Download
1 / 8
80 likes | 188 Vues
Join Dr. Chakra Chennubhotla's research group to explore high-throughput biomedical data analysis using MapReduce, clustering, and distributed computing. Learn about Java, Apache Hadoop, Mahout, linear algebra, and more. Dive into the world of big biological data and diagnostics. Get involved in open-source development and programming at scale.

E N D
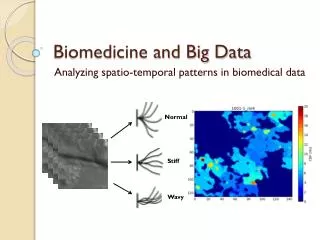
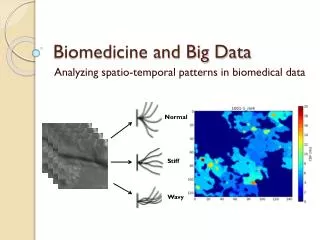
Biomedicine and Big Data Normal Analyzing spatio-temporal patterns in biomedical data Stiff Wavy
My Research Group Dr. Chakra Chennubhotla Ph.D. Computer Science University of Toronto Shannon Quinn B.S. Computer Science Georgia Tech Andrej Savol B.S. Applied Mathematics University of Pittsburgh Virginia Burger M.S. Mathematics University of Vienna
Our Mission • High-throughput biomedical data analysis
Problem and Solution • Biomedical and biological data are BIG • MapReduce! chunks C0 C1 C2 C3 Map Phase M0 M1 M2 M3 mappers IO0 IO1 IO2 IO3 Shuffling Data R0 R1 Reduce Phase Reducers FO0 FO1
Specifically… Clustering!
Requirements • Java • Apache Hadoop or Amazon EC2 • Apache Mahout • Comfortable with linear algebra • Ax = b • X = UΣUT • Hive, HBase, Giraph, GraphLab, etc optional but awesome
Final Thoughts • Distributed computing • Open source development • Programming at scale • Large project management • Software engineering principles, tools • Biomedical context • Biological data is huge • Diagnostics: helping people
Questions? Comments? Interested? • squinn@cmu.edu || spq1@pitt.edu