Optimizing Search Algorithms for Real-World Applications: A Regressive Tree Perspective
180 likes | 287 Vues
This study delves into tuning search algorithms for optimal performance in practical scenarios, focusing on minimizing customer wait time for elevator entry. It compares different methodologies such as regression analysis, ANOVA, DACE, and CART, with an emphasis on optimization via simulation and direct search algorithms like Evolution Strategies and Simulated Annealing. Experimental analysis using Design of Experiments and regression tree analysis is performed to identify effective parameter settings for enhanced performance. The results highlight the significance of parameter optimization and the potential of tree-based regression in improving algorithm efficiency. Presented by Frank Hutter, this research offers valuable insights into enhancing search algorithm outcomes in real-world settings.

Optimizing Search Algorithms for Real-World Applications: A Regressive Tree Perspective
E N D
Presentation Transcript
Empirical Algorithmics Reading Group Oct 11, 2007Tuning Search Algorithms for Real-World Applications:A Regression Tree Based Approachby Thomas Bartz-Beielstein & Sandor MarkonPresenter: Frank Hutter
Motivation • “How to find a set of working parameters for direct search algorithms when the number of allowed epxeriments is low” • i.e. find good parameters with few evaluations • Taking a user’s perspective: • Adopt standard params from the literature • But NFL theorem: can’t do good everywhere • Tune for instance class / for optimization instances even on a single instance
Considered approaches • Regression analysis • ANOVA • DACE • CART
Elevator Group Control • Multi-objective problem • Overall service quality • Traffic throughput • Energy consumption • Transport capacity • Many more … • Here: only one objective • Minimize time customers have to wait until they can enter the elevator car
Optimization via Simulation • Goal: Optimize expected performanceE[y(x1,…, xn)] (x1,…, xn controllable) • Black box function y
Direct search algorithms • Do not construct a model of the fitness function • Interesting aside: same nomenclature as I use, but independent • Here • Evolution strategy (special class of evolutionary algorithm) • Simulated annealing
Evolution strategies (ES) • Start out with parental population at t=0 • For each new generation: • Create l offsprings • Select parent family of size \rho at random • Apply recombination to object variables (?) and strategy parameters (?) • Mutation of each offspring • Selection
Many parameters in ES • Number of parent individuals • Number of offspring individuals • Initial mean step sizes (si) • Can choose problem-specific, different si for each dimension (not done here) • Number of standard deviations (??) • Mutation strength (global/individual, extended log-normal rule ??) • Mixing number (size of each parent family) • Recombination operator • For object variables • For strategy variables • Selection mechanims, maximum life span Plus-strategies (m + l) and comma-strategies (m, l)Can be generalized by k (maximum age of individual)
Simulated Annealing • Proposal: Gaussian Markov kernel with scale proportional to the temperature • Decrease temperature on a logarithmic cooling schedule • Two parameters • Starting temperature • Number of function evaluations at each temperature
Experimental Analysis of Search Heuristics • Which parameters have the greatest effect? • Screening • Which parameter setting might lead to an improved performance • Modelling • Optimization
Design of experiments (DOE) • Choose two factors for each parameter • Both qualitative and quantitative • 2k-p fractional factorial design • 2: number of levels for each factor • K parameters • Only 2k-p experiments • Can be generated from a full factorial design on k-p params • Resolution = (k-p) +1 (is this always the case?) • Resolution 2: not useful – main effects are confounded with each other • Resolution 3: often used, main effects are unconfounded with each other • Resolution 4: all main effects are unconfounded with all 2-factor interactions • Resolution 5: all 2-factor interactions are unconfounded with each other • Here: 2III9-5 fractional factorial design
Regression analysis • Using stepAIC function built into R • Akaike’s information criterion to penalize many parameters in the model • Line search to improve algorithm’s performance (?)
Tree based regression • Used for screening • Based on the fractional factorial design • Forward growing • Splitting criterion: minimal variance within the two children • Backward pruning: snipping away branches to maximize penalized cost • Using rpart implementation from R • 10-fold cross validation • “1-SE” rule: mean + 1stddev as pessimistic estimate • Threshold complexity parameter: visually chosen based on 1-SE rule
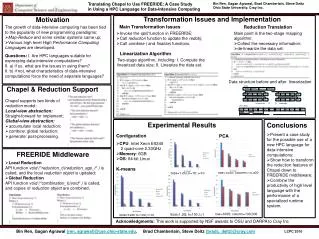
Experimental results • 5000 fitness evaluations as termination criterion • Initialization already finds good parameters! only small improvements possible • Actual results not too important, but methods! • Questions • Is k strategy useful? • Improve parameters • Which analysis strategy works?
k strategy useful?regression tree analysis • Two splits (m, k):Regression analysis:only first split significant • Tuned algorithm foundsolution with quality y=32.252 • Which parameter settings? • What does 32.252 mean? • How about multiple runs?
New Gupta vs. classical + selection • Tune old and new variants • Report new results and runtime for tuning • Just that they do not report the runtime for tuning
Comparison of approaches on Simulated Annealing • Only two (continuous) parameters • Classical regression “fails” • No significant effects • Regression tree • Best around 10,10 • Based on a full-factorial design with 2 levels each this is pretty shaky
Comparison of approaches E.g. regression trees for screening, then DACE if only a few continuous parameters remain (why the restriction to few?)