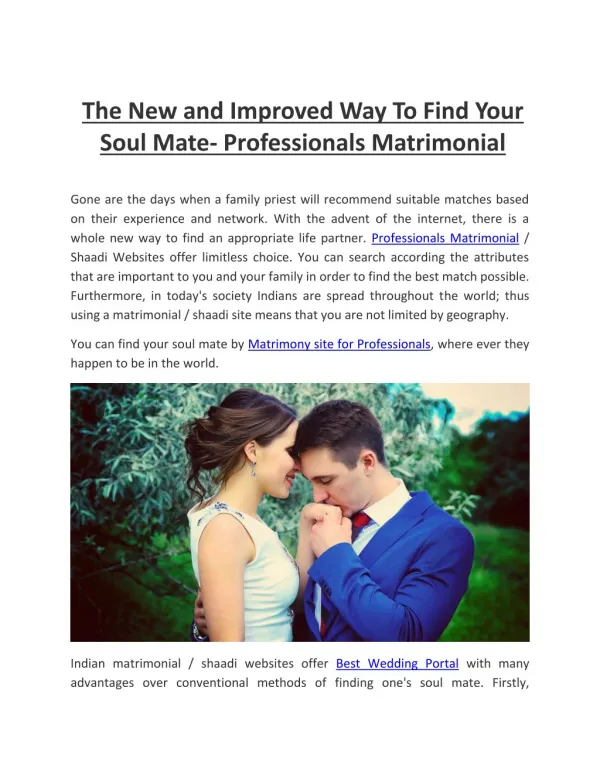
Download

1 / 22
220 likes | 237 Vues
This research paper explores the architecture and mechanism of inter-operating grids through delegated matchmaking. It aims to provide a scalable and efficient solution for inter-operating cluster-based grids. Experimental results and future work are also discussed.

E N D
Inter-Operating Grids through Delegated MatchMaking Todd Tannenbaum, Matt Farrellee, Miron Livny Alexandru Iosup, Dick Epema CS Dept., U. Wisconsin-Madison, US PDS Group, TU Delft, NL
Outline • Grid Inter-Operation: Motivation and Goals • Evaluation of the e-Science Computational Demand • Why Grid Inter-Operation? • The Grid Inter-Operation Research Question • Alternatives to/for Grid Inter-Operation • Inter-Operating Grids Through Delegated MatchMaking • Experimental Results • Conclusion and Future Work
Current e-Science Computational DemandFor Every Grid (Cluster), Over 500k Jobs/Year The Grid Workloads Archive http://gwa.ewi.tudelft.nl >500 kjobs/year/trace 1.5 yrs >525K A. Iosup, H. Li, M. Jan, S. Anoep, C. Dumitrescu, L. Wolters, D.H.J. Epema, The Grid Workloads Archive, 2007 (submitted to FGCS).
Current e-Science DemandBursty Demand Leads to High Wait Time A. Iosup, C. Dumitrescu, D.H.J. Epema, H. Li, L. Wolters, How are Real Grids Used? The Analysis of Four Grid Traces and Its Implications, Grid 2006.
The 1M-CPU Machine with Shared Resource Ownership • The 1M-CPU machine • E-Science (high-energy physics, earth sciences, financial services, bioinformatics, etc.) • Over-provisioning for any individual e-Science field • Provisioning for all e-Science fields at the same time • Shared resource ownership • Shared resource acquisition • Shared maintenance and operation • Summed capacity higher (more efficiently used) than sum of individual capacities
How to Build the 1M-CPU Machine with Shared Resource Ownership? • The number of clusters increases at high pace • Top500 SuperComputers: cluster systems from 0% to 75% share in 10 years (also from 0% to 50% performance) • CERN WLCG: from 100 to 300 clusters in 2½ years clusters MPPs Source: http://goc.grid.sinica.edu.tw/gstat/table.html
Last 4 years How to Build the 1M-CPU Machine with Shared Resource Ownership? Now:<1.2x/yr Max:100x To build the 1M-CPU cluster: - At last 10 years rate, another 10 years - At current rate, another 40 years Average: 20x Median: 10x Last 10 years Data source: http://www.top500.org
How to Build the 1M-CPU Machine with Shared Resource Ownership? • CERN’s WLCG cluster size over time Shared clusters grow on average slower than Top500 cluster systems! Max: 2x/yr Avg: +15 procs/yr Median: +5 procs/yr Year 1 Year 2 Data source: http://goc.grid.sinica.edu.tw/gstat/
How to Inter-Operate 10,000s of Clusters? How to Build the 1M-CPU Machine with Shared Resource Ownership? How to Build the 1M-CPU Machine with Shared Resource Ownership? • Number of clusters is growing, cluster size is not • Many small clusters in one large distributed computing system • 6,000 clusters = 1M CPUs / 150 CPUs/cluster [CERN] • 30,000 clusters = 1M CPUs / 32 CPUs/cluster [Kee et al.,SC04] • Inter-operate 10,000s of clusters with grids • But the largest grid has 300 clusters, most grids have 2-3… Research Question: How to inter-operate cluster-based gridsin a scalable and efficient way?
Outline • Grid Inter-Operation: Introduction, Motivation, and Goals • Alternatives to/for Grid Inter-Operation • Inter-Operating Grids Through Delegated MatchMaking • Experimental Results • Conclusion and Future Work
OAR Condor Koala Globus GRAM Alien Independent Centralized Condor Flocking OAR2 OurGrid Moab/Torque NWIRE CCS Decentralized Hierarchical Alternatives to/for Grid Inter-Operation Load imbalance? Resource selection? Scale? Root ownership? Node failures? Accounting? Trust? Scale?
Outline • Grid Inter-Operation: Introduction, Motivation, and Goals • Alternatives to/for Grid Inter-Operation • Inter-Operating Grids Through Delegated MatchMaking • Architecture • Mechanism • Experimental Results • Conclusion and Future Work
2 3 3 3 3 3 3 3. Inter-Operating Grids Through Delegated MatchMakingThe Delegated MatchMaking Architecture • Start from a hierarchical architecture • Let roots exchange load • Let siblings exchange load Hybrid hierarchical/decentralized architecture for grid inter-operation
Resource request Local load low Resource usage rights 3. Inter-Operating Grids Through Delegated MatchMaking The Delegated MatchMaking Mechanism • Deal with local load locally (if possible) Cluster
Resource request Local load too high Bind remote resource Delegate Resource usage rights 3. Inter-Operating Grids Through Delegated MatchMaking The Delegated MatchMaking Mechanism • Deal with local load locally (if possible) • When local load is too high, temporarily bind resources from remote sites to the local environment. • May build delegation chains. • Delegate resource usage rights, do not migrate jobs. • Deal with delegations each delegation cycle (delegated matchmaking) The Delegated MatchMaking Mechanism=Delegate Resource Usage Rights, Do Not Migrate Jobs
Outline • Grid Inter-Operation: Introduction, Motivation, and Goals • Alternatives to/for Grid Inter-Operation • Inter-Operating Grids Through Delegated MatchMaking • Experimental Results • Experimental Setup • Performance Evaluation • Overhead Evaluation • Conclusion and Future Work
4. Experimental ResultsExperimental Setup • Inter-operating DAS and Grid’5000: 20 clusters, >3000 processors DAS+Grid’5000 with DMM • Discrete event simulation • Independent (separated clusters+FCFS, Condor+MM) • Centralized (CERN+poll, centralized grid scheduler+WF+FCFS) • Decentralized (Condor with flocking+MM+FS) • Workloads • Real traces • Realistic • Metrics • WT, RT, SD, Goodput • FinishedJobs[%], O’head
DMM Decentralized Centralized Independent 4. Experimental ResultsPerformance Evaluation • DMM • High goodput • Low wait time • Finishes all jobs • Even better for load imbalance between grids • [see paper] The DMM delivers good performance
4. Experimental ResultsOverhead Evaluation • DMM • Overhead ~16% • 93% more control messages • Constant number of delegations per job until 80% load • DMM Threshold to control o’head. • [see paper] The DMM incurs reasonable overhead
Outline • Grid Inter-Operation: Introduction, Motivation, and Goals • Alternatives to/for Grid Inter-Operation • Inter-Operating Grids Through Delegated MatchMaking • Experimental Results • Conclusion and Future Work
Conclusion and Future Work How to inter-operate cluster-based gridsin a scalable and efficient way? • The Delegated MatchMaking architecture, mechanism, and policies Contributions Evaluation of DMM • Hybrid architecture • Delegate resource usage rights • Framework for policy investigation • High goodput • Low wait time • Reasonable overhead Future Work • Fault-tolerant policies (built resource availability model: Grid’2007) • Larger systems (we promised the 1M-CPU machine) • Malicious participants, trust • Real environment evaluation (built testing tool: GrenchMark, CCGrid’06)
Thank you! Questions? Remarks? Observations? Contact • A.Iosup@tudelft.nl • http://www.pds.ewi.tudelft.nl/~iosup/(or Google “iosup”) The Grid Workloads Archive http://gwa.ewi.tudelft.nl/ (or Google “The Grid Workloads Archive”) Share your Job and Resource Availability Traces!