
Enhancing Knowledge Management through Semantic Web Integration and Efficient Caching Solutions
E N D
Presentation Transcript
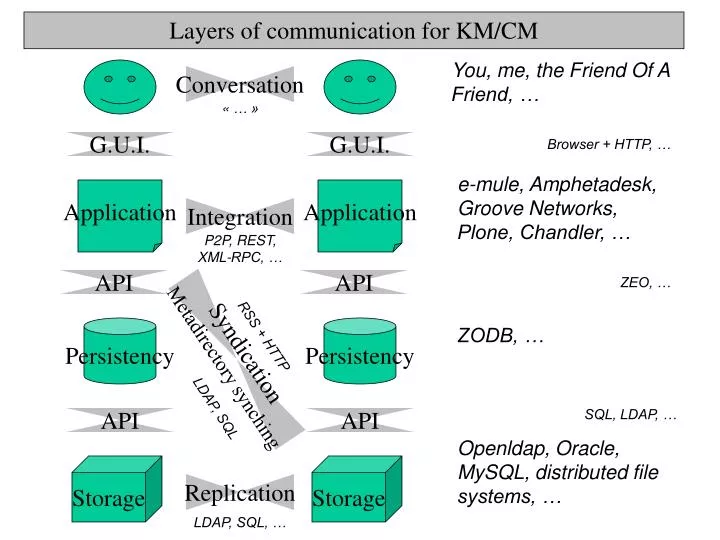
Layers of communication for KM/CM Conversation You, me, the Friend Of A Friend, … « … » G.U.I. G.U.I. Browser + HTTP, … Integration e-mule, Amphetadesk, Groove Networks, Plone, Chandler, … Application Application P2P, REST, XML-RPC, … Syndication Metadirectory synching API API ZEO, … Persistency Persistency ZODB, … RSS + HTTP LDAP, SQL SQL, LDAP, … API API Openldap, Oracle, MySQL, distributed file systems, … Replication Storage Storage LDAP, SQL, …
FS or DBcode Networkcode HD or DB Internet Storing Retrieving CallingTalkingAnswering CachingUpdating Needs for bandwidth Appcode RAM Brain Brain Needs for caching One key for an efficient semantic web should be solutions for synchronizing RDF repositories that could be used as caches. Building a universal model for knowledge/RDF caches be them in-brain, in-RAM, on-HD, in-DB, in-WAN, … Could we do it ? Should we do it ?
Rating, Annotating, Categorizing, Classifying, Commenting, Marking, Describing, Qualifying, Targeting at sbdy= « MEANING » (as « building semantics ») Picking/Droping in a tree UI for meaning Filling a form Mean Recommendation engine Evaluate Validate Browse View Watch Filter Publish/Send Subscribe Query Recommendation engine Workflow example for semantically enhanced KM applications
private hide reject visible show retract pending submit published publish Plone default workflow (for CMFNewsItem as example)
Raw news entry built from an external source by the RSS feeder CMFNewsFeed To store & forget private hide Temp. entry built as a list of links found in another news reject My actions Final news entry for my blog visible show retract To read News entry to notify to someone for his/her own blog pending submit To print & read & evaluate for action published publish To explore visible(news item) archive explore To qualify & comment Adapted Plone workflow (for watching & blogging) visible (news item) prepare blog entry published To notify to someone publish pending (news item) visible (news item) Prepare notification submit