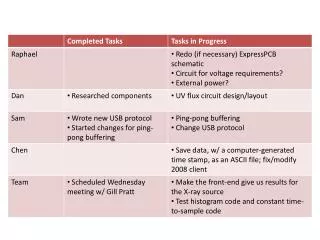
Stream Data
Stream Data. Operator Ordering Query Optimization Query Index. Query Optimization. Operator Ordering Problem Assumption A query consists of a set of commutative filters Filter Drop or Select Overall processing costs can vary widely across different filter order Ex


Stream Data
E N D
Presentation Transcript
Stream Data • Operator Ordering Query Optimization • Query Index
Query Optimization • Operator Ordering Problem • Assumption • A query consists of a set of commutative filters • Filter • Drop or Select • Overall processing costs can vary widely across different filter order • Ex • Filter O1 drops 1, 3, 5 • Filter O2 drops 2, 4, 6 • Let an input stream be 2, 4, 6. • The cost of Operator Order O2,O1is cheaper than that of O1, O2
Operator ordering • Operator Ordering • Choose efficient order • The optimal order is changed over time. • Eddy[4] • Tuple routing Technique • An operator dropping many tupleshas high priority
Operator ordering • A-Greedy[9] • Query Cost C • d(i|j) denotes the conditional probability that ith operator Of(i) will drop a tuple e, given that e was not dropped by any of operators Of(1), Of(2),..., Of(j). • ti represents the expect time for Of(i) to process one tuple • Goal Minimized C • Greedy heuristic rule which rearrange the operator order satisfying the following formula
Profile matrix view Operator ordering • A-Greedy • Profiler • To obtain conditional selectivity d(i|j), profiling is used. • In profiling, a tuple e which is dropped during processing is selected with probability p • Then, profiler artificially applies e to all operators and generate a profile tuple whose attribute bi is 1 if Oi drops e • Reoptimizer • Keeps the operator order • Maintains a matrix view • Ex) first row: O4 drops most tuples, second row : reports the numbers of tuples which are not dropped by O4 droped by O1,O3, and O2.
Operator ordering • Problem of A-Greedy • Profiling overhead • A normal tuple may be dropped by an operator, but a tuple for profiling is applied to all operators. • In other words, when 10% data of input are profiled, the increment of system overheads is greater than 10%.
Load Shedding[8] • Push-based data source • High and unpredictable data rates • Problem • Load > Capacity • Load Shedding: eliminate excess load by dropping data
App App App QoS QoS QoS Aurora Slide s s s s s s . . . . . . s s s s s s s App m s s s s m m s . . . . . . È È È . . . È È È È m m m App Tumble Tumble Tumble s s s s m m s m
QoS: Aurora B C A • QoS • Specifies “Utility” Of Imperfect Query Results Delay-Based (specify utility of late results) Delivery-Based, Value-Based (specify utility of partial results) • QoS Influences… Scheduling, Storage Management, Load Shedding
Load Shedding: Aurora • Two Load Shedding Techniques: • Random Tuple Drops Add DROP box to network(DROP a special case of FILTER) Position to affect queries w/ tolerant delivery-based QoSreqts • Semantic Load Shedding FILTER values with low utility (acc to value-based QoS)
Load Shedding: Aurora • Load Coefficient
Load Shedding: Aurora • Best location of Drop operator • Maximize cycle gain, minimize utility loss • Cycle gain: processor cycles gained fro each percentage of tuples dropped • G(x) = R*(x*L-D) R: input rate, L is load coefficient • Loss/Gain ratio the smaller, the better R Drop x% L D cycles/tuple • Loss-tolerant graph
Load Shedding[26] • Load Sheddingwhere, when, how much. • Where ->[8], How much [26[ • Particularly, in multi-Query Environments • Ex) Two Query, Q1 and Q2 Data size = 24, Processing cost per tuple = c Overall cost = 24*2*c = 48c System capability = 30c Goal : Min G = ((1-rp)/rp)*fp where rpis the fraction to be considered for a query Qp fpis actual frequency of tuples to be result. Assume fa =1, fb =4 Plan 1) Uniform ra= rb=15 G = 3 Plan 2) Proportional fb/fa = 4 6:24 ra= 6/24, rb = 24/24 G=3 Plan 3) Optimal ra= 10/24, rb 20/24 G = 2.2
Load Shedding[26] • Estimate fp • Let bi = 1 if a tupleti is a query result. Otherwise bi =0 • fp = bi • Each tupleti is processed with a probability rq and discard with a probability 1-rq • Let Xi = bi/rq with a probability rq and Xi = 0 with a probability 1-rq • Estimatefp = Xi • E(fp) = E(Xi) = bi = fp • Var(fp) =((1-rq)/rq) *fp • Variance means average error ep
Load Shedding[26] • Let S is a set of query, |S|= N • Error vector E = [e1,…, eN] • Importance of queries V = [v1,…,vN] • Resource Cost C = [c1,…cN] • Processing ratio r = [r1,…, rN] • Total resource limitation = L • Data Size = W • Goal : • Constraint rC = ri*ci <= L/W • Minimize G = EV= ei*vi • Apply eq=((1-rq)/rq) *fp • G= - fi*vi + G1 where G1 = (fj*vj)/rj • To minimize G, it suffices to minimize G1 • non-linear programming(separable and convex resource allocation) • Sorting O(NlogN) • In the paper, suggest O(N) algorithm
Query Index • Invoke all query whenever data arrives • Query Index • Property of Stream Data • Locality • ex. the temperature in near future will be similar to the current temperature • Some or all queries will be reused in near future
Query Index • The number of registered queries is huge • Overhead to find out the proper queries which can evaluate the input stream item. • IBS(Interval Binary Search Tree) • R-Tree • Multi-Dimensional data access method • Range conditions of Queries are overlaped. • Many nodes should be traversed due to a large amount of overlap of query conditions
Group Filter for R.a Query Conditions q1: R.a 1 and R.a < 10 q2: R.a > 5 q3: R.a > 7 q4: R.a = 4 q5: R.a = 6 5 = > 1=q1 4=q4 6=q5 1 7 q1 q2 q3 < != 10 q1 Query Index • IBS[10] • Use balanced binary search tree for query indexes • When a data item arrives, balanced binary search trees and hash table are probed with the value of tuples • Not appropriate to general range queries which have two bounded conditions • Each condition is indexed in individual binary tree. unnecessary partial result
Query Index • Query Processing Based on Spatial Join[26] • Query- represented as a region • Data – represented as a point • Batch mode • Accumulate arriving data elements and process continuous queries Set of data represented as a region • Uses Spatial Indexes for data set and queries
Query Index • A set of data region • Query region • compute overlap relationships • In [26], Use Corner Transformation • n-dim object 2n-dim point
stream table 1 4 5 6 7 10 inf DN1DN2DN3DN4DN5DN6DN6 {+q1} {+q2} {+q3} {-q1} {-q2,-q3} q1 q2 q3 Query Index • BMQ-Index [11] • DMR List is a list of DNi • DNi = <DRi,+DQSet, -DQSet> • DRi is a matching Region (bi-1, bi) • +DQSet is a set of queries whose lower bound lk = bi-1 • -DQSet is a set of queries whose upper bound uk = bi-1 • A stream table keeps the recently accessed DNi Query Conditions q1: R.a 1 and R.a < 10 q2: R.a > 5 q3: R.a > 7 q4: R.a = 4 q5: R.a = 6
stream table 1 4 5 6 7 10 inf DN1DN2DN3DN4DN5DN6DN6 {+q1} {+q2} {+q3} {-q1} {-q2,-q3} q1 q2 q3 Query Index • QSet(t) is a set of queries for data vt • Let vt be in DNj and vt+1 be in DNh, • e.g., bj-1 <= vt < bj and bh-1<= vt+1 < bh • Then QSet(t+1) is obtained as follows • For example • vt = 4.5, QSet(t) = {q1} • if vt+1 = 12, • U+DQSet = {q2,q3} • U-DQSet = {q1} • Thus QSet(t+1) = {q2,q3}
Query Index • Problem of BMQ-Index • If the forthcoming data is quite different from the current data, many DRM nodes should be retrieved like a linear search • Support only (l, u) style condition. • q4 and q5 is not registered • does not work correctly on the boundary condition. Let vt= 5.5 and QSet(t) = {q1,q2} If vt+1 = 5, Then QSet(t+1) is also {q1,q2} But, actual query set of vt+1 is {q1}. stream table 1 4 5 6 7 10 inf DN1 DN2 DN3 DN4 DN5 DN6DN6 {+q1} {+q2} {+q3} {-q1} {-q2,-q3} q1 q2 q3
Reference • [1] D. Carney, U. Cetintemel, M. Cherniack, C. Convey, S. Lee,G. Seidman, M. Stonebraker, N. Tatbul, and S. Zdonik. Monitoring streams–a new class of data management applications. In Proc. 28th Intl. Conf. on Very Large Data Bases, Aug. 2002. • [2] A. Arasu, B. Babcock, S. Babu, M. Datar, K. Ito, R. Motwani, I. Nishizawa, U. Srivastava, D. Thomas, R. Varma, J. Widom, J., “Stream: The stanford stream data manager”, IEEE Data Engineering Bulletin, Vol 26, No 1, pp. 19-26, 2003. • [3]J. M. Hellerstein, M. J. Franklin, S. Chandrasekaran, A. Deshpande, K. Hildrum, S. Madden, V. Raman, V., M. A. Shah, “Adaptive query processing: Technology in evolution”, IEEE Data Engineering Bulletin, Vol 23, No 2, pp. 7-18, 2000. • [4] R. Avnur, J. M. Hellerstein, “Eddies: Continuously adaptive query processing”, In Proceedings of ACM SIGMOD Conference, pp. 261-272, 2000. • [5] Brain Babcock et.al, “Chain: Operator scheduling for Memory minimization in Data Stream Systems,” ACM SIGMOD 2003. • [6] Don Carney et.al, “Operator Scheduling in a Data Stream Manager”, VLDB 2003 • [7] B. Pielech, “Adaptive scheduling algorithm selection in a streaming query system,” Master thesis , Worcester polytechnic institute, 2004. • [8] N Tatbul, U Çetintemel, S Zdonik, M Cherniack, M Stonebraker, “Load shedding in a data stream manager”, VLDB 2003. • [9]. Babu, S., Motwani, R., Munagala, K., Nishizawa, I., Widom, J.: Adaptive ordering of pipelined stream filters. In: Proceedings of ACM SIGMOD Conference. (2004) 407–418 • [10] S. Madden, M.A. Shah, J.M. Hellerstein, V. Raman, “Continuously adaptive continuous queries over streams”, In Proceedings of ACM SIGMOD Conference, 2002. • [11] Jinwon Lee, Seungwoo Kang, Youngki Lee, SangJeong Lee, and Junehwa Song, "BMQ-Processor: A High-Performance Border Crossing Event Detection Framework for Large-scale Monitoring Applications", IEEE Transactions on Knowledge and Data Engineering (TKDE), Vol. 21, No. 2, pp 234-252, February 2009
Reference • [12] S. Madden et.al., “TAG: Aggregation Service for Ad-Hoc Sensor Networks”, OSDI, 2002 • [13] N. Shrivastava et.al., “Medians and Beyond: New Aggregation Techniques for Sensor Networks,” ACM Sensys 2004 • [14] N. Trigoni et.al., “Multi-Query Optimization for Sensor Networks” DCOSS 2005 • [15]N. Trigoni, et.al., "Routing and Processing Multiple Aggregate Queries in Sensor Networks,“ ACM SenSys, 2006. • [16] A. Deshpande et.al., "Model-Driven Data Acquisition in Sensor Networks,“ VLDB, 2004. • [17] D. Chu et.al., "Approximate Data Collection in Sensor Networks using Probabilistic Models,“ ICDE, 2006 • [18] D. Tulone et. al., “PAQ: Time Series Forecasting For Approximate Query Answering In Sensor Networks,” European Conf. Wireless Sensor Networks, 2006 • [19] A. Deligiannakis et.al., “Compressing Historical Information in Sensor Networks,” ACM SIGMOD 2004 • [20] A. Jain et.al., “Adaptive Stream Resource Management Using Kalman Filters,” ACM SIGMOD 2004 • [21] X. Yang et.al., “In-Network Execution of Monitoring Queries in Sensor Networks,” ACM SIGMOD 2007. • [22]M. Stern et.al., “Towards Efficient Processing of General-Purpose Joins in Sensor Networks,” ICDE 2009. • [23]A. Pandit et.al, “ Communication-Efficient Implementation of Range-Joins in Sensor Networks,” International Conference on Database Systems for Advanced Applications (DASFAA), 2006 • [24] H. Yu et.al, “In-Network Join Processing for Sensor Networks,” APWeb 2006. • [25] A. Coman et.al, “On Join Location in Sensor Networks,” MDM 2007. • [26] H.S. Lin, J.G. Lee, M.J. Lee, K.Y. Whang, I.Y. Song ,” Continuous Query Processing in Data Streams Using Duality of Data and Queries,” ACM SIGMOD 2006. • [27] B. Mozafari, C. Zaniolo, “Optimal Load Shedding with Aggregates and Mining Queries,” ICDE 2010.