Audio Segregation
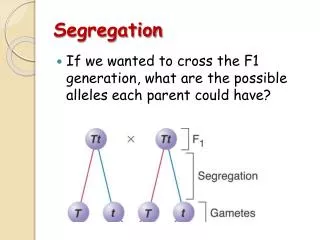
Audio Segregation. 2010. 4. 26. Hyung-Min Park. Contents. Independent component analysis (ICA) Conventional methods for acoustic mixtures Filter bank approach to ICA Degenerate unmixing and estimation technique (DUET) Target speech enhancement Zero-crossing-based binaural processing


Audio Segregation
E N D
Presentation Transcript
Audio Segregation 2010. 4. 26. Hyung-Min Park
Contents • Independent component analysis(ICA) • Conventional methods for acoustic mixtures • Filter bank approach to ICA • Degenerate unmixing and estimation technique (DUET) • Target speech enhancement • Zero-crossing-based binaural processing • Inter-aural time difference (ITD) • Zero crossings vs. cross-correlation • Continuously-variable mask vs. binary mask
Blind Source Separation: A Demo ? mixing environment initial system sources and the mixing environment
Independent Component Analysis • Blind source separation • Sensor signals • Recover the original source signals without knowing how they are mixed • ICA • Assume sources are independent • Estimate the unmixing system W from mixtures x(t) u W x A s
Acoustic Mixtures • Instantaneous mixtures • Acoustic mixing environments • Time delay • Reverberation • Convolutive mixing sources s1 s2 x1 x2 sensors Wall
u1(n) x1(n) W11 W21 W12 x2(n) u2(n) W22 Time Domain Approach to ICA • Feedback architecture • Adaptation rules (Torkkola, 1996) • Intensive computations and slow convergence
Frequency Domain Approach to ICA (1) • In the frequency domain • Complex score function • Adaptation rule (Smaragdis, 1998) W1 Short- Time Fourier Transform Inverse Short- Time Fourier Transform x1(n) u1(n) W2 xN(n) uN(n) WK
kth block kth block s1(n) s2(n-d1) = + x1(n) d2 s1(n-d2) s2(n) d1 = + x2(n) Frequency Domain Approach to ICA (2) • Performance limitation • Contradiction between long reverberation covering and insufficient learning data • Long reverberation long frame size • Small number of frames insufficient input data • Mixtures combined from different time ranges of sources • Delayed mixtures
Design of a Filter Bank • Filter bank design • Frequency response of analysis filters Uniform sixteen-channel filter bank Decimation factor: 10 Filter length: 220 taps
H1(z) M M F1(z) ICA network W1(z) H2(z) M M F2(z) x1(n) u1(n) ICA network W2(z) HK(z) M M FK(z) H1(z) M M F1(z) H2(z) M M F2(z) x2(n) u2(n) ICA network WK(z) HK(z) M M FK(z) Filter Bank Approach to ICA (1) • 2x2 network for the filter bank approach to ICA
Filter Bank Approach to ICA (2) • Adaptation rules • Total number of multiplications • Time domain approach • Filter bank approach • The number of required filter coefficients • Uniform K-channel oversampled filter bank is the number of adaptive filter coefficients
Experimental Setup (1) • Measure for blind source separation • SIR for a 2x2 mixing/unmixing system • Sources • Two streams of speech • 5 second length • 16 kHz sampling rate
Experimental Setup (2) • Mixing system Virtual room to simulate impulse responses
Experimental Results • Learning curves of the three different approaches
Experiment on Real-Recorded Data (1) • Mixing environment • Filter bank approach • Using the sixteen-channel filter bank • Each adaptive filter: 103 taps 40cm Microphones 60cm Speakers
Experiment on Real-Recorded Data (2) • Blind source separation of real recorded mixtures Mixture 1 Mixture 2 Result 1 Result 2 stop
Motivation of a Nonuniform Filter Bank Approach • Time-averaged magnitude responses of signals • The energy exponentially decreases as the frequency increases. Speech Car noise Music • Subband division • Result of trade-off between mitigation of undesired properties of the uniform filter bank approach and that of large adaptive filter length
Relationship between Performances and Filter Length • Convergence of gradient-based algorithms • Controlled by condition number • Bordering theorem • Condition number • Monotonically nondecreasing function of filter length • The longer filter length • The slower convergence speed and
Bark-Scale Filter Banks • Subband division • Result of trade-off between mitigation of undesired properties of the uniform filter bank approach and that of large adaptive filter length • Bark frequency warping function • Bark-scale filter banks • Resemble that of the mammalian cochlea • Somewhat narrow subbands in low frequency region • Wide subbands in high frequency region
H1(z) M1 M1 F1(z) ICA network W1(z) H2(z) M2 M2 F2(z) x1(n) u1(n) ICA network W2(z) HK(z) MK MK FK(z) H1(z) M1 M1 F1(z) H2(z) M2 M2 F2(z) x2(n) u2(n) ICA network WK(z) HK(z) MK MK FK(z) Nonuniform Filter Bank Approach to BSS • 2x2 network for the nonuniform oversampled filter bank approach to BSS
Design of a Bark-Scale Filter Bank • Filter design of a Bark-scale oversampled filter bank • 16-channel, , OSR=167% Bark-scale filter bank Uniform filter bank
Experimental Results • Results on blind source separation in the oversampled filter bank SIR PESQ score
female speech noises noise references microphones mic. signals outputs male speech FPGA Implementation (1)
FPGA Implementation (2) • 4 adaptive noise canceling (4 music signals) + 2 blind source separation (2 speech signals) MIC1 MIC2 OUT1 OUT2 stop
output SNR=21.38dB Application to Hearing Aids front mic. SNR=3.20dB • BTE-type hearing aids 1m 1m rear mic. SNR=2.45dB noise speech front mic. rear mic. stop
Discussion on ICA • Assume sources are independent • Time domain approach • Intensive computations and slow convergence • Frequency domain approach • Less computations but inferior performance • Filter bank approach • Moderate computations and good performance • Suitable for parallel processing • Bark-scale filter bank approach
Introduction • Independent component analysis for blind source separation • Good performance • In general, the number of microphones should not be smaller than the number of sources. • Too many parameters • Heavy computational load and slow convergence • Problem with a source which is active in a short period
Binaural Processing • Auditory scene analysis (ASA) • Cues: harmonics, pitch, on-set, etc • Spatial cues • Inter-aural time difference (ITD) • Inter-aural intensity difference (IID) target noise
DUET Algorithm (1) • Mixing model • In the time-frequency domain
DUET Algorithm (2) • W-disjoint orthogonality assumption • Parameter estimation
DUET Algorithm (3) • 2D Histogram of amplitude-delay estimates from two mixtures of five sources ♦Amplitude parameters ( .98, 1.02, .93, 1.06, .93) ♦ Delay parameters ( .3, -.2, .8, -.7, -.2)
DUET Algorithm (4) • If the j-th source is active, • Cost function • Parameter estimation • Stochastic gradient descent algorithm
DUET Algorithm (5) 1 0 0 1 1 1 1 1 0 1 0 0 1 0 0 0 1 1 1 1 0 1 1 1 0 0 1 0 0 0 0 0 0 1 0 1 0 1 0 1 • Mask • Demixing s1 s2
Target Speech Enhancement • In many practical applications, • Need to estimate a signal from a target source • The target source • Frequently, we can expect its approximated direction. • Strong utterance in a noisy environment
Proposed Method (1) • Continuously variable mask • Real mask Continuously variable mask Real mask
Proposed Method (2) • Determine a threshold. • Using a top ranking • Binary mask using a threshold Binary mask Real mask
Proposed Method (3) Initial continuous mask Thresholding • Overall procedure • Overall procedure of the DUET algorithm Thresholding Comparing likelihoods STFT Attenuation -delay histogram Initializing attenuation -delay parameters Learning attenuation -delay parameters Continuous mask Binary mask ISTFT Attenuation -delay histogram Initializing attenuation -delay parameters Learning attenuation -delay parameters Binary mask STFT STFT ISTFT STFT
Experimental Setup (1) • Number of sources : 2 (1 target source and 1 noise source) • Input SIR : 5 dB • Simulated mixing in an anechoic environment -10 ˚ 20 ˚ 50cm • Source signals • 10-second-long speech signals uttered by 4 males and 4 females in the TIMIT database • Microphones • Space: 2 cm • Angle differences between two sources • 30˚, 60˚, 90˚, 120˚, 150˚, and 180˚ -40 ˚ 80˚ 50 ˚ -70 ˚ Mic1 Mic2 -100 ˚
Experimental Results (1) DUET Proposed method 22.03 21.96 22.03 22.11 21.09 20.63 13.82 13.77 13.79 13.61 10.99 9.17 98.35 98.34 98.26 97.24 96.26 95.38 96.26 89.87 89.79 89.53 89.55 89.55 89.51
Experimental Setup (2) • Number of sources : 2 (1 target source and 1 noise source) • Input SIR : 5 dB • Real recorded mixtures in a normal office room 50cm • Source signals • 10-second-long speech signals uttered by 3 male and 3 female speakers in the TIMIT database • Microphones • Space: 2 cm • Angle differences between two sources • 30˚, 60˚, 90˚, 120˚, 150˚, and 180˚ 0 ˚ 90˚ -30 ˚ 30 ˚ -60 ˚ 60 ˚ Mic1 Mic2 -90 ˚
Experimental Results (2) DUET Proposed method 15.93 15.92 15.99 14.88 12.70 12.57 12.46 11.49 10.99 10.02 6.29 5.51 96.93 97.14 97.03 85.81 84.67 85.14 83.90 83.37 81.77 80.02 76.67 72.27
Discussion on DUET • DUET(Degenerate Unmixing and Estimation Technique) • Simple • We should know the number of sources in advance. • Estimate the attenuation and delay parameters for all sources. • Described target speech enhancement technique • Estimate the parameters for only one target source • Much faster convergence of all the required parameters • Not robust to reverberation
Binaural Processing • Auditory scene analysis (ASA) • Spatial cues: ITD, IID • Others: harmonics, pitch, on-set, etc • Conventional methods • Inter-aural cross-correlation • Binary mask (all-or-none) • Developed method • Inter-aural zero-crossing difference • Continuously variable mask target noise
Jeffress’ Model running interaural cross-correlation running integration multiplication right ear left ear
Source Localization Based on Cross-Correlation • Signal model for the sensor outputs • ITD estimation based on generalized cross-correlation • Phase transform (PHAT)
two microphones Finding Zero-Crossings ITD