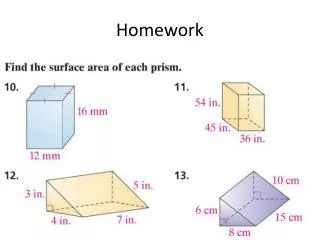
Homework
Homework. What’s important (i.e., this will be used in determining your grade): Finding features that make a difference You should expect to do some digging in the data Find a feature that requires manipulation of data


Homework
E N D
Presentation Transcript
Homework • What’s important (i.e., this will be used in determining your grade): • Finding features that make a difference • You should expect to do some digging in the data • Find a feature that requires manipulation of data • Reformatting of data to provide a more consistent feature (e.g., gender, profession) • Turn in a sample of your data file in ARFF format with the features you ended up using (5 instances only) • An instance is a row in the data file • It contains all attributes that you will have for an individual • Turn in a Weka log documenting the series of steps you used to arrive at your model • We want the experimentation that backs up your claims in the report • We will not be ranking your models (too hard for you to turn in enough so we can do that)
Lattitude • This assignment is in part about your ability to think and make decisions with the data. It is not cut and dried for you. • There are some 200 attributes • You will not want to experiment with all of them • Make some choices about which ones you think are important. These are your “hypotheses” • Then test whether your hypotheses were correct • Important: Remember the KDD presentation. • Size can often win out over importance of a feature • The authors normalized by length • E.g., for word frequency in the paper body vector, the abstract vector and the title vector, they normalized (divided) by length. Why? • You should think about normalization also.
Steps you should follow • Divide your data into training and testing • Use “Florida” for testing. Everything else for training • Don’t use Florida at all until you’re finished. • Do attribute selection first • Decide on the attributes you want to experiment with • Systematically measure their impact on accuracy (as in the greedy-stepwise algorithm and the KDD paper) • Use cross-validation on the training set to do this OR divide the training set further into training and augmentation validation • Make charts (using Excel or other chart making program). Weka’s charts are not clear. • With the set of attributes that you determine are good, now run twice, once with Bayesian Nets and once with Decision Trees. Note linear regression only appropriate when used with numbers, so only appropriate for donation amount. • Compare results using a chart • With the sets of attributes and machine learning program that you selected, vary the data • Run with increments of 10%, showing the accuracy. Describe what you see. • Choose the resulting model and run it on the test data (Florida) • Provide your accuracy results on the test