SPARS-J: Java Component Search System Overview
This paper provides an overview and evaluation of the SPARS-J (Software Product Archive, Analysis, and Retrieval System for Java) component search system. The motivation, research aim, system architecture, ranking methods, and experimental evaluation for SPARS-J are discussed. It aims to help developers manage and search for suitable software components efficiently. The system analyzes and extracts Java source code components, builds a database, and provides keyword search functionality with various ranking methods. The experimental evaluation compares different ranking methods and verifies the system's effectiveness. The goal is to enhance software component reuse and increase productivity in software development environments.


SPARS-J: Java Component Search System Overview
E N D
Presentation Transcript
Overview and Evaluation ofJava Component SearchSystem SPARS-J Reishi Yokomori **, Hideo Nishi**, Fumiaki Umemori**, Tetsuo Yamamoto*, Makoto Matsushita**, Shinji Kusumoto **Katsuro Inoue** *Japan Science and Technology Agency **Osaka University
Outline • Motivation and research aim • SPARS-J • SPARS-J (Outline) • Ranking method • System architecture • Experimental evaluation for SPARS-J • Conclusion and Future work
Motivation • A library of software is a fount of wisdom. • Reuse of software components improves productivity and quality. • Example of components: source code, document ….. • Maintenance activity is more easier with the library. • However, a collection of software is not utilized effectively. • A developer doesn’t know an existence of desirable components. • Although there are a lot of components, these components are not organized. • We need a system to manage components and to search suitable component.
Research aim • We build a system which have functions as follows • searches component, which is suitable for user’s request • manages the component information • Targets • Intranet • Closed software development environment inside a company • Internet • Source code from a lot of open-source-software community • Source Forge, Jakarta Project. etc.
Outline • Motivation and research aim • SPARS-J • SPARS-J (Outline) • Ranking method • System architecture • Experimental evaluation for SPARS-J • Conclusion and Future work
SPARS-J(Software Product Archive,analysis and Retrieval System for Java) • SPARS-J is Java Source Code Search System • analyzes and extracts components automatically. • Component: a source code of class or interface • builds a database based on the analysis. • Use-Relation, Similar Components, Metrics, ..... • provides keyword-search. • Three ranking methods: KR, CR, KR+CR • Analysis information • Components using (used by) the component • Package hierarchy
Keyword Rank (KR) Component Rank (CR) KR+CR Rank ( KR+CR) Ranking search results • Ranking method • Component used repeatedly (by important component) • Ranking based on use relation between components • Component suited to a user request • Frequency of word appearance (arranged TF-IDF) • A class-name, a method-name, ..., have special importance • Integrated Ranking • Components prized both in KR and CR are very important • Integration by Borda Count method
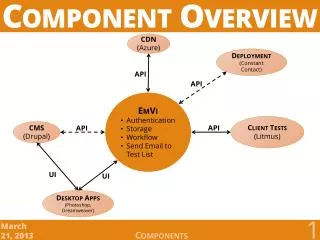
User interface Component retrieval System architecture of SPARS-J (Building a Database) Library(Java source files) Database Component analysis store • Component Information • Indexes • Use-Relation • Clustered Component Graph • Component Rank • extracts components • indexes each appeared word • extracts use-relation • clustering similar components • calculates Component rank provide
User Database • Component Information • Indexes • Use-Relation • Clustered Component Graph • Component Rank System architecture of SPARS-J (Searching Components) Component analysis Component retrieval • searches components • from Indexes • sorts components • by CR, KR, KR+CR Query User interface Query • analyzes query • Analysis condition • Keywords • displays search results • Additional Information • Source Code • Use Relation • Similar Components • Metrics • etc......... Components List Result Request Information
Outline • Motivation and research aim • SPARS-J • SPARS-J (Outline) • Ranking method • System architecture • Experimental evaluation for SPARS-J • Conclusion and Future work
Experimental Evaluation • Comparison of each ranking method in SPARS-J • We investigate the best ranking method • CR vs. KR vs. CR+KR • Comparison with other search engines • We verify SPARS-J’s effectiveness as a software component search engine. • vs. Google, Namazu • Application of SPARS-J in actual development environment • We confirm that SPARS-J is useful to management and understanding of software.
Experiment 1: Comparisonof ranking method in SPARS-J • Purpose of Experiment • We investigate the best method among 3 ranking method in SPARS-J. • CR (Based on Use-relation) • KR (Based on TF-IDF) • CR+KR ( Integrating 1 & 2) • Preparation • Database from Java source codes publicly available • About 140,000 files from JDK, SourceForge, etc..... • Keywords • 10 queries assumed development of simple system
Experiment 1: Comparisonof ranking method in SPARS-J • Criterion of Evaluation • Precision of components in the top 10 Result: • The percentage of suitable components • User tends to look at only a higher ranked results. • High precision means that there are many useful components in range of user’s visibility. • Ndpm: • The percentage of the component pair which differs rank order between two ranking methods. • We define user‘s ideal ranking in advance, and calculate ndpm. • The quantitative indicator which shows a distance from ideal • Ndpm considers all the components in a search result. • Its distance becomes large when required components are ranked low.
Result (Experiment 1) Ndpm Precision
Consideration (Experiment 1) • By Paired-Difference T-Test, we have confirmed that following difference are significant at the 5% level. • Precision: KR,CR+KR ≫ CR • Ndpm: CR,CR+KR ≫ KR • Characteristic of each method • CR • CR generally ranks components in desirable order. • Higher ranked components are important but often have no relevance to keyword. • KR • KR generally appreciates components which have strong relevance. • In required component, keyword doesn’t always appear with high frequency. • CR+KR • CR+KR has good result at both precision and ndpm. • CR+KR has the best of both ranking • We use CR+KR as a default ranking method.
Experiment 2:Comparison with other search engines • Purpose of Experiment • We verify SPARS-J’s effectiveness as a software component search engine. • SPARS-J • Database from 140,000 files (Same as Experiment 1) • We use CR+KR as ranking method. • Google • Famous web search Engine • Input queries to www.google.co.jp • Namazu • Full-text search system for documents. • Namazu uses TF-IDF to rank documents. • Database from 140,000 files (Same files as SPARS-J) • Preparation • Keywords: 10 queries (Same as Experiment 1) • Criterion of Evaluation: Precision of the top 10 Result
Result (Experiment 2) Precision of the top 10 result
Consideration (Experiment 2) • By Paired-Difference T-Test, we have confirmed that following difference are significant at the 5% level. • Precision SPARS-J≫ Namazu ≫ Google (*) SPARS-J (CR, KR, CR+KR) ≫ Namazu • Consideration of Results • Google • In the result, there are many pages other than an explanation of Java source code. • Performance depends on how much description there are. • Namazu • Since the datasets consists of only source codes, the result is better than Google. • Without characteristics of Java programs, we cannot get good results. • For searching software components, SPARS-J is more useful than other search engines.
Experiment 3: Application of SPARS-J in actual development environment • Purpose of Experiment • We confirm that SPARS-J is useful to management and understanding of software resource. • Criterion of Evaluation • Qualitative evaluation about SPARS-J • Preparation • We set up SPARS-J to a company. • 7 employees use SPARS-J for two weeks. • They are all engaged in the software development and the maintenance activity. • We carry out a questionnaire survey about SPARS-J
Result (Experiment 3) ( [Useful or Used repeatedly] 5 4 3 2 1 [Useless or seldom Used] )
Consideration (Experiment 3) • Highly rated questionnaire items • Reference by package browser • Reference by similar components • Reference by components using (used by) the class • View-ability of the component list view and source code • Activities realized by using SPARS-J • Listing of applications which uses certain component • Impact analysis at reediting components
Consideration (Experiment 3) • Other comment • Response speed is very quick, and we have felt no stress. • Since it is not necessary to install in a client, sharing of software components is easy. • SPARS-J can support maintenance work effectively. • Easier grasp of software components
Conclusion and Future works Conclusion • We construct software component search system SPARS-J. • Search engine for Java source code • Ranking components with consideration of characteristics. • Provision of useful relevant information. • We verified the validity of SPARS-J based on experimental evaluation. • SPARS-J is useful to search software components. • SPARS-J is very helpful to grasp and manage components. Future works • The quantitative evaluation other than ranking performance • Support for other software component
Outline • Motivation and research aim • SPARS-J • Outline • System architecture • Ranking method • Each part • Analysis part • Retrieval part • User Interface • Experiment • Conclusion and Future work
Component analysis part • Extract component and its information from a Java source file • The process • Extract a component • Index the component • Extract use relations • Clustering similar components • Rank components based on use relations (CR method)
Extract and index a component • Extracting component • Find class or interface block in a java source file • Location information in the file (start line number, end line number) • Indexing • Extract index key from the component • Index key: a word and the kind of it • No reserved words are extracted • Count frequency in use of the word public final class Sort { /*quicksort*/ private static void quicksort(…) { int pivot; : quicksort(…); quicksort(…); } } Index key frequency
Extract use relations • Extract use relations among components using semantic analysis • Make component graph from use relations • Node: component • Edge: use relation Data public class Test extend Data{ : public static void main(…) { : Sort.quicksort(super.array); : } } Inheritance Field access Sort Test Method call The kind of use relation Component graph
C G C G B F BF A D E E AD Similar component • Similar component is copied component or minor modified component • We merge similar components into single component • Merged component have use relations that all component before merging have C G B F A D E Component graph Clustered component graph
Clustering components • We measure characteristics metrics to merge components • The difference ratio of each component metrics • Metrics • complexity • The number of methods, cyclomatic, etc. • represent a structural characteristic • Token-composition • The number of appearances of each token • represent a surface characteristic
Ranking based on use relation • Component Rank (CR) • Reusable component have many use relation • The example of use is much • General purpose component • Sophisticated component • We measure use relation quantitatively, and rank components • The component used by many components is important • The component used by important component is also important Katsuro Inoue, Reishi Yokomori, Hikaru Fujiwara, Tetsuo Yamamoto, Makoto Matsushita, Shinji Kusumoto: "Component Rank: Relative Significance Rank for Software Component Search", ICSE, Portland, OR, May 6, 2003.
0.34 0.33 0.17 0.17 0.33 0.33 0.33 Propagating weights A B C Ad-hoc weights are assigned to each node
0.33 0.17 0.175 0.175 0.5 0.17 0.5 Propagating weights A B C The node weights are re-defined by the incoming edge weights
0.25 0.25 0.345 0.175 Propagating weights 0.5 0.175 A B 0.345 C We get new node weights
Propagating weights 0.4 0.2 0.2 A B 0.2 0.4 0.2 0.4 C • We get stable weight assignment • next-step weights are the same as previous ones • Component Rank : order of nodes sorted by the weight
Outline • Motivation and research aim • SPARS-J • Outline • System architecture • Ranking method • Each part • Analysis part • Retrieval part • User Interface • Experiment • Conclusion and Future work
Component retrieval part • Search components from database, rank components • The process • Search components • Ranking suited to a user request • Aggregate two ranks (CR and KR)
Search components • Search query • Words a user input • The kind of an index word, package name • Components contain given query are searched from Database
Ranking suited to a user request • Keyword Rank (KR) • Components which contain words given by a user are searched • Rank components using the value calculated from index word weight • Index word weight • Many frequency in use of a component • A word contained particular components • A word represent the component function such as Class name • Sort the sum of all given word weight • TF-IDF weighting using full-text search engine
Calculation of KR value • Calculate weight Wct with component c word t • TFi: The frequency with which a kind i of word t occurs in component c • IDF: the total number of components / the number of components containing word t • kwi: Weight of a kind i • KR value is the sum of all word Wct
Aggregate two ranks • Aggregate two ranks KR and CR • Aggregation method • Borda Count method known a voting system • Use for single or multiple-seat elections • This form of voting is extremely popular in determining awards • SPARS-J • Rank components both KR and CR • Using KR and CR, the component that be suitable user’s request, reusable and sophisticated