Domain-Based Protein-Protein Interaction Prediction Using Random Decision Forest Framework
10 likes | 191 Vues
Domain-Based Protein-Protein Interaction Prediction Using Random Decision Forest Framework Xue-wen Chen (xwchen@ku.edu) and Mei Liu (meiliu@ittc.ku.edu). Motivation: Proteins interact with other proteins to perform various functions in cellular processes and biochemical events.

Domain-Based Protein-Protein Interaction Prediction Using Random Decision Forest Framework
E N D
Presentation Transcript
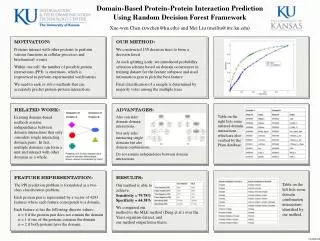
Domain-Based Protein-Protein Interaction Prediction Using Random Decision Forest Framework Xue-wen Chen (xwchen@ku.edu) and Mei Liu (meiliu@ittc.ku.edu) Motivation: Proteins interact with other proteins to perform various functions in cellular processes and biochemical events. Within one cell, the number of possible protein interactions (PPI) is enormous, which is impractical to perform experimental verifications. We need to seek in silico methods that can accurately predict protein-protein interactions. Our method: We constructed 150 decision trees to form a decision forest. At each splitting node, we introduced probability selection scheme based on domain occurrences in training dataset for the feature subspace and used information gain to pick the best feature. Final classification of a sample is determined by majority votes among the multiple trees. Related Work: Existing domain-based methods assume independence between domain interactions that only considers single interacting domain pairs. In fact, multiple domains can form a unit and interact with other domains as a whole. Advantages: Also can infer domain-domain interactions. Not only infer interacting single domains but also domain combinations. Do not assume independence between domain interactions. Table on the right lists some inferred domain interactions which are also verified by the Pfam database. • Feature representation: • The PPI prediction problem is formulated as a two-class classification problem. • Each protein pair is represented by a vector of 4293 features where each feature corresponds to a domain. • Each feature xi has the following discrete values: • xi = 0 if the protein pair does not contain the domain • xi = 1 if one of the proteins contains the domain • xi = 2 if both proteins have the domain. Results: Our method is able to achieve: Sensitivity = 79.78% Specificity = 64.38% We compared our method to the MLE method (Deng et al.) over the Yeast organism dataset, and our method outperforms theirs. Table on the left lists some domain combination interactions identified by our method.


















