Minimax search algorithm
Minimax search algorithm For now, we assume that exhaustive search is possible. Generate the entire game tree. Assume it has depth d . For each terminal state, apply the payoff function to get its score.


Minimax search algorithm
E N D
Presentation Transcript
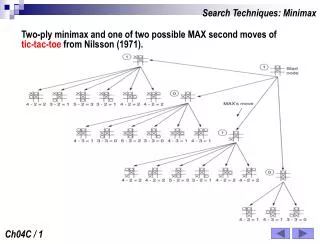
Minimax search algorithm For now, we assume that exhaustive search is possible. • Generate the entire game tree. Assume it has depth d. • For each terminal state, apply the payoff function to get its score. • Back-up the scores at level d to assign a score to each node at level d-1. If level d is MAX's move, then select the best score from the node's children. If level d is MIN's move, then select the worst score from the node's children. • Backup the scores all the way up the tree, until the root node gets to choose the maximum score among its children. This is the minimax decision that determines the best move to make!
The Evaluation Function • If we do not reach the end of the game how do we evaluate the payoff of the leaf states? • Use a static evaluation function. • A heuristic function that estimates the utility of board positions. • Desirable properties • Must agree with the utility function • Must not take too long to evaluate • Must accurately reflect the chance of winning • An ideal evaluation function can be applied directly to the board position. • It is better to apply it as many levels down in the game tree as time permits
Evaluation Function for Chess • Relative material value • Pawn = 1, knight = 3, bishop = 3, rook = 5, queen = 9 • Good pawn structure • King safety
Revised Minimax Algorithm For the MAX player • Generate the game as deep as time permits • Apply the evaluation function to the leaf states • Back-up values • At MIN ply assign minimum payoff move • At MAX ply assign maximum payoff move • At root, MAX chooses the operator that led to the highest payoff
Minimax Procedure • minimax(board, depth, type) • If depth = 0 return Eval-Fn(board) • else if type = max • cur-max = -inf • loop for b in succ(board) • b-val = minimax(b,depth-1,min) • cur-max = max(b-val,cur-max) • return cur-max • else (type = min) • cur-min = inf • loop for b in succ(board) • b-val = minimax(b,depth-1,max) • cur-min = min(b-val,cur-min) • return cur-min
Minimax max min max min
Minimax max 10 min 10 2 max 10 14 2 24 min 10 9 14 13 2 1 3 24
Problems with fixed depth search Most interesting games cannot be searched exhaustively, so a fixed depth cutoff must be applied. But this can cause problems ... Quiescence: If you arbitrarily apply the evaluation function at a fixed depth, you might miss a huge swing that is about to happen. The evaluation function should only be applied to quiescent (stable) positions. (Requires game knowledge!) The Horizon Effect: Search has to stop somewhere, but a huge change might be lurking just over the horizon. There is no general fix but heuristics can sometimes help.
Pruning • Suppose your program can search 1000 positions/second. • In chess, you get roughly 150 seconds per move so you can search 150,000 positions. • Since chess has a branching factor of about 35, your program can only search 34 ply! • An average human plans 68 moves ahead so your program will act like a novice. • Fortunately, we can often avoid searching parts of the game tree by keeping track of the best and worst alternatives at each point. This is called pruning the search tree.
Alpha-Beta Pruning • Alpha-beta pruning is used on top of minimax search to detect paths that do not need to be explored. The intuition is: • The MAX player is always trying to maximize the score. Call this . • The MIN player is always trying to minimize the score. Call this . • When a MIN node has <= the of its MAX ancestors, then this path will never be taken. (MAX has a better option.) This is called an -cutoff. • When a MAX node has >= the of its MIN ancestors, then this path will never be taken. (MIN has a better option.) this is called an -cutoff
Bounding Search The minimax procedure explores every path of length depth. Can we do less work? A MAX B C D MIN E F G H I J K L
Bounding Search (3) A MAX B (3) C D MIN E (3) F (12) J K L G (8) H I
Bounding Search (3) A MAX B (3) C (<-5) D MIN E (3) F (12) J K L G (8) H (-5) I
Bounding Search A (3) MAX B (3) C (<-5) D (2) MIN E (3) F (12) J (15) K (5) L (2) G (8) H (-5) I
2. - pruning: search cutoff • Pruning: eliminating a branch of the search tree from consideration without exhaustive examination of each node • - pruning:the basic idea is to prune portions of the search tree that cannot improve the utility value of the max or min node, by just considering the values of nodes seen so far. • Does it work? Yes, in roughly cuts the branching factor from b to b resulting in double as far look-ahead than pure minimax
- pruning: example 6 MAX MIN 6 6 12 8
- pruning: example 6 MAX MIN 6 2 6 12 8 2
- pruning: example 6 MAX MIN 5 6 2 6 12 8 2 5
- pruning: example 6 MAX Selected move MIN 5 6 2 6 12 8 2 5
- pruning: general principle Player m Opponent If > v then MAX will chose m so prune tree under n Similar for for MIN Player n v Opponent
Properties of Alpha-Beta Pruning • Alpha-beta pruning is guaranteed to find the same best move as the minimax algorithm by itself, but can drastically reduce the number of nodes that need to be explored. • The order in which successors are explored can make a dramatic difference! • In the optimal situation, alpha-beta pruning only needs to explore O(bd/2 ) nodes. • Minimax search explores O(b d ) nodes, so alpha-beta pruning can afford to double the search depth! • If successors are explored randomly, alpha-beta explores about O(b3d/4). • In practice, heuristics often allow performance to be closer to the best-case scenario.
AlphaBeta Pruning Algorithm procedure alpha-beta-max(node, , ) if leaf node(node) then return evaluation(node); foreach (successor s of node) := max(,alpha-beta-min(s, , )); if >= then return ; return ; procedure alpha-beta-min(node, , ) if leaf node(node) then return evaluation(node); foreach (successor s of node) := min(,alpha-beta-max(s, , ); if <= then return ; return ; To begin, we invoke: alpha-beta-max(node,1,1)
Alpha-beta pruning • Pruning does not affect final result • Alpha-beta pruning • Asymptotic time complexity • O((b/log b)d) • With “perfect ordering,” time complexity • O(bd/2) • means we go from an effective branching factor of b to sqrt(b) (e.g. 35 -> 6).
a-b Procedure • minimax-a-b(board, depth, type, a, b) • If depth = 0 return Eval-Fn(board) • else if type = max • cur-max = -inf • loop for b in succ(board) • b-val = minimax-a-b(b,depth-1,min, a, b) • cur-max = max(b-val,cur-max) a= max(cur-max, a) if cur-max >= b finish loop • return cur-max • else type = min • cur-min = inf • loop for b in succ(board) • b-val = minimax-a-b(b,depth-1,max, a, b) • cur-min = min(b-val,cur-min) b= min(cur-min, b) if cur-min <= a finish loop • return cur-min
a-b Pruning Example max min max min
a-b Pruning Example max 10 min 10 4 max 4 10 14 min 10 2 9 14 4
Now, you do it! Max Min Max Min
A (3) B (3) C (<-5) D (2) E (3) F (12) J (15) K (5) L (2) G (8) H (-5) I Move Ordering Heuristics Good move ordering improves effectiveness of pruning MAX A (3) B (3) C (<-5) D (<2) MIN E (3) F (12) G (8) H (-5) I L (2) K (5) J (15) Original Ordering Better Ordering
Using Book Moves • Use catalogue of “solved” positions to extract the correct move. • For complicated games, such catalogues are not available for all positions • Often, sections of the game are well-understood and catalogued • E.g. openings and endings in chess • Combine knowledge (book moves) with search (minimax) to produce better results.
Games with Chance • How to include chance – Add chance node
Decision Making in Game of Chance • Chance nodes • Branches leading from each chance node denote the possible dice rolls • Labeled with the roll and the chance that it will occur • Replace MAX/MIN nodes in minimax with expected MAX/MIN payoff • Expectimax value of C • Expectimin value
Position evaluation in games with chance nodes • For minimax, any order-preserving transformation of the leaf values does not affect the choice of move • With chance node, some order-preserving transformations of the leaf values do affect the choice of move
Position evaluation in games with chance nodes (cont’d) • The behavior of the algorithm is sensitive even to a linear transformation of the evaluation function.
Complexity of expectiminimax • The expectiminimax considers all the possible dice-roll sequences • It takes O(bmnm) where n is the number of distinct rolls • Whereas, minimax takes O(bm) • Problems • The extra cost compared to minimax is very high • Alpha-beta pruning is more difficult to apply
Context Terrorists do a lot of different things The U.S. can try and anticipate all kinds of things in defense of these attacks If the U.S. fails to invest wisely, then we lose important battles.
A Smallpox Exercise The U.S. government is concerned about the possibility of smallpox bioterrorism. Terrorists could make no smallpox attack, a small attack on a single city, or coordinated attacks on multiple cities (or do other things).
The U.S. has four defense strategies: • Stockpiling vaccine • Stockpiling and increasing bio-surveillance • Stockpiling and inoculating first responders and/or key personnel • Inoculating all consenting people with healthy immune systems.
Using Game Theory to make a decision • Classical game theory uses a matrix of costs to determine optimal play. • Optimal play is usually defined as a minimax strategy, but sometimes one can minimize expected loss instead. • Both methods are unreliable guides to human behavior.
Minimax Strategy The U.S. should choose the defense with smallest row-wise max cost. The terrorist should choose the attack with largest column-wise min cost. If these are not equal then a randomized strategy is better.
Extensive-form game theory invites decision theory criteria based upon minimum expected loss. In our smallpox exercise, we shall implement this by assuming that the U.S. decisions are known to the terrorists, and that this affects their probabilities of using certain kinds of attacks.
Game Theory Critique • Game theory does not take account of resource limitations. • It assumes that both players have the same cost matrix. • It assumes both players act in synchrony (or in strict alternation). • It assumes all costs are measured without error.
Adding Risk Analysis Statistical risk analysis makes probabilistic statements about specific kinds of threats. It also treats the costs associated with threats as random variables. The total random cost is developed by analysis of component costs.