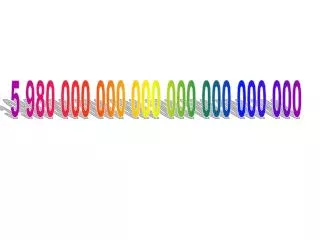Download

1 / 46
460 likes | 477 Vues
Learn how to handle a high volume of events in Google Cloud using DataFlow, with insights on architecture, challenges, and best practices.

E N D
About me Oleksandr Fedirko BigData Architect at GlobalLogic I do BigData enabling on a projects Training and mentoring on BigData skills alexander.fedirko@gmail.com https://www.linkedin.com/in/fedirko/
Developer vs Data engineer OOP SOLID GoF Java C++ C# JavaScript Unit tests TDD DWH Business Intelligence Data Science DBA ETL Pipeline Reports R Data analysis
Agenda • Starting point and basic assumptions at the project • Evolution of the Cloud solution • Challenges that push decisions • Research on a BigData project, value of micro PoCs • NFRs on a BigData project • Good things that helped a lot on a project • A place of ML\AI in the system • Conclusions
Starting point and basic assumptions at the project • Cloud agnostic • User’s defined CEP Rules (complex event processing) • 100 Data Source Types (Cisco ASA, Gigamon Netflow, Windows, Unix etc) • 10 000 Data Sources (Routers, PCs, Servers etc) • Need of ML\AI • Analytics • Quick search • SSO integration
Starting point and basic assumptions at the project Example of the Rules (High Traffic) When The event(s) were detected by one or more of these data source types "NetFlow" And Bytes is greater than 1048576 bytes (1Mb) Then Create Indicator “High Traffic” End
Starting point and basic assumptions at the project Example of the Rules (Port Scanning) When The event(s) were detected by one or more of these data source types "Cisco ASA" With the same source IP and destination IP more than 5 times, across more than 5 destination ports within 4 min Then Create Incident “Port Scanning” of threat type "External Hacking" End
Starting point and basic assumptions at the project Requirement example: Data Sources would be part of the Identity Database Product must integrate with the CMDB for the list of devices to be monitored. Product must be capable of indexing terabytes of normalized log data and provide performance in both indexed and table scans the exceeds search results of 1 million records a second.
Starting point and basic assumptions at the project Problems? • 1000 eps through Drools • No Autoscale on DataProc • Manage custom adapters via OpenShift cluster • Stateful backend
Evolution of the Cloud solution Limitation via SoW (Statement of Work) • GCP bounded • Exclude real time event view • Exclude metrics UI • Postpone AI\ML implementation • Postpone Analytical storage implementation • No sensitive data in the system • Exclude audit logging
Evolution of the Cloud solution Technology transform • From Azkaban to AirFlow • Requirements to SRS (Software requirements specification) • From mutable rows to immutable • From Spark to Beam+DataFlow • Agree on NiFi as primary Ingest tech, get rid of custom Java adapters
13 17 10 06 15 11 01 02 04 05 08 16 07 03 09 14 12 Google Cloud On-prem & Distributed Locations Archive Data Storage (Google Cloud Storage Bucket) Google Compute Engine Google Compute Engine Realtime Stream Compute Realtime Stream Compute Google Dataflow (Apache Beam) IaaS NiFi Compute IaaS Kafka Compute Primary Data Storage (Google BigTable) IaaS NiFi Compute Kafka Compute Push Data Source* Push Data Source Secondary Data Storage Filesystem (Google Cloud Engine Local File System) Filesystem (Google Cloud Engine Local File System) IaaS Elastic Compute Pull Data Source* IaaS Elastic Compute Google Compute Engine Pull Data Source Filesystem (Google Cloud Engine Local File System) IaaS SecA Application IaaS SecA Web Application OpenShift *Data Source Inventory Phase 2 Data Source Types: • Cisco ASA • F5 DNS • Cisco Ironport • Windows Data Source • NetFlow • Bit9 • Unix • Protegrity • BlueCat • Cisco FireSight IaaS Airflow Compute Google Compute Engine Metrics Datastore Airflow Compute IaaS MySQL (Primary) IaaS OpenTSDB IaaS MySQL (Slave) Google Compute Engine Scheduler / Workflow Orchestration (IaaS Airflow) IaaS OpenTSDB Google Compute Engine Filesystem (Google Cloud Engine Local File System) Google BigTable
Challenges that push decisions How to solve stateful processing problem? • Share state on database? • What kind? Key-value? • If not then share states on stream processing workers • Can they store 250k eps for 5 minutes? 1 hour? 1 day? • What to do with late arrivals?
Challenges that push decisions How to collect metrics (infra\middleware\application)? • Customer care less of infra level metrics • Most of the metrics are throughput of the middleware (NiFi\Kafka\DataFlow) • How to measure DataFlow performance? There is nothing on Google StackDriver Tip: use out-of-the-box APIs as much as possible
Challenges that push decisions How to measure delay on component? • Call Kafka API for offsets? • What to do with NiFi? • How to measure delay on DataFlow?
Research on a BigData project, value of micro PoCs More than 20 PoCs (Research Spikes) within 1 year
Research on a BigData project, value of micro PoCs For DataFlow • Can it make 250k eps ? • Does Beam fit well? • Would DataFlow autoscaling work fine?
Research on a BigData project, value of micro PoCs For GCP Datastore • Would it make 250k eps? • Can it be easily accessible? • Could it be integrated with DataFlow?
Research on a BigData project, value of micro PoCs For GCP PubSub • Would it make 250k eps? • Can it deliver every message? • Can it scale up and down?
Research on a BigData project, value of micro PoCs For AirFlow • Can we start static stream jobs from AirFlow? • Can we manage batch jobs via AirFlow by schedule? • Can we replace Azkaban with AirFlow? • What kind of resources do we need for AirFlow?
Research on a BigData project, value of micro PoCs For NiFi overflow (to comply with zero messages loss) • What should NiFi do when the downstream (Kafka) is down? • What should NiFi do when the downstream (Kafka) just start throttling? • Store files to infinite storage • Process them later • Do not create extra pressure on Kafka
Research on a BigData project, value of micro PoCs For Replay service • How to recreate throughput on another environment? • Execute in parallel or sequentially? • What kind of UI to provide for user?
Research on a BigData project, value of micro PoCs For Kafka Manual Commit, to cover 0 message loss we have to switch to alternatives of Auto Commit (by default) • Can we switch to non-autocommit on DataFlow? • Can we switch to non-autocommit on custom Kafka consuming jobs written in Java (Spring Cloud)? commitOffsetsInFinalize found. The problem is in its definition: “It helps with minimizing gaps or duplicate processing of records while restarting a pipeline from scratch. But it does not provide hard processing guarantees.”
NFRs on a BigData project • No message loss • 250k eps, with 1kk eps spikes • All secrets in Hashicorp • Appliance with OWASP best practices • Static Code Analysis • End-to-End TLS for all connectivity • No-downtime application update
NFRs on a BigData project DevOps NFRs • Service Discovery (via Consul) • Circuit Breaker (via Hystrix\Resilience4j) • Health Check (Spring Cloud) • Start pod on OpenShift without any dependency (lazy start), give 200 response and fail later
Good things that helped a lot on a project Extra team for CEP • 3-5 people • Isolate from other members • Core functionality first, integration later
Good things that helped a lot on a project • Custom data generator • Custom scenarios • Throughput generation • Custom stream manager • Start\stop\restart
Good things that helped a lot on a project • Keep your software design and architecture up-to-date • Only live schemas in your Wiki, no static images • Make code review for everything
13 17 10 06 15 11 01 02 04 05 08 16 07 03 09 14 12 Google Cloud On-prem & Distributed Locations Archive Data Storage (Google Cloud Storage Bucket) Google Compute Engine Google Compute Engine Realtime Stream Compute Realtime Stream Compute Google Dataflow (Apache Beam) IaaS NiFi Compute IaaS Kafka Compute Primary Data Storage (Google BigTable) IaaS NiFi Compute Kafka Compute Push Data Source* Push Data Source Secondary Data Storage Filesystem (Google Cloud Engine Local File System) Filesystem (Google Cloud Engine Local File System) IaaS Elastic Compute Pull Data Source* IaaS Elastic Compute Google Compute Engine Pull Data Source Filesystem (Google Cloud Engine Local File System) IaaS SecA Application IaaS SecA Web Application OpenShift *Data Source Inventory Phase 2 Data Source Types: • Cisco ASA • F5 DNS • Cisco Ironport • Windows Data Source • NetFlow • Bit9 • Unix • Protegrity • BlueCat • Cisco FireSight IaaS Airflow Compute Google Compute Engine Metrics Datastore Airflow Compute IaaS MySQL (Primary) IaaS OpenTSDB IaaS MySQL (Slave) Google Compute Engine Scheduler / Workflow Orchestration (IaaS Airflow) IaaS OpenTSDB Google Compute Engine Filesystem (Google Cloud Engine Local File System) Google BigTable
ML\AI use cases • Train on a dataset from BigTable • Apply model in real time within the Rules Engine • Apply model on a batch data from BigTable Typical AI\ML tasks for security analytics: • Anomaly detection • Fuzzy logic to identify host in Identity Database • Malicious use of Rules Engine • Statistical methods to auto adjust Rules
Conclusions • See something unknown - do micro PoC • Avoid mutable objects in Big Data • Limit the scope to the real deliverable product • Requirements too fuzzy? Make your own! • DevOps are your best friends (QA to) • Do not use Gerrit • Sketch everything before you start develop