
Data Explosion in Bioinformatics
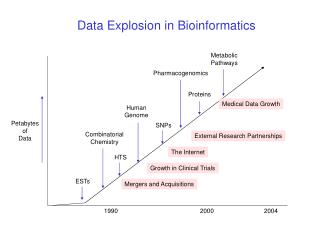
Data Explosion in Bioinformatics. Metabolic Pathways. Pharmacogenomics. Proteins. Medical Data Growth. Human Genome. Petabytes of Data. SNPs. Combinatorial Chemistry. External Research Partnerships. The Internet. HTS. Growth in Clinical Trials. ESTs. Mergers and Acquisitions.

Data Explosion in Bioinformatics
E N D
Presentation Transcript
Data Explosion in Bioinformatics Metabolic Pathways Pharmacogenomics Proteins Medical Data Growth Human Genome Petabytes of Data SNPs Combinatorial Chemistry External Research Partnerships The Internet HTS Growth in Clinical Trials ESTs Mergers and Acquisitions 1990 2000 2004
Products/Results Metabolomics Proteomics Functional Genomics Genomics Omics series Enabling Arrow ofBioinformatics
Data Mining Development of new tools for data mining • Sequence alignment • Genome sequencing • Genome comparison • Micro array data analysis • Proteomics data analysis • Small molecular array analysis To derive “information” and gain “knowledge” from the data
Genomes: Current Status • Published complete genomes: 186 • Archaeal: 18 • Bacterial: 142 • Eukaryote: 26 • Completed Viral genomes: >2000 • Prokaryotic ongoing genomes: 490 • Eukaryotic ongoing genomes: 416 Highly voluminous data: Needs to be analyzed for Knowledge Generation As of April 7, 2004
The Post-Human Genome Scenario Knowledge of Full Genome sequence: Solutions or new questions…? • Struggling with the gene counters… Correct # of genes…? SCIENCE VOL 301 22 AUGUST 2003
Functional Annotation:Comparative Genomics Only ~17% of total DNA Cross-species comparisons of sequences of 7 chromosomes • Nature. 2003 Oct 23;425(6960):805-11.
Function information clock of E. coli Generated on March 2K4
Post-sequencing challenges • Genome sequencing is just the beginning to appreciate biocomplexity • Sequence-based function assignment approaches fail as the sequence similarity drops … • Structure-based function prediction approaches are limited by the availability of structures, association of structural motifs & associated functional descriptor • As a result, in any genome, Genes with known function: ~ 40% Genes with unknownfunction: ~60%
Development of Peptide Vaccine for Japanese encephalitis virus Project Chimeric T helper - B cell peptide vaccine against JEV Bioinformatics Centre, University of Pune, Pune.
We Have Chosen JE Virus, Because • JE virus is endemic in South-east Asia including India. • JE virus causes encephalitis in children between 5-15 years of age with fatality rates between 21-44%. • Man is a "DEAD END" host.
We Have Chosen JE Virus, Because • Killed virus vaccine purified from mouse brain is used presently which requires storage at specific temperatures and hence not cost effective in tropical countries. • Protective prophylactic immunity is induced only after administration of 2-3 doses. • Cost of vaccination, storage and transportation is high.
Why Synthetic Peptide Vaccines? • Chemically well defined, selective and safe. • Stable at ambient temperature. • No cold chain requirement hence cost effective in tropical countries. • Simple and standardised production facility.
Egp of JEV as an Antigen • Is a major structural antigen. • Responsible for viral haemagglutination. • Elicits neutralising antibodies. • ~ 500 amino acids long. • Structure of extra-cellular domain (399) was predicted using knowledge-based homology modeling approach.
STEPS in Homology Modeling • Template structure (PDB entry: 1SVB). (Rey et al., 1995). • Alignment of Egp of JEV and Egp of TBEV. • Definition of SCRs and Loops. • Assignment of Initial co-ordinates to Backbone & Side-chains. • Rotamer search for the favored side-chain conformations.
Model RefinementPARAMETERS USED • force field: AMBER all atom • Dielectric const: Distance dependent • Optimisation: Steepest Descents & Conjugate Gradients. • rms derivative 0.1 kcal/mol/A for SD • rms derivative 0.001 kcal/mol/A for CG • Biosym from InsightII, MSI and modules therein.m
Predicted structure of JEVSMutations: JEVN/JEVS Predicted structures were used to explain strain-specific variations
Multiple alignment of Predicted TH-cell epitope in the JE_Egp with corresponding epitopes in Egps of other Flaviviruses • 426457 • JE DFGSIGGVFNSIGKAVHQVFGGAFRTLFGGMS • MVE DFGSVGGVFNSIGKAVHQVFGGAFRTLFGGMS • WNE DFGSVGGVFTSVGKAIHQVFGGAFRSLFGGMS • KUN DFGSVGGVFTSVGKAVHQVFGGAFRSLFGGMS • SLEDFGSIGGVFNSIGKAVHQVFGGAFRTLFGGMS • DEN2DFGSLGGVFTSIGKALHQVFGAIYGAAFSGVS • YFDFSSAGGFFTSVGKGIHTVFGSAFQGLFGGLN • TBEDFGSAGGFLSSIGKAVHTVLGGAFNSIFGGVG • COMM DF S GG S GK H V G F G • Multiple alignment of JE_Egp with Egps of other Flaviviruses in the YSAQVGASQ region. • 151 183 • JE SENHGNYSAQVGASQAAKFTITPNAPSITLKLG • MVE STSHGNYSTQIGANQAVRFTISPNAPAITAKMG • WNE VESHG‑‑‑‑KIGATQAGRFSITPSAPSYTLKLG • KUN VESHGNYFTQTGAAQAGRFSITPAAPSYTLKLG • SLE STSHGNYSEQIGKNQAARFTISPQAPSFTANMG • DEN2 HAVGNDTG‑‑‑‑‑KHGKEIKITPQSSTTEAELT • YF QENWN‑‑‑‑‑‑‑‑TDIKTLKFDALSGSQEVEFI • TBE VAANETHS‑‑‑‑GRKTASFTIS‑‑SEKTILTMG
Peptide Modeling • Initial random conformation • Force field: Amber • Distance dependent dielectric constant 4rij • Geometry optimization: Steepest descents & Conjugate gradients • Molecular dynamics at 400 K for 1ns • Peptides are: • SENHGNYSAQVGASQ • NHGNYSAQVGASQ • YSAQVGASQ • YSAQVGASQAAKFT • NHGNYSAQVGASQAAKFT • SENHGNYSAQVGASQAAKFT • 149 168
Bioinformatics In Action • Molecular modeling studies help in predicting surface antigens • Conformational epitopes predicted using available crystal structure data • Candidate peptide for vaccine chosen from amongst predicted determinants • C-terminal and N-terminal regions help stabilize conformation of peptide epitope • Experimental studies validate predictions
VirGen A comprehensive Viral Genome Resource http://bioinfo.erent.in/virgen/virgen.html
Lesson learnt: JEV test case • GOLD DB: ignores viral genomes • Viral genome resources at NCBI and EBI are incomplete • No consensus on number of genomes available for JEV in GenBank, EMBL & DDBJ. Need to organise the sequence space of viruses with respect to genomic data
Pre VirGen Era • Model Problem • Compile all available genomes of viruses that belong to a family, eg. Flaviviridae • Method • Search the genome databases • Available only for Model organisms (Prokaryotes & Eukaryotes) • Search Large repositories • EMBL, GenBank & DDBJ
Public Repository VirGenIssues involved in data curation • Source of data: GenBank • Retrieval engine: Entrez • Queries: well-designed Perl scripts • Consistent with ICTV nomenclature • Annotation including strain information • Generation of representative list of genomes • Sequence-based ontology for viral proteins • Annotation of unannotated entries using representative genomes
VirGen homehttp://bioinfo.ernet.in/virgen/virgen.html Genome analysis & Comparative genomics resources Menu to browse viral families Search using Keywords & Motifs Guided tour & Help Navigation bar
Salient Features of VirGen • Organizes genomic data in a structured fashion navigating from the family to an isolate • Compilation of representative genome entries for every viral species (Virus Taxonomy, 7th report of ICTV) • Complete annotation of every genomic entry & Generation of alternative names of proteins • Graphical representation of genome organization using SVG technology • Multiple Sequence Alignment (MSA) of genomes, proteomes and individual proteins • Whole genome phylogeny • Prediction of B-cell epitopes • Keyword & Motif based searches • On-the-fly genome comparisons using BLAST suite of programs
Sample genome record in VirGen Tabular display of genome annotation List of known antigenic proteins ‘Alternate names’ of proteins Retrieve sequence in FASTA format
Graphical view of Genome Organization Viral polyprotein along with the UTRs Graphical view generated dynamically using Scalable Vector Graphics technology
Multiple Sequence Alignment MSA Link for batch retrieval of sequences Dendrogram
Browsing the module of Whole Genome Phylogenetic trees Most parsimonious tree of genus Flavivirus Input data: Whole genome Method: DNA parsimony Bootstrapping: 1000
Pestivirus Hepacivirus Unassigned Pestivirus Whole Genome Phylogeny in VirGen Family: FlaviviridaeNo. of species: 29 Flavi:Tick borne Flavi:Mosquito borne
Searching VirGen VirGen query engine • Taxonomy • Family, Genus, Species name(s) • Keyword search • Accession, GI, species name, protein, etc. • Sequence search • Motif • Peptide (length 30) • Nucleotide (length 30)
On the fly genome comparisons using BLAST series of programs
Bioinformatics in Action - 2 • Representative Genome list • A curated and annotated data set for analyses • Study of Genome organisation • Using graphical representation of genome organisation provided by VirGen • MSA data • Discovery of patterns: Diagnostics • Primer design • Predicted epitopes • Vaccinome at a glance: DNA/peptide vaccine • Whole Genome Phylogeny • Evolution of strains/viruses • Characterisation of virus
Acknowledgements • Funded by: • VirGen is funded by Department of Biotechnology, Govt. of India • VirGen Team: • Prof. A.S. Kolaskar • Urmila Kulkarni-Kale • G. Sunitha Manjari • Shriram Bhosle • Contribution through ADB Projects: • Avinash Gill • Dr. Pushparaj Madavi • Publication: Urmila-Kulkarni-Kale, Bhosle, S., Sunitha Manjari,G., Kolaskar, A.S. (2004) VirGen: A comprehensive viral genome resource. Nucleic Acids Res., Jan 1;32 Database issue:D289-92.
Salient Features of MetaPath@UoP • Dynamic Representation of pathways • Dynamically building the organism-specific pathways from genomic data • Development of Software for • Automated data updating (Perl scripts) • Reformatting and organization of relevant information from different databases • Drawing pathways diagrams • Comparison of pathways • Visualization of ligands, enzymes • Prediction of enzyme-substrate interactions
ID Method PH Buffer Cofactor Commnt No Name Formula Image M W Col 1 Col 2 Col 3 Col 4 Col 5 COMPOUND C-Syno-names has RKConstant Relation Attribute is a Weak Entity KINETICS has EC NO CSA NO Name Commnt R-Right R-Left -Reactant -Product ESYNONAMES Name has has ID Direction DISEASE ENZYME REACTION has Catalyses ID MP DATABASE DESIGN COFACTOR ID Code for Participate Carry MOTIF ID Motif GENE ORGANISM Organism-Gene STRUCTURE ID Name Org-Pathway ID Name Define Position aa Seq nt Seq ID Data Image has PATHWAY PsynoNames PW-Class ID Name Name Class from
Source Databases for Data Acquisition • Sequence databases: TIGR, NCBI, EBI • Metabolite databases: KEGG • Metabolic pathway database: KEGG • 3D Structure database: PDB • Enzyme Database: KEGG, EXPASY, IUBMB • Kinetics Data: NIST




















