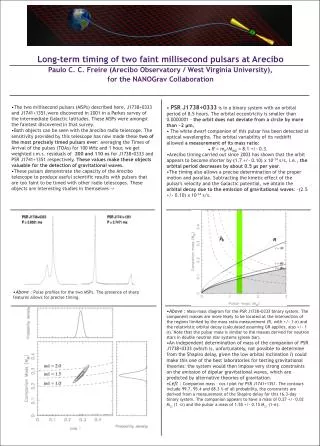
Understanding Text Processing for Language Models and Part-of-Speech Tagging
This overview introduces key concepts in text processing, including understanding, search ranking, and autocompletion. It discusses practical applications such as spelling correction using edit distance, which measures the minimum number of operations required to transform one string into another. The concepts of dynamic programming and models like Bag-of-words, n-grams, and Hidden Markov Models are highlighted, emphasizing their roles in tasks such as Part-of-Speech tagging and machine translation. The Viterbi algorithm is introduced as a method for determining the most probable state sequences in language models.


Understanding Text Processing for Language Models and Part-of-Speech Tagging
E N D
Presentation Transcript
Why? • To “understand” text • To assist in text search & ranking • For autocompletion • Part of Speech Tagging
Simple application: spelling suggestions • Say that we have a dictionary of words • Real dictionary or the result of crawling • Sentences instead of words • Now we are given a word w not in the dictionary • How can we correct it to something in the dictionary
String editing • Given two strings (sequences) the “distance” between the two strings is defined by the minimum number of “character edit operations” needed to turn one sequence into the other. • Edit operations: delete, insert, modify (a character) • Cost assigned to each operation (e.g. uniform =1 )
Edit distance • Already a simple model for languages • Modeling the creation of strings (and errors in them) through simple edit operations
Distance between strings • Edit distance between strings = minimum number of edit operations that can be used to get from one string to the other • Symmetric because of the particular choice of edit operations and uniform cost • distance(“WillliamCohon”,“William Cohen”) • 2
Finding the edit distance • An “alignment” problem • Deciding how to align the two strings • Can we try all alignments? • How many (reasonable options) are there?
Dynamic Programming • An umbrella name for a collection of algorithms • Main idea: reuse computation for sub-problems, combined in different ways
Example: Fibonnaci if n = 0 or n = 1 return n else return fib(n-1) + fib(n-2) Exponential time!
Fib with Dynamic Programming table = {} def fib(n): global table if table.has_key(n): return table[n] if n == 0 or n == 1: table[n] = n return n else: value = fib(n-1) + fib(n-2) table[n] = value return value
Using a partial solution • Partial solution: • Alignment of s up to location i, with t up to location j • How to reuse? • Try all options for the “last” operation
Base case : D(i,0)=I, D(0,i)=i for i inserts \ deletions • Easy to generalize to arbitrary cost functions!
Models • Bag-of-words • N-grams • Hidden Markov Models • Probabilistic Context Free Grammar
Bag-of-words • Every document is represented as a bag of the words it contains • Bag means that we keep the multiplicity (=number of occurrences) of each word • Very simple, but we lose all track of structure
n-grams • Limited structure • Sliding window of n words
How would we infer the probabilities? • Issues: • Overfitting • Probability 0
How would we infer the probabilities? • Maximum Likelihood:
"add-one" (Laplace) smoothing • V = Vocabulary size
Richer Models • HMM • PCFG
Motivation: Part-of-Speech Tagging • Useful for ranking • For machine translation • Word-Sense Disambiguation • …
Part-of-Speech Tagging • Tag this word. This word is a tag. • He dogs like a flea • The can is in the fridge • The sailor dogs me every day
A Learning Problem • Training set: tagged corpus • Most famous is the Brown Corpus with about 1M words • The goal is to learn a model from the training set, and then perform tagging of untagged text • Performance tested on a test-set
Simple Algorithm • Assign to each word its most popular tag in the training set • Problem: Ignores context • Dogs, tag will always be tagged as a noun… • Can will be tagged as a verb • Still, achieves around 80% correctness for real-life test-sets • Goes up to as high as 90% when combined with some simple rules
(HMM)Hidden Markov Model • Model: sentences are generated by a probabilistic process • In particular, a Markov Chain whose states correspond to Parts-of-Speech • Transitions are probabilistic • In each state a word is outputted • The output word is again chosen probabilistically based on the state
HMM • HMM is: • A set of N states • A set of M symbols (words) • A matrix NXN of transition probabilities Ptrans • A vector of size N of initial state probabilities Pstart • A matrix NXM of emissions probabilities Pout • “Hidden” because we see only the outputs, not the sequence of states traversed
3 Fundamental Problems 1) Compute the probability of a given observation Sequence (=sentence) 2) Given an observation sequence, find the most likely hidden state sequence This is tagging 3) Given a training set find the model that would make the observations most likely
Tagging • Find the most likely sequence of states that led to an observed output sequence • Problem: exponentially many possible sequences!
Viterbi Algorithm • Dynamic Programming • Vt,k is the probability of the most probable state sequence • Generating the first t + 1 observations (X0,..Xt) • And terminating at state k
Viterbi Algorithm • Dynamic Programming • Vt,k is the probability of the most probable state sequence • Generating the first t + 1 observations (X0,..Xt) • And terminating at state k • V0,k = Pstart(k)*Pout(k,X0) • Vt,k= Pout(k,Xt)*max{Vt-1k’ *Ptrans(k’,k)}
Finding the path • Note that we are interested in the most likely path, not only in its probability • So we need to keep track at each point of the argmax • Combine them to form a sequence • What about top-k?
Complexity • O(T*|S|^2) • Where T is the sequence (=sentence) length, |S| is the number of states (= number of possible tags)
Computing the probability of a sequence • Forward probabilities: αt(k) is the probability of seeing the sequence X1…Xt and terminating at state k • Backward probabilities: βt(k) is the probability of seeing the sequence Xt+1…Xn given that the Markov process is at state k at time t.
Computing the probabilities Forward algorithm α0(k)= Pstart(k)*Pout(k,X0) αt(k)= Pout(k,Xt)*Σk’{αt-1k’ *Ptrans(k’,k)} P(O1,…On)= Σk αn(k) Backward algorithm βt(k) = P(Ot+1…On| state at time t is k) βt(k) = Σk’{Ptrans(k,k’)* Pout(k’,Xt+1)* βt+1(k’)} βn(k) = 1 for all k P(O)= Σk β0(k)* Pstart(k)
Learning the HMM probabilities • Expectation-Maximization Algorithm • Start with initial probabilities • Compute Eij the expected number of transitions from i to j while generating a sequence, for each i,j (see next) • Set the probability of transition from i to j to be Eij/ (ΣkEik) 4. Similarly for omission probability 5. Repeat 2-4 using the new model, until convergence
Estimating the expectancies • By sampling • Re-run a random a execution of the model 100 times • Count transitions • By analysis • Use Bayes rule on the formula for sequence probability • Called the Forward-backward algorithm
Accuracy • Tested experimentally • Exceeds 96% for the Brown corpus • Trained on half and tested on the other half • Compare with the 80-90% by the trivial algorithm • The hard cases are few but are very hard..
NLTK • http://www.nltk.org/ • Natrual Language ToolKit • Open source python modules for NLP tasks • Including stemming, POS tagging and much more
Context Free Grammars • Context Free Grammars are a more natural model for Natural Language • Syntax rules are very easy to formulate using CFGs • Provably more expressive than Finite State Machines • E.g. Can check for balanced parentheses
Context Free Grammars • Non-terminals • Terminals • Production rules • V → w where V is a non-terminal and w is a sequence of terminals and non-terminals
Context Free Grammars • Can be used as acceptors • Can be used as a generative model • Similarly to the case of Finite State Machines • How long can a string generated by a CFG be?
Stochastic Context Free Grammar • Non-terminals • Terminals • Production rules associated with probability • V → w where V is a non-terminal and w is a sequence of terminals and non-terminals