SISTEME SIMD
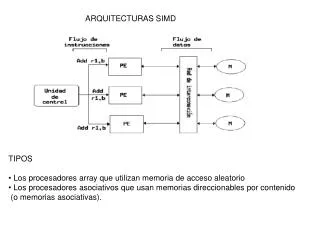
SISTEME SIMD. PROCESOARE MATICIALE PROCESOARE VECTORIALE SISTEME SISTOLICE VLSI. PROCESOARE MATICIALE. Prima idee: Unger ( 1958 ) articol “A Computer Oriented Toward Spatial Problems”.


SISTEME SIMD
E N D
Presentation Transcript
SISTEME SIMD • PROCESOARE MATICIALE • PROCESOARE VECTORIALE • SISTEME SISTOLICE VLSI
PROCESOARE MATICIALE Prima idee: Unger (1958) articol “A Computer Oriented Toward Spatial Problems”. Primul calculator matricial: ILLIAC IV NASA ~1970. Alte sisteme: Thinking Machine CM-2, Maspar MP-2 etc. Ideea de bază: o unitate de control furnizează semnalele care controlează elementele de prelucrare, formate din UCP-uri sau UAL-uri şi memorie locală, toate aceste elemente de prelucrare operând în acelaşi ritm. Criteriile de bază la proiectarea unui calculator matricial : 1) structura unităţilor de prelucrare, în funcţie de aplicaţie: astfel, se pot utiliza unităţi aritmetice-logice foarte simple sau UAL-uri de complexitate medie pe 8-32 de biţi sau chiar UAL-uri foarte complexe cu posibilităţi de prelucrare în virgulă mobilă.
2) interconectarea elementelor de prelucrare: orice topologie, cea mai utilizată alegere fiind grila rectangulară, datorită implementării naturale a problemelor bidimensionale cu matrici şi imagini;
3) autonomia locală a elementelor de prelucrare: unitatea de control specifică elementelor de prelucrare instrucţiunea care se execută, dar fiecare element de prelucrare poate să execute sau nu, instrucţiunea, pe baza unor informaţii locale (coduri de condiţie).
PROCESOARE VECTORIALE Procesoarele vectoriale -> succes comercial mare! Cele mai cunoscute calculatoare: sistemele realizate la Cray Research, începând cu Cray-1 (1976) şi continuând cu celelalte calculatoare din seria Cray, inclusiv C90 şi T90. Într-o aplicaţie tipică de prelucrare a vectorilor există multe instrucţiuni de forma: for (i=0; i<n; i++) a[i]=b[i]+c[i]; unde a,b,c sunt vectori de numere reprezentate în virgulă mobilă.
De obicei, prelucrarea vectorială este combinată cu prelucrarea în bandă de asamblare. Pentru instrucţiunea de mai sus se consideră un sumator pentru numere reprezentate în virgulă mobilă, realizat în bandă de asamblare, având patru segmente. La fiecare ciclu, fiecare segment al benzii de asamblare execută o operaţie elementară.
Exemplu: se consideră operaţia vectorială: R1 = R1 * R2 + R3 unde R1, R2 şi R3 sunt vectori. Această operaţie se realizează aşa cum se prezintă în tabela:
SISTEME SISTOLICE VLSI Atributele de bază ale structurilor de calcul VLSI sunt: 1) simplitate şi regularitate: se obţine un cost suficient de mic faţă de aplicabilitatea limitată; 2) concurenţă si comunicaţie: se obţine o utilizare concurentă a elementelor de prelucrare, iar în cazul unui număr mare de elemente de prelucrare care lucrează simultan, coordonarea şi comunicaţia devin semnificative; 3) intensitate a calculului: structurile VLSI fiind caracterizate de o mare intensitate a calculului sunt orientate spre implementarea algoritmilor limitaţi de calcule şi mai puţin spre implementarea algoritmilor limitaţi de I/E (numărul de calcule este mult mai mare decât numărul de operaţii de I/E). Exemplu: produsul de matrici are O(n3) paşi de înmulţire-adunare, dar numai O(n2) operaţii de I/E, în timp ce adunarea a două matrici necesită n2 operaţii de adunare şi 3n2 operaţii de I/E.
Conceptul de arhitectură sistolică a fost dezvoltat de Kung şi un colectiv de la Carnegie Mellon University. Un sistem sistolic : set de celule interconectate, fiecare capabilă să realizeze o anumită operaţie simplă => structuri simple pentru comunicaţie şi control. Într-un sistem sistolic informaţia se transferă în flux între celule într-un mod bandă de asamblare, iar comunicaţia cu mediul extern este realizată numai de celule de graniţă. Principiul de bază al structurilor sistolice: înlocuirea unui element de prelucrare (PE – Processing Element) printr-un masiv de elemente de prelucrare => productivitate de calcul mai mare fără a creşte concurenţa la memorie. Avantaje: -PE capabil să utilizeze fiecare dată de intrare; -expandabilitate modulară; -fluxurile de date şi control sunt simple şi regulate; -utilizarea de celule simple şi uniforme; -eliminarea comunicaţiilor globale; -timp de răspuns scurt.
Un model global pentru un masiv de procesoare VLSI : (G, F, T) unde: G este geometria reţelei şi se referă la topologia de interconectare a componentelor. Poziţia fiecărei celule este determinată de coordonatele carteziene în plan. Interconectarea între celule suportă fluxul de date prin reţea. O legătură poate fi dedicată unui singur flux de date sau poate transporta fluxuri diferite la momente de timp diferite. F specifică funcţiile asociate cu fiecare celulă de prelucrare, reprezentând totalitatea expresiilor pe care o celulă este capabilă să le calculeze. Se presupune că fiecare celulă conţine un număr mic de registre, un UAL şi logică de control. În aceeaşi reţea pot exista mai multe tipuri diferite de celule. T reprezintă temporizarea reţelei, furnizând pentru fiecare celulă momentele de timp la care se realizează calculul funcţiilor F şi comunicaţiile de date. O temporizare corectă asigură ca datele corespunzătoare să se găsească într-o anumită poziţie, la un anumit moment de timp. Sunt preferate reţelele cu viteze constante de comunicaţie a datelor, deoarece necesită un control mai simplu.
Pentru implementarea a numeroşi algoritmi se utilizează câteva tipuri de bază de module aritmetice VLSI: Modul de descompunere a unei matrici în produs de două submatrici triunghiulare inferioară L (“lower”) si superioara U (“upper”):
Modul de înmulţire matrice-vector: unde {bi i=1,2,…,p}, c şi d sunt vectori coloană m*1, iar {Ai i=1,2,…,p} sunt matrici m*m.
Întârzierile modulelor D şi I :2m unităţi de timp (într-o unitate de timp realizându-se o operaţie de înmulţire şi adunare a*b+c=d sau o operaţie de împărţire a/b=c). Întârzierile modulelor M şi V : pm+1 unităţi de timp. Deoarece modulele D, I şi M conţin m2 procesoare elementare, complexitatea interioară :O(m2). Complexitatea modulului V :O(m).
Singura operaţie comună tuturor algoritmilor consideraţi este o operaţie de adunare-înmulţire: c c + a * b pentru care se consideră un procesor elementar cu trei registre Ra, Rb şi Rc, fiecare registru având o intrare şi o ieşire. Există două geometrii de bază: a) procesor rectangular (produs matrice-vector, soluţii sisteme triunghiulare liniare); b) procesor hexagonal (produs de matrici, descompunerea LU a unei matrici pătrate).
Principalele tipuri de interconectări între procesoarele elementare: reţea liniară, reţea bidimensională ortogonală şi reţea bidimensională hexagonală.
Înmulţire matrice – vector Se consideră operaţia de înmulţire între o matrice A pătrată de n*n elemente şi un vector coloană x cu n elemente, obţinându-se un vector coloană y cu n elemente. Matricea A este de tip bandă, cu lăţimea de bandă w=p+q-1, unde p şi q reprezintă numărul de colane şi respectiv de linii de elemente, diferite de zero, în jurul diagonalei principale, toate celelalte elemente fiind zero (pentru exemplul considerat p=2, q=3, w=4).
Procesoarele sunt numerotate cu 1,2,…, w (în exemplul considerat w=4) de la stânga spre dreapta. Fiecare procesor are trei registre Ra, Rx şi Ry, iniţializate cu zero, pentru manipularea operanzilor. La cicluri impare sunt active procesoarele impare, iar la cicluri pare sunt active procesoarele pare. Fiecare pas al algoritmului constă din următoarele operaţii: -deplasare: Ra primeşte un nou element din A; Rx primeşte Rx al procesorului din stânga (procesorul 1 primeşte xi); Ry primeşte Ry al procesorului din dreapta (procesorul w primeşte 0). -înmulţire şi adunare: Ry Ry + Ra * Rx Un pas = o unitate de timp =>după w unităţi de timp componentele rezultatului încep să iasă din procesorul 1, cu o rată de ieşire de un rezultat la fiecare două unităţi de timp. Timpul total necesar efectuării înmulţirii matrice-vector: t = 2n + w în comparaţie cu O(wn) pe un sistem monoprocesor.
Înmulţire de matrici Se consideră înmulţirea a două matrici pătrate de n*n elemente, A şi B(de tip bandă, cu p1=2, q1=3, w1=4, p2=3, q2=2 şi w2=4), pentru a obţine o nouă matriceC.
Relaţii de recurenţă: Timpul necesar operaţiei de înmulţire a două matrici pătrate n*n, de tip bandă, cu lăţimile de bandăw1 şi w2 este: t = 3n + min (w1, w2) Se observă că în fiecare rând sau coloană a reţelei, din trei procesoare consecutive numai unul singur este activ la oricare moment de timp => este posibil ca prin reproiectarea procesoarelor să se micşoreze dimensiunea reţelei la w1w2/3 procesoare.
Descompunerea LU a unei matrici Matrice pătrataA-> două submatrici triunghiulare, de aceleaşi dimensiuni, L (lower), având elementele de deasupra diagonalei principale nule şi U (upper), având elementele de sub diagonala principală egale cu zero. Exemplu: o matrice de tip bandă cup=4 şi q=4 (lăţimea de bandă w=7).
Procesorul cerc: reciproca intrării -> rezultatul spre SV şi intrarea nemodificată spre N. Procesoarele de pe latura stânga sus sunt rotite cu 120 în sens orar; Procesoarele de pe latura dreapta sus sunt rotite cu 120, în sens antiorar.
A matrice bandă cu lăţimea w=p+q-1 => o reţea cu pq procesoare conectate hexagonal poate calcula descompunerea LU a matricii A, în : t = 3n + min (p, q) unităţi de timp. A matrice densă de n*n elemente (w=2n-1) => o reţea cun2 procesoare poate executa descompunerea LU în timpul t = 4n unităţi de timp, incluzând operaţiile de intrare/ieşire. Fiecare procesor lucrează numai la fiecare al treilea pas => prin reproiectarea procesoarelor se poate reduce dimensiunea reţelei la pq/3.
Rezolvarea sistemelor triunghiulare liniare Sistem liniar Ax=b-> descompunere LU a matricii A=> două sisteme triunghiulare liniare: Sistem triunghiular superior -> sistem triunghiular inferior => rezolvarea unui sistem triunghiular inferior. Reformularea problemei: fie A o matrice triunghiulară inferioară n*n, de tip bandă şi un vector coloană b de n elemente. Trebuie calculat vectorul coloană x de n elemente, astfel încât:
Relaţii de recurenţă: => reţea de procesoare rectangulare conectate liniar:
Valorile yi(iniţializate cu zero): dreapta -> stânga. Procesorul cerc: xi = ( bi – yi ) / aii În momentul în care yi a ajuns în marginea stângăare valoarea: yi = ai1x1 + ai2x2 + …+ ai,i-1 xi-1 xi se poate calcula de către procesorul cerc: xi = ( bi - yi ) / aii
Timpul necesar rezolvării unui sistem triunghiular liniar n*n, în care matricea coeficienţilor necunoscutelor este de tip bandă, cu lăţimea de bandă w=q : t = 2 n + q unităţi de timp.
Alte aplicaţii Problema convoluţiei a doi vectori a şi x-> înmulţire matrice-vector. Matricea construită cu elementele vectorului a este o matrice de tip Toeplitz (elementele de pe direcţii paralele cu diagonala principală sunt egale). Vectorul rezultat b :
Problema filtrului FIR (Finite Impulse Response) -> înmulţire matrice-vector (matrice tip Toeplitz, triunghiulară superioară, cu lărgimea de bandă w=p conţinând coeficienţii filtrului).
Transformata Fourier discretă (TFD) de n puncte -> înmulţire matrice-vector (elementul i,j al matricii este (i-1)(j-1), fiind o rădăcină de ordinul n a unităţii). Reţea conectată liniar de mărime n=> convoluţia a doi vectori de n elemente şi TFD de n puncte : => O(n) unităţi de timp (algoritm FFT - Fast Fourier Transform - secvenţial:O(n log n) unităţi de timp).