Motivation
E N D
Presentation Transcript
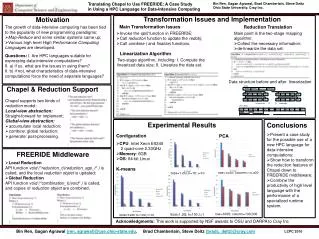
Effective Access Over Public Email Conversations William Lee, Hui Fang and Yifan Li University of Illinois at Urbana-Champaign Motivation Clustering • Goal: • Find commonly-discussed topics from a set of conversations (threads) • Method: • Use agglomerative clustering with complete link • Learn similarity functions from different “perspectives” of threads: • authors, date, subject, contents, contents without quote, first message, reply, reply without quote. • Use Linear and Logistic Regression to learn the combined similarity function • Information within newsgroups or mailing lists has largely been underutilized. • For now, access to those data is restricted to traditional searching and browsing. • Visualization---Conversation Map • Derived from Treemap • Clusters sorted by two time dimensions • Allows user to adjust the similarity threshold -- “zoom” to the more similar threads • Experiment Design • Data: 3 CS class newsgroups from UIUC • Judgement file: manually created by three different human taggers • Methodology: 3-way cross validation, using one group’s judgment file as training set and test on the other two. • Evaluation: Use overall entropy as comparison metric • Experiment Result Existing technologies Search Browse Thread 1: Subject, Authors, Date Thread 2: Subject, Authors, Date First Message First Message First Reply First Reply Second Reply Second Reply • How to access those information more effectively? • Clustering • Summarization Third Reply Third Reply Summarization Conclusion • Propose two ways to access to the public email archive • Clustering • Summarization • Use conversation map to visualize the clustering result • Future Work • Derive better algorithms to learn the similarity function • Faster clustering algorithms that work on mining patterns in conversations • LM approach to email summarization • Goal: • Find the gist from a conversation (i.e. a thread) • Observation: Different types of conversation need different types of summarization method • Question-driven conversation • Announcement –driven conversation • Solution to Question-Driven summarization • Key observation • Question plays an important role • Method • Identify the question • Detect the topic shifting during the conversation • Divide the conversation into segments based on topic shifting • Store all the segments containing the question • Remove segments with the redundant question • Return the remaining segments • Solution to Announcement-Driven summarization • Key observation • Subject plays an important role • Threads with similar subjects may have commonpivot words in their summaries • Method • Training stage • Clustering the threads by similarities of the subjects • Find frequent words (pivot words) in the summaries • Extend the subjects by combining the corresponding pivot words • Testing stage • Given a thread, find the similar subject w.r.t. the current one • Find the pivot words associated with the subject to extend the current one • Select similar sentences w.r.t. the extended subject as the summary • Experiment Design • Data: 3 CS class newsgroups from UIUC • Judgement file: manually created by two different human taggers • Evaluation: Precision and Recall or user study • Examples of Experiment Results Question-Driven Announcement-Driven Subject:MP7: Viewing Array in debugger From:Scott Stephens <jstephen@uiuc.edu> on Sat, 04 Dec 2004 22:49:06 -0600 I've been debugging things using DDD with dbx, but I'm running into a weird problem. My PatriciaTree class is basically a wrapper around a root pointer, so I observe that pointer, and dereference it to give me my first PatriciaNode, and then look at all that's inside that, and one of those things is a pointer to "data" within the Array object that's embedded in my PatriciaNode. An address shows up fine, but I'd like to dereference it to take a look at the actual array, so I can continue to examine the structure of my tree. But when I dereference it in DDD, i just shows up as "(nil)". I know for a fact that there's valid data in that array somewhere, because I can access it in my program, I just can't look at it in the debugger. Anybody have any ideas? It'd be really nice to look at that info for debugging purposes. -Scott SUBJECT: Final Exam - PLEASE READ TIME: 1:30-4:30pm PLACE: Regular classroom (SC 1404) TOPICS: The exam is cummulative but with emphasis on the material after the midterm. Most important from earlier material are general techniques: divide-and-conquer, greedy, dynamic programming, randomization. Also topics like MST and shortest paths that have reappeared after the midterm. Student having more than two consecutive examinations: No student should be required to take more than two consecutive final examinations. N In a semester, this means that a student taking a final examination at 8:00 a.m. and another at 1:30 p.m. on the same day cannot be required to take an examination that same evening. N However, the student could be required to take an examination beginning at 8:00 a.m. the next day ...