Development of a Baseline Tropical Cyclone Model Using the Alopex Algorithm
90 likes | 212 Vues
This research focuses on the improvement of tropical cyclone forecasting through the development of a baseline model utilizing the Alopex algorithm. Skill measurement is conducted via comparisons to benchmark "no-skill" models, relying on essential storm data such as position, intensity, and historical changes. The study enhances existing benchmark models that influence wind radii predictions, optimizing them with Alopex to avoid local minima pitfalls. Results from 5 million iterations showed significant reductions in error, demonstrating the effectiveness of the Alopex method for complex parameter optimization in cyclone forecasting.

Development of a Baseline Tropical Cyclone Model Using the Alopex Algorithm
E N D
Presentation Transcript
Development of a Baseline Tropical Cyclone Model Using the Alopex Algorithm Robert DeMaria
Forecast “Skill” • Skill is measured by comparison to simple benchmark “no-skill” models • Benchmark forecast based on basic storm information • Storm initial position and intensity, previous 12 hour change, and current date • Track and intensity benchmarks developed in 1972 and 1988 • NHC wind radii benchmark model developed at CSU in 2004, but used very simple minimization algorithm • Can benchmark wind radii model be improved using ALOPEX algorithm for minimization?
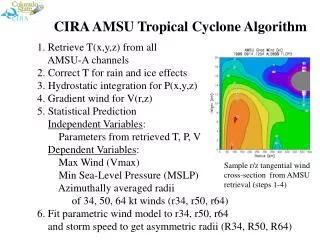
Benchmark Model and Error Function • Benchmark model is a set of parametric equations with a total of 20 free parameters in matrix D • Given azimuth, returns radius of maximum wind • Error function created for optimization of D • E = [(R34-r34)2+(R50-r50)2+(R64-r64)2] + Penalty term • R34,50,64 = observed radii • r34,50, 64 = computed radii • Summation is over ~3000 data point from 1988-2004 • Penalty term becomes large when values of D are non-physical
Previous Minimization Algorithm • Very simple local search • Guaranteed to get stuck in first minima found • Starting point at best guess
Alopex Algorithm • Designed for minimizing error in problems with large number of variables • Does not get stuck in local minima • Very general
Alopex Fundamentals • Iterative • Variables incremented in biased random directions • Correlation computed every iteration for every member of D • correlationi = ΔDi * ΔE • If error after previous iteration reduced, probability of incrementing in same direction is high • If error of previous iteration increased, probability of incrementing in same direction is low • Temperature used to prevent getting stuck in local minima • After N iterations, T set to average correlation of all variables over N iterations
My Implementation • Written in Fortran • Values for N, initial D vals, increment, and penalty term found empirically • Prevents increments that will produce non-physical results
Results • Run for 5 million iterations • Iteration # 329068 found smallest error of ~ 45 nmi • Original algorithm found very similar D matrix with error of ~38 nmi
Future Work • Remove purely physical increment limitation • Run with more iterations • Run with different starting location • Fine tune using result as starting location smaller increment