Download

1 / 37
370 likes | 390 Vues
Learn about the transition from MDP to POMDP, information state, value functions, and constructing Information State MDP for decision-making in uncertain environments.

E N D
(Chapter 3 of)Planning and Control in Stochastic Domains with Imperfect Informationby Milos Hauskrecht CS594 Automated Decision Making Course Presentation Professor: Piotr. Kaidi Zhao Ph.D. Candidate of Computer Science Dept. UIC.
Agenda • Brief review of the MDP • Introduce the POMDP • Information State MDP • Information State • Value functions. • Construct Information State MDP • Forward Triggered • Backward Triggered • Mixed • Delayed • Summary and Review
Brief review of the MDP • Formally, MDP model is a 4-tuple (S, A, T, R) where: • S is a finite set of world states • A is a finite set of action • T: S x A x S [0, 1], define the transition probability distribution P(s|s’, a) that describes the effect of actions on the world state • R: S x A x S R defines a reward model that describes payoffs associated with a state transition under some action • So what is MDP missing?
Brief review of the MDP • Where MDP plays: • Requires a perfectly observable states. • Can be uncertain about possible outcomes of its action, but requires clear aware of the state that the agent is now in. ~~~~~However, real life is not that easy~~~~~ • Where POMDP plays: • Uncertainty about the action outcome • Uncertainty about the world state due to imperfect (partial) information
Agenda • Brief review of the MDP • Introduce the POMDP • Information State MDP • Information State • Value functions. • Construct Information State MDP • Forward Triggered • Backward Triggered • Mixed • Delayed • Summary and Review
POMDP • Partially observable Markov decision process is defined as (S, A, , T, O, R) • S corresponds to a finite set of world states • A is a finite set of actions • is a finite set of observations • T: S x A x S [0, 1] defines the transition probability distribution P(s|s’, a) that describes the effect of actions on the state of the world • O: x S x A [0, 1] defines the observation probability distribution P(o|s, a) that models the effect of actions and states on observations • R corresponds to the reward models S x A x S R that models payoffs incurred by state transitions under specific actions Reminder: MDP is (S, A, T, R)
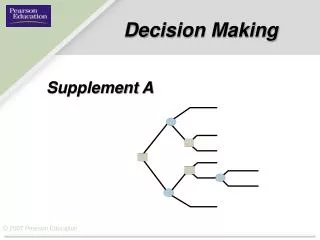
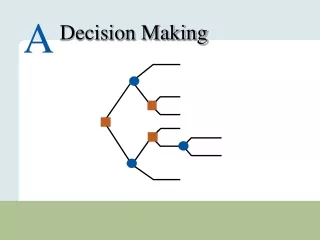
Influence Diagrams POMDP: Reminder: MDP is:
Information State • Since in POMDP the underlying process state is not known with certainty and can be only guessed based on past observations, actions and any prior information available, we need to differentiate between the “true process state” and the “information (perceived) state”.
Agenda • Brief review of the MDP • Introduce the POMDP • Information State MDP • Information State • Value functions. • Construct Information State MDP • Forward Triggered • Backward Triggered • Mixed • Delayed • Summary and Review
Information State • An information state represents all information available to the agent at the decision time that is relevant for the selection of the optimal action. • The information state consists of either a complete history of actions and observations or corresponding sufficient statistic.
Information State MDP • A sequence of information states defines a Markov controlled process in which every new information state is computed as a function of the previous information state, the previous step action and new observations seen: • The process defined over information states is called information state MDP.
Information State MDP POMDP with info. states Information State MDP Reminder: POMDP MDP
Info. State Representation 1/3 • Complete Information State (): consists of all information available to the agent before the action at time t is made. It consists of: • Prior belief on states at time 0 • All observation available up to time t • All actions performed before time t
Info. State Representation 1/3 • Major hindrance: expanding dimension and size. • Replace complete information states with quantities that represent sufficient statistics with regard to control. • These quantities satisfy the Markov property and preserve the information content of the complete state that is relevant for finding the optimal control.
Info. State Representation 2/3 • Sufficient Information State process: Let P={I0, I1, …, It, …} be a sequence of information vectors describing the information process. The P is a sufficient information process with regard to the optimal control when for every component It in P holds:
Info. State Representation 3/3 • Belief States as Sufficient Info. States: The quality often used as a sufficient statistic in POMDPs is the belief state. The belief state assigns probability to every process state and reflects the extent to which states are believed to be present. The belief vector bt at time t corresponds to:
Value Functions • Value functions for MDP can be directly applied to Information State MDP For the n steps-to-go value function for some fixed plan: (Reminder:MDP)
Value Functions • Expected one step cost for an information state In and an action a is: • A next step information state In-1 is: • Rewrite the value function to:
Value Functions • Optimal value function for finite n-steps-to-go problem is: • The optimal control functions is: • Optimal value function for infinite discounted horizon problem is: • Optimal control function is:
Value Function Mappings • Basic value function equations can be written also in the value function mapping form. Which enable us to represent the value function as:
Agenda • Brief review of the MDP • Introduce the POMDP • Information State MDP • Information State • Value functions. • Construct Information State MDP • Forward Triggered • Backward Triggered • Mixed • Delayed • Summary and Review
Forward Triggered Observation • POMDP with standard (forward triggered) observations, assume an observation depends solely on the current process state and the previous action. Q: Can info. state MDP be sufficiently represented using belief state?
Forward Triggered Observation • Yes! The sufficient information state process by definition should satisfy the following:
Backward Triggered Observation • POMDP with backward triggered observation: An action at performed at time t causes an observation about the process state st to be made -- the action performed at time t enables the observation that refers to the “before action” state. Major cause: time discretization. Which state is better approximated by a new observation? The state that occurred after or before the action.
Backward Triggered Observation • The belief update for an action a t-1 and an observation that is related to the state at time t-1 but observed (made available) at time t is:
Forward &Backward Combined • Two previous models can be combined. The observation model consists of two groups of observations. • One group is triggered in the forward and the other in the backward fashion. • Assume the observations associated with the same state are independent given that state.
POMDP with Delayed Observation • How it comes? • An action issued by an agent at time t will be performed at time t+k. • An observation made at time t will become available to the agent at time t+k. • In the next example model: • Observations are triggered backwards • Observations with different time lags are assumed to be independent given the process state • At every time t the agent can expect to receive results related to at most k past process states
POMDP with K-step Delayed Observation Reminder: where where Reminder: It violates the third prerequisite of sufficient information state process. We need to do some convert.
POMDP with K-step Delayed Observation • Observation vector: let be a contribution to the belief state at time t-i that comes from observation related to that state and that were made up to time t: • Prior belief vector: let be a contribution to the belief state at time t-i from all actions made prior to that time, related observations made up to time t, and prior belief at time t = 0:
POMDP with K-step Delayed Observation • Belief state at time t: • Which enable us to convert the POMDP model to the information state MDP.
Agenda • Brief review of the MDP • Introduce the POMDP • Information State MDP • Information State • Value functions. • Construct Information State MDP • Forward Triggered • Backward Triggered • Mixed • Delayed • Summary and Review
Summary and Review • Q1: what uncertainty different POMDP from MDP? • I use several questions to summary my presentation.
Summary and Review • A1: uncertainty about the world state due to imperfect (partial) information. • Q 2: What is “information state”?
Summary and Review • A 2: An information state represents all information available to the agent at the decision time that is relevant for the selection of the optimal action. • Q 3: What are the value functions for the information state MDP?
Summary and Review • A 3: We can apply value functions from MDP to information state MDP. • Q 4: Which one is backward triggered observation?
Summary and Review • A 4: The left one. Thanks for attending my presentation!