Download

1 / 17
180 likes | 344 Vues
Generalized Probabilistic LR Parsing of Natural Language (Corpora) with Unification-Based Grammar. Ted Briscoe, John Carroll University of Cambridge. Table of contents. Wide-coverage Parsing of Natural Language Probabilistic Approaches to Parsing

E N D
Generalized Probabilistic LR Parsing of Natural Language (Corpora) with Unification-Based Grammar Ted Briscoe, John Carroll University of Cambridge
Table of contents • Wide-coverage Parsing of Natural Language • Probabilistic Approaches to Parsing • LR Parsing in a Unification-Based Grammar Framework • Building LR Parse Tables for Large NL Grammars • Interactive Incremental Deterministic Parsing • Non-deterministic LR Parsing with Unification Grammars • LR Parsing with Probabilistic Disambiguation • Parsing LDOCE Noun Definitions • Conclusions POSTECH CS KLE Lab.
Wide-coverage Parsing of Natural Language • Goal • develop a practical parser capable of returning probabilistically highly ranked analyses • recover a semantically and pragmatically appropriate syntactic analysis capable of supporting semantic interpretation on the basis of minimal training and manual modification • ANLT (Alvey Natural Language Tools) system • wide-coverage lexical, morphological, and syntactic analysis system for English (Briscoe et al. 1987) • able to assign the correct parse to a high proportion of English noun phrases • English lexicon of 40,000 lexemes, Unification grammar containing 700 phrase structure rules • correct analysis to 96.8% : corpus of 10,000 noun phrases POSTECH CS KLE Lab.
Probabilistic Approaches to Parsing • Baker (1982) • Baum-Welch re-estimation can be extended to CFGs in CNF • Kupiec (1991) • extends Baum-Welch re-estimation to arbitrary CFGs (non-CNF) • Fujisaki et al. (1989) • Viterbi algorithm can be used in conjunction with the CYK algorithm and a CFG in CNF • 7,550 CFG rules on a corpus of 4,206 sentences • assign probabilities to each CF rule using all possible analyses POSTECH CS KLE Lab.
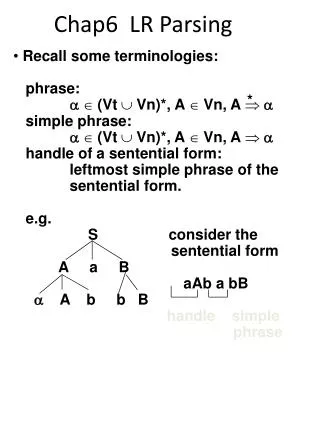
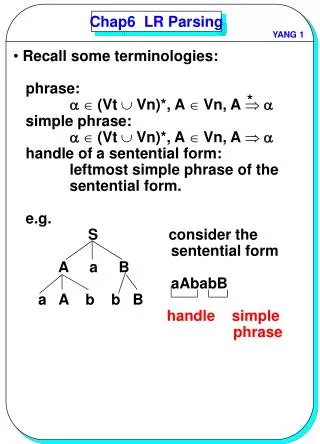
Probabilistic Approaches to Parsing (cont’d) • Problems with PCFG • wide-coverage CFGs : very large difficulty to develop consistent grammar computational intractability to parse • leads to complications distinguishing the probability of different derivation Figure 1 : a) = 0.0036, b) = c) = 0.09, d) = e) = 0.09 • will not model the context dependence of rule use NP : as a pronoun in subject position than elsewhere Figure 1 : a), f) POSTECH CS KLE Lab.
LR Parsing in a Unification-Based Grammar Framework • Control information of LR parser is encoded as a parse table • Parser table defines a finite-state automaton • Rows : parse states • Columns : terminal and non-terminal symbols of the grammar • ANLT object grammar formalism (Unification-based Grammar) • notational variant of Definite Clause Grammar 예) [N -, V +, BAR 2, PER x, PLU y, VFORM z] → [N +, V -, BAR 2, PER x, PLU y, CASE Nom] [N -, V +, BAR 1, PER x, PLU y, VFORM z] corresponding to S → NP VP • In Tomita’s LR parsing framework, each rule must be manually converted into a rule of the following form Vb[BAR 2, PER x, PLU y, VFORM z] → Nn[BAR 2,PER x,PLU y,CASE Nom] Vb[BAR 1,PER x,PLU y,VFORM z] POSTECH CS KLE Lab.
LR Parsing in a Unification-Based Grammar Framework (cont’d) • Constructing a CF Backbone from a Unification Grammar • A backbone grammar rule A unification grammar rule ← generally one-to-one mapping → • Algorithm : Section 3.2 • Figure 3 : Corresponding loosely S → NP VP, NP, Vi, VP → Vt NP • Step 1: create the disjoint-set (Figure 4) • Step 2: create backbone grammar rule using Figure 4 (Figure 5) • ETC • gab, [NULL +] • extra rule is added for expanding the gap category to the null string • A rule containing Kleene star is treated as two rules (coorporation) • Figure 6 • Advantages • computationally tractable for realistic sized grammar • safe for inconsistency POSTECH CS KLE Lab.
Building LR Parse Tables for Large NL Grammars • The backbone grammar from the ANLT grammar is large • almost 500 categories, more than 1,600 productions • Algorithm • Constructing the LR(0) sets of items • Computing the LALR(1) lookaheads for each item • LR(1) closure operation by Aho is too expensive to be practicable • Kristensen and Madsen(1981) - “Methods for computing LALR(K) lookahead” - partially computed lookahead sets can be cached • Constructing the parse table • 150,000 goto entries (nonterminal - state pairs) • 440,000 shift actions (terminal - state pairs) • 670,000 reduce actions (terminal - rule number pairs) • In 2,200 states (of the 3,710 states) • 230,000 shift-reduce conflicts • 220,000 reduce-reduce conflicts POSTECH CS KLE Lab.
Building LR Parse Tables for Large NL Grammars (cont’d) • Parse table for the ANLT grammar • approximately 360 Kbytes of memory (2.3bits per action) • lists, bit-vector ... • able to detect failures as soon as theoretically possible • more than twice the size of Tomita’s grammar for Japanese (Table 1) • If applying to large NL grammars • Tomita’s grammars : the table size grows rapidly • ANLT grammars : the table size is still quite manageable • timing for the ANLT grammar fall in the expected region (Table 2) POSTECH CS KLE Lab.
Interactive Incremental Deterministic Parsing • The Interactive LR Parsing System • ask the user for a decision at each choice point during the parse • Preterminal delaying (Shieber 1983) • to avoid asking the user about lexical ambiguity • assignment of preterminal to a lexical item is delayed until the lexical is used in a reduction • enter a state corresponding to the union of states of individual lexical (ex) That problem is important : NP → DET NOM That problems are difficult to solve is important : S → COMP S • In order not to overload the user with spurious choices concerning local ambiguities • parser pursue each option in a limited breadth-first fashion • request help with analysis paths that remain active • Table 3 : show the reduction in user interaction achieved by increasing the amount of lookahead POSTECH CS KLE Lab.
Interactive Incremental Deterministic Parsing (cont’d) • Figure 7 : show the system parsing a phrase with a four-choice lookahead • Figure 8 : summarize the amount of interaction for parsing 150 LDOCE noun definitions with the ANLT grammar • parse histories are automatically stored and used to derive the probability information • Advantages • guaranteed to be computationally tractable • constructing a disambiguated training corpus POSTECH CS KLE Lab.
Non-deterministic LR Parsing with Unification Grammars • For use with stable grammars for batch parsing of large bodied of text • Parser is driven by the LALR(1) state table computed from the backbone grammar • Not associating probabilities with CFG rules, but with an LR parse table directly → more sensitive to parse context • 예) ‘He loves her’ using Grammar 1 NP → ProNP, (Vi, $) • Table 4 : compare those for the GDE chart parser, the semi-automatic, nondeterministic LR parser • Although the nondeterministic LR parser is faster than the chart parser, it often generates as little as a third the amount of garbage POSTECH CS KLE Lab.
LR Parsing with Probabilistic Disambiguation • Probabilistic LALR(1) parse table (Figure 9) • nondeterministic finite-state automaton • State encodes information about the left and right context of the current parse • During a reduction, the categories in the stack are collected and unified • Actions having no prob. are ones that have not been utilized during the training phase • assign a smoothed probability • analogous to the Good-Turing technique • not associate probabilities with goto transitions a occurs r times, reestimate it with r* nr : # of n-grams that occur exactly r times N : total # of counts POSTECH CS KLE Lab.
LR Parsing with Probabilistic Disambiguation (cont’d) • <Example> ‘The winter holiday camp closed’ (Figure 10) • give the two possible complete derivations → whether the noun compound is left- or right- branching • PCFG cannot distinguish these two derivations • In step 8, a shift-reduce conflict occurs → a) right-branching : 4.6 x 10-8 → b) left-branching : 5.1 x 10-7 → table was constructed from parse histories with a preponderance of left-branching structures • In practice, take the geometric mean of the probabilities rather than their product to rank parse derivations → fewer rules POSTECH CS KLE Lab.
Parsing LDOCE Noun Definitions • Reason for choosing LDOCE • vocabulary is restricted (to approximately 2,000 morphemes) • average definition length is about 10 words (max of around 30) • each definition is independent (allowing to ignore ellipsis …) • Extracting 32,000 noun definition • normalizing to remove punctuation, font control information… • Training : 246 LDOCE noun definitions • further rules and lexical entries were created • takes an average of 15 seconds to resolve a single interaction with the parser • reparse the training corpus using constructed probabilistic parser (Figure 11) → within 3rd ranked analysis : 96% → 1st ranked analysis : 76% POSTECH CS KLE Lab.
Parsing LDOCE Noun Definitions (cont’d) • Testing : 55 LDOCE noun definitions (mean length 5.7) • 1st ranked : 41 cases (75%) • 2nd or 3rd ranked : 6 cases • within 3rd ranked analysis : 85% • not in the first three analysis : 8 cases • preference for local attachment of postmodifiers : 5 • preference for compounds : 1 • misanalysis of a single constituent : 2 • Figure 12 : show the analysis for the unseen definition of ‘affection’ POSTECH CS KLE Lab.
Conclusions • LR parse table with unification-based grammars define a more context-dependent and adequate probabilistic model of NL • LR parse table can be constructed automatically from unification-based grammars • Effective parse table construction for realistically sized ambiguous NL grammars POSTECH CS KLE Lab.