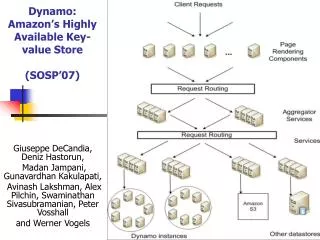
Search with a Key-Value Store
Dive into the world of NoSQL with a focus on key-value stores. Learn about the schemaless design, distributed architecture, and eventual consistency that make these databases ideal for handling large datasets. Discover how to model data effectively in platforms like MongoDB, and understand the key considerations for embedding and indexing data for optimal performance. This guide also contrasts traditional SQL data loading methods with NoSQL approaches, highlighting the efficiency of data retrieval and the benefits of automatic sharding and powerful indexing capabilities.


Search with a Key-Value Store
E N D
Presentation Transcript
Intro to NoSQL • Key-value store • Schemaless • Distributed • Eventually Consistent
Key-Value • Single unique key for each value in the database • Extremely fast look-up • Easy distribution (no such thing as joins)
Schemaless • Critical for extremely large data sets • No alter table commands, each value has no pre-defined fields
Distributed • Data set is designed to be shared across multiple machines • Typically makes use of commodity servers with enough RAM to keep the entire data set in memory
Eventually Consistent • Replica nodes are not notified of changes before a success response is returned to the client • Makes NoSQL problematic for highly sensitive transactions (finance, etc)
Database Design in NoSQL • Denormalization is your friend • Think of collections as views on a data set that
Loading a Story with SQL SELECT * FROM comments LEFT JOIN users ON users.id = comments.user_id LEFT JOIN comments children ON children.parent_id = comments.id WHERE story_id = x SELECT * FROM stories
Redesigned in a NoSQL Data Store Story #dgi3ck date headline content comments Comment #la529 content username user_image_url user_id children Comment #mn34i content username user_image_url user_id Comment #5bg26 content username user_image_url user_id children
Loading a Story with NoSQL Stories::get(dgi3ck)
Some Design Considerations • What is the context in which we will access this data? • What data do we need to access outside the of this context? • How often does the data change?
Embedded Data • NoSQL can support foreign keys • Some data is more appropriately stored “embedded” in a parent context • E.g. Comments are rarely (if ever) accessed outside of their parent Story
Cached Data • Data from an object that needs to be accessed outside of the current context can be cached • Keep in mind that it may need to be updated • E.g. a user changes his username, Comments can be updated
Several common NoSQL Stores • Memcached • BigTable • SimpleDB • MongoDB
Why we chose MongoDB • Auto-sharding and easy setup for distribution • JavaScript API • Powerful indexing capabilities
MongoDB Libraries • ORM: mongo_mapper • https://github.com/jnunemaker/mongomapper • Underlying Connection: mongo • https://github.com/mongodb/mongo-ruby-driver • BSON support: bson_ext • http://rubygems.org/gems/bson_ext
Lifebooker’s Availability Search • Searches across Services • Filters • Time/Date • Geographical Zone • Service Category • Practitioner Gender • Concurrent Availability • (and several more)
Services, Discounts and Practitioners • Services are offered by Providers • Providers have Practitioners (Employees) • Discounts are applied to Providers for a Service in a given time
Indexing and Searching • Mongo offers powerful indexing capabilities • Arrays are “first-class citizens” • Complex indices allow for great performance
Creating Meta-Data • With complex data structures, creating meta-data before_save will allow you to make that data easily searchable • E.g. the maximum discount on a given day for a service
Querying • Uses DataMapper/Arel Syntax • Chains conditions, ordering and offset
Filtering Complex Data Structures • MongoDB offers a JavaScript API for MapReduce • Map - transform and filter data • Reduce - combine multiple rows into a single record
Using MapReduce to Filter Filter
The Results • Scheduled to go live within 2 weeks • With sharding/distribution, tests show almost no dip in response time with more than 10x the current data set • 20x faster than MySQL implementation • 100ms vs 2000ms (or more)