • fabric software (grid sw, globus, batch systems, ...) • application software (CMS, Atlas, ...) in collaboration with people from experiments