
SMP Systems
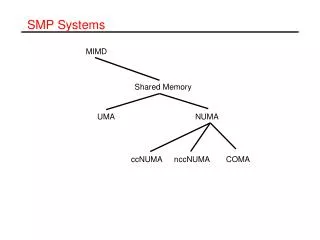
SMP Systems. MIMD. Shared Memory. UMA. NUMA. ccNUMA. nccNUMA. COMA. Uniform Memory Architectures (UMA). UMA or Symmetric Multiprocessors (SMP) are shared memory systems with the following characteristics global physical address space

SMP Systems
E N D
Presentation Transcript
SMP Systems MIMD Shared Memory UMA NUMA ccNUMA nccNUMA COMA
Uniform Memory Architectures (UMA) • UMA or Symmetric Multiprocessors (SMP) are shared memory systems with the following characteristics • global physical address space • symmetric access to all main memory from any processor, i.e. same latency for accesses • SMPs dominate the server market and are becoming more common at the desktop. • Throughput engines for sequential jobs with varying memory and CPU requirements. • Shared address space makes SMPs attractive for parallel programming. Efficient automatic parallelizers are available for those systems. • They are important building blocks for larger-scale systems.
Memory Semantics of a Sequential Computer • One program • A read should return the last value written to that location. • Operations are executed in program order. • Multiple programs • Time sharing • Same condition for read operations • Operations are executed in some order which respects the individual program order of the programs. • The hardware makes sure that the semantics is enforced taking into account: • write buffers • cache • ...
Cache Coherence Problem 5 3 4 u: 5 u: 5 u: 7 1 2 • Replicas in the caches of multiple processors in an SMP have to be updated or kept coherent. P1 P2 P3 Cache Cache Cache Memory u: 5
Observations • Write-through cache • P1 reads old value from own cache, P2 reads new value • Write-back cache: • P1 and P2 read old value from cache and memory respectively. • With multiple new values in caches of different processors the final value in memory is determined by the order of flushing the cache instead of the order in which the writes occurred.
Cache Coherence Problem in Sequential Computers • The problem occurs in the context of IO operations. • The DMA accesses data in the memory independent of the processor cache. • Coarse solutions have been developed based on the fact that IO operations occur much less frequent than memory operations. • Mark address ranges as uncacheable • Flush cache before starting IO operations • IO operations go through cache hierarchy
Definition of a Coherent Memory System • A multiprocessor memory system is coherent if the result of any execution of a program is such that, for each location, it is possible to construct a hypothetical total order of all memory accesses that is consistent with the result of the execution and in which • operations by any particular process occur in the order they were issued, and • the value returned by each read operation is the value written by the last write to that location in the total order.
Cache Coherence in a Bus-based SMP • Key properties: • Cache controllers can snoop on the bus. • All bus transactions are visible to all cache controllers. • All controllers see the transaction in the same order. • Controllers can take action if a bus transaction is relevant, i.e. involves a memory block in its cache. • Coherence is maintained at the granularity of a cache block.
Protocols • Invalidation protocols • invalidate replicas if a processor writes a location. • Update protocols • update replicas with the written value. • Based on • Bus transactions with three phases • Bus arbitration • Command and address transmission • Data transfer • State transitions for a cache block • State information (e.g. invalid, valid, dirty) is available for blocks in a cache. • State information for uncached blocks is implicitly defined (e.g. invalid or not present).
Definition of a Snooping Protocol • A snooping protocol is a distributed algorithm represented by a collection of cooperating finite state machines. It is specified by the following components: • the set of states associated with memory blocks in the local caches • the state transition diagram with the following input symbols • Processor requests • Bus transactions • actions associated with each state transition The different state machines are coordinated by bus transactions.
Protocol Ensures Coherence • Determine total order such that it gives the same result and in which: • Operations by any particular process occur in the order they were issued. • The value returned by each read operation is the value written by the last write to that location in the total order.
Drawback of Write-Through Caches • Every store instruction goes to memory. • Example: • Processor with 2GHz executing one instruction per cycle. • 15% of all instructions are stores for 8bytes of data. • Bus has a 3.2 GB/s bandwidth (400 MHz, 8 Byte) 300 million stores per second, requiring 2.4 GB/s bandwidth one processor saturates bus ignoring read misses, address information ... • Write-back cache reduces load on the bus by writes • Writes are not seen at the bus and therefore more sophisticated protocols are required.
Requirements for Memory Consistency (1/2) P0 P1 Assume intial value of A and flag is 0 while (flag==0);print A; A=1;flag=1; P0 P1 Assume intial value of A is 0 barrier(b1); print A; A=1;barrier(b1); • Memory coherence defines only properties for accesses to a single location. • Programs need, in addition, guaranteed properties for accesses to multiple locations.
Requirements for Memory Consistency (2/2) P0 P1 P2 Assume intial value of A and B is 0 a=1 if (a==1) b=1 fi if (b==1) reg=a fi • The programmer expects atomic execution of write operations. • If a new value is assigned to the register in P2, this value should be 1.
Memory Consistency Model • It specifies constraints on the order in which memory operations become visible to the other processors. • It includes operations to the same location and to different locations. • Therefore, it subsumes coherence. • The software and hardware have to agree on the rules, i.e., it can be seen as a contract.
Memory Consistency P0 P1 P2 Assume intial value of A, B, C is 0 and D is 5 a=1 if (a==1) b=1 fi if (b==1) c=3 d=a fi
Strict Consistency P0 P1 P2 Assume intial value of A, B, C is 0 and D is 5 a=1 if (a==1) b=1 fi if (b==1) c=3 d=a fi • A read returns value of most recent write. • Easy model for programmers but hinders many optimizations.
Sequential Consistency P0 P1 Pn Memory • Definition (Lamport 1979): • A multiprocessor is sequentially consistent if the result of any execution is the same as if • the operations of all the processors were executed in some sequential order, • and the operations of each individual processor occur in this sequence in the order specified by its program. • Two constraints: • program order and atomicity of memory operations.
Sequential Consistency • Impossible • P3 gets (100, 200) and • P4 gets (200, 100) P1 P2 P3 P4 R3 x R3 x R4 x R4 x W2 200 W1 100 X W1 100 W2 200 R3 200 R3 200 R4 200 R4 200 W1 100 R3 100 W2 200 R4 200 R3 200 R4 200 W2 200 R4 200 W1 100 R3 100 R4 100 R3 100
Sequential Consistency P0 P1 P2 Assume intial value of A, B, C is 0 and D is 5 a=1 if (a==1) b=1 fi if (b==1) c=3 d=a fi
Processor Consistency P0 P1 P2 Assume intial value of A, B, C is 0 and D is 1 a=1 if (a==1) b=1 fi if (b==1) c=3 d=a fi • Goodman, 1989 • Rules • Writes by a CPU are seen by all CPUs in the order they were issued. • For every memory word, all CPUs see all writes to it in the same order.
Processor Consistency P0 P1 P2 Assume intial value of A, B, C is 0 and D is 5 a=1 if (a==1) a=2 b=1 fi if (b==1) c=3 d=a fi
Weak Consistency • Dubois et al., 1986 • Rules • Does not guarantee that writes from single CPU are seen in order. • Synchronization operations finish all pending memory operations • Holds all new ones until sync is done • Some order of syncs is chosen and seen by all CPUs
Weak Consistency P0 P1 P2 Assume intial value of A, B, C is 0 and D is 5 a=1 if (a==1) a=2 b=1 fi if (b==1) c=3 d=a fi
Weak Consistency with Sync P0 P1 P2 Assume intial value of A, B, C is 0 and D is 5 a=1 sync if (a==1) a=2 b=1 fi sync sync if (b==1) c=3 d=a fi Sequence of Epochs Epoch 1 Epoch 2
Basic MSI Writeback Invalidation Protocol • States • Invalid (I) • Shared (S): one or more • Dirty or Modified (M): one only • Processor Events: • PrRd (read) • PrWr (write) • Bus Transactions • BusRd: asks for copy with no intent to modify • BusRdX: asks for copy with intent to modify • BusWB: updates memory • Actions • Update state, perform bus transaction, flush value onto bus
State Transition Diagram • Write to shared block: • Already have latest data; can use upgrade (BusUpgr) instead of BusRdX
MESI (4-state) Invalidation Protocol • Problem with MSI protocol • Reading and modifying data is 2 bus transactions, even if no one is sharing • e.g. even in sequential program • BusRd (I->S) followed by BusRdX or BusUpgr (S->M) • Add exclusive state • Allows write without bus transaction • Not yet modified
MESI Protocol • States • invalid • exclusive or exclusive-clean (only this cache has copy, but not modified) • shared (two or more caches may have copies) • modified (dirty) • I -> E on PrRd if no one else has copy • needs “shared” signal on bus: wired-or line asserted in response to BusRd • The MESI protocol implements sequential consistency.
Classification of Cache Misses • Compulsory (Cold) misses • occur on the first reference to a memory block by a processor. • Capacity misses • occur when not all of the blocks that are referenced by a processor fit in the cache, so some are replaced and later accessed again.
Classification of Cache Misses • Conflict (Collision) misses • occur in a cache with less than full associativity when the collection of blocks referenced by a program that maps to a single cache set does not fit in the set. • Coherence misses • occur when blocks of data are invalidated due to the coherence protocol. • True sharing misses occur when a data word produced by one processor is used (read or written) by another. • False sharing misses occur when independent data words accessed by different processors happen to be placed in the same cache block, and at least one of the accesses is a write.
Cache-Coherent NUMA Computers • Scalable machine, like CRAY T3E, disable caching of remote addresses. • Every access goes over the network or • Programmer responsible to keep copies coherent. • Requirements for implicit caching and coherence on physically distributed memory machines: • Latency and bandwidth scale well • Protocol scales well • In contrast to cache-only memory architectures (COMA), the home location of an address is fixed. • Focus will here be on hardware-based directory-based cache coherence. • A directory is a place where the state of a block in the caches is stored.
Simple Directory-Based Cache Coherence Protocol • Single writer - multiple reader • Cache miss leads to transaction to home of the memory block • Remote node checks state and performs protocol actions • Invalidating copies on write • Returning value on read • All requests, replies, invalidations etc. are network transactions • Questions: • How is the directory information stored? • How may efficient protocols be designed?
Classification of Directory Implementations Directory Storage Schemes Finding source of directory information Centralized Hierarchical Flat Hierarchy of caches with inclusion property. Memory-based Cache-based Information co-located with memory block that is home of that location Caches with a copy form a linked list. Memory holds head pointer only. Locating Copies
Protocol Scalability • Precondition for application: Small number of sharers • Performance depends on • Number of transactions (bandwidth requirements) • Number of transactions on the critical path (latency) • Storage overhead • It can be quite severe since presence bits scale linearly with memory size and number of processors • Example: Block size 64 byte
Properties of Hierarchical Schemes • Advantages: • Transactions need not go to home • Multiple requests from different nodes can be combined • Disadvantages: • Number of transactions to traverse tree might be greater than in flat schemes. • If startup costs are high, this is worse than traversing long distance • Each transaction needs to look up the directory information which increases latency of transactions. • Summary • Hierarchical schemes are not popular due to latency and bandwidth characteristics. • They have been used in systems providing data migration
Flat Memory-based Directory Schemes • Properties • The number of transactions to invalidate sharers is proportional to the number of sharers. • The invalidation transaction can be overlapped or sent in parallel so that latency is reduced. • The main disadvantage is the memory overhead • Reduction of memory overhead: • Increase cache-line size • Increase number of processors per directory (two-level protocol) • Example: • Four processor nodes and 128 byte cache blocks lead to only 6.25% on a 256 processor system instead of 50%. • Overhead is still proportional to P*M (P is the number of processors and M is memory size)















