IR Models
IR Models. J. H. Wang Mar. 11, 2008. Text. User Interface. 4, 10. user need. Text. Text Operations. 6, 7. logical view. logical view. Query Operations. DB Manager Module. Indexing. user feedback. 5. 8. inverted file. query. Searching. Index. 8. retrieved docs. Text


IR Models
E N D
Presentation Transcript
IR Models J. H. Wang Mar. 11, 2008
Text User Interface 4, 10 user need Text Text Operations 6, 7 logical view logical view Query Operations DB Manager Module Indexing user feedback 5 8 inverted file query Searching Index 8 retrieved docs Text Database Ranking ranked docs 2 The Retrieval Process
Introduction • Traditional information retrieval systems usually adopt index terms to index and retrieve documents • An index term is a keyword (or group of related words) which has some meaning of its own (usually a noun) • Advantages • Simple • The semantic of the documents and of the user information need can be naturally expressed through sets of index terms
Docs Index Terms doc match Ranking Information Need query
IR Models • Ranking algorithms are at the core of information retrieval systems (predicting which documents are relevant and which are not).
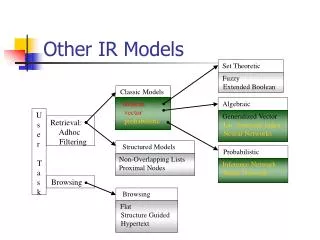
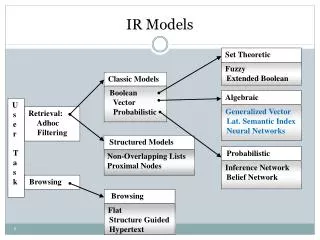
A Taxonomy of Information Retrieval Models Classic Models U S E R T A S K Set Theoretic Boolean Vector Probabilistic Fuzzy Extended Boolean Retrieval: Ad hoc Filtering Algebraic Structured Models Generalized Vector Lat. Semantic Index Neural Networks Non-overlapping lists Proximal Nodes Browsing Probabilistic Browsing Inference Network Belief Network Flat Structure Guided Hypertext
Index Terms Full Text Full Text+ Structure Retrieval Classic Set Theoretic Algebraic Probabilistic Classic Set Theoretic Algebraic Probabilistic Structured Browsing Flat Flat Hypertext Structure Guided Hypertext Figure 2.2 Retrieval models most frequently associated with distinct combinations of a document logical view and a user task.
Retrieval : Ad hoc and Filtering • Ad hoc (Search): The documents in the collection remain relatively static while new queries are submitted to the system • Routing (Filtering): The queries remain relatively static while new documents come into the system
Retrieval: Ad Hoc x Filtering • Ad hoc retrieval: Q1 Q2 Collection “Fixed Size” Q3 Q4 Q5
Retrieval: Ad Hoc x Filtering • Filtering: Docs Filtered for User 2 User 2 Profile User 1 Profile Docs for User 1 Documents Stream
A Formal Characterization of IR Models • D : A set composed of logical views (or representation) for the documents in the collection • Q : A set composed of logical views (or representation) for the user information needs (queries) • F : A framework for modeling document representations, queries, and their relationships • R(qi, dj) : A ranking function which defines an ordering among the documents with regard to the query
Definition • ki : A generic index term • K : The set of all index terms {k1,…,kt} • wi,j : A weight associated with index term ki of a document dj • gi: A function returns the weight associated with ki in any t-dimensional vector ( gi(dj)=wi,j )
Classic IR Model • Basic concepts: Each document is described by a set of representative keywords called index terms • Assign a numerical weights to distinct relevance between index terms • Three classic models: Boolean, vector, probabilistic
Boolean Model • Binary decision criterion • Either relevant or nonrelevant (no partial match) • Data retrieval model • Advantage • Clean formalism, simplicity • Disadvantage • It is not simple to translate an information need into a Boolean expression • Exact matching may lead to retrieval of too few or too many documents
Ka Kb (1,1,0) (1,0,0) (1,1,1) Kc Example • Can be represented as a disjunction of conjunctive vectors (in DNF) • Q= qa(qbqc)=(1,1,1) (1,1,0) (1,0,0) • Formal definition • For the Boolean model, the index term weight are all binary, i.e. wij {0,1} • A query is a conventional Boolean expression, which can be transformed to a disjunctive normal form (qcc: conjunctive component) if (qcc )(ki, wi,j=gi(qcc))
Vector Model [Salton, 1968] • Assign non-binary weights to index terms in queries and in documents => TFxIDF • Compute the similarity between documents and query => Sim(Dj, Q) • More precise than Boolean model
The IR Problem A Clustering Problem • We think of the documents as a collection C of objects and think of the user query as a specification of a set A of objects • Intra-cluster similarity • What are the features which better describe the objects in the set A? • Inter-cluster similarity • What are the features which better distinguish the objects in the set A?
Idea for TFxIDF • TF: intra-clustering similarity is quantified by measuring the raw frequency of a term ki inside a document dj • term frequency (the tf factor) provides one measure of how well that term describes the document contents • IDF: inter-clustering similarity is quantified by measuring the inverse of the frequency of a term ki among the documents in the collection • inverse document frequency (the idf factor)
Vector Model (1/4) • Index terms are assigned positive and non-binary weights • The index terms in the query are also weighted • Term weights are used to compute the degree of similarity between documents and the user query • Then, retrieved documents are sorted in decreasing order
Vector Model (2/4) • Degree of similarity
Vector Model (3/4) • Definition • normalized frequency • inverse document frequency • term-weighting schemes • query-term weights
Vector Model (4/4) • Advantages • Its term-weighting scheme improves retrieval performance • Its partial matching strategy allows retrieval of documents that approximate the query conditions • Its cosine ranking formula sorts the documents according to their degree of similarity to the query • Disadvantage • The assumption of mutual independence between index terms
k2 k1 d7 d6 d2 d4 d5 d3 d1 k3 The Vector Model: Example I
k2 k1 d7 d6 d2 d4 d5 d3 d1 k3 The Vector Model: Example II
k2 k1 d7 d6 d2 d4 d5 d3 d1 k3 The Vector Model: Example III
Probabilistic Model (1/6) • Introduced by Roberston and Sparck Jones, 1976 • Binary independence retrieval (BIR) model • Idea: Given a user query q, and the ideal answer set R of the relevant documents, the problem is to specify the properties for this set • Assumption (probabilistic principle): the probability of relevance depends on the query and document representations only; ideal answer set R should maximize the overall probability of relevance • The probabilistic model tries to estimate the probability that the user will find the document dj relevant with ratio P(dj relevant to q)/P(dj nonrelevant to q)
Probabilistic Model (2/6) • Definition • All index term weights are all binary i.e., wi,j {0,1} • Let R be the set of documents known to be relevant to query q • Let be the complement of R • Let be the probability that the document dj is relevant to the query q • Let be the probability that the document dj is nonelevant to query q
Probabilistic Model (3/6) • The similarity sim(dj,q) of the document dj to the query q is defined as the ratio • Using Bayes’ rule, • P(R) stands for the probability that a document randomly selected from the entire collection is relevant • stands for the probability of randomly selecting the document dj from the set R of relevant documents
Probabilistic Model (4/6) • Assuming independence of index terms and given q=(d1, d2, …, dt),
Probabilistic Model (5/6) • Pr(ki |R) stands for the probability that the index term ki is present in a document randomly selected from the set R • stands for the probability that the index term ki is not present in a document randomly selected from the set R
Estimation of Term Relevance In the very beginning: Next, the ranking can be improved as follows: For small values of V and Vi N Let V be a subset of the documents initially retrieved V dfi
Advantage • Documents are ranked in decreasing order of their probability of being relevant • Disadvantage • The need to guess the initial relevant and nonrelevant sets • Term frequency is not considered • Independence assumption for index terms
Brief Comparison of Classic Models • Boolean model is the weakest • Not able to recognize partial matches • Controversy between probabilistic and vector models • The vector model is expected to outperform the probabilistic model with general collections
Alternative Set Theoretic Models Fuzzy Set Model Extended Boolean Model
Fuzzy Theory • A fuzzy subset A of a universe U is characterized by a membership functionuA: U{0,1} which associates with each element uU a number uA • Let A and B be two fuzzy subsets of U,
Fuzzy Information Retrieval • Using a term-term correlation matrix • Define a fuzzy set associated to each index term ki • If a term klis strongly related to ki, that is ci,l ~1, then ui(dj)~1 • If a term klis loosely related to ki, that is ci,l ~0, then ui(dj)~0
Ka Kb cc2 cc3 cc1 Kc Example • Disjunctive Normal Form
Algebraic Sum and Product • The degree of membership in a disjunctive fuzzy set is computed using an algebraic sum, instead of max function • The degree of membership in a conjunctive fuzzy set is computed using an algebraic product, instead of min function • More smooth than max and min functions
Alternative Algebraic Models Generalized Vector Space Model Latent Semantic Model Neural Network Model
Sparse Matrix Problem • Considering a term-doc matrix of dimensions 1M*1M • Most of the entries will be 0 sparse matrix • A waste of storage and computation • How to reduce the dimensions?
Latent Semantic Indexing (1/5) • Let M=(Mij) be a term-document association matrix with t rows and N columns • Latent semantic indexing decomposes M using Singular Value Decompositions • K is the matrix of eigenvectors derived from the term-to-term correlation matrix (MMt) • Dt is the matrix of eigenvectors derived from the transpose of the document-to-document matrix (MtM) • S is an rr diagonal matrix of singular values, where r=min(t,N) is the rank of M
Latent Semantic Indexing (2/5) • Consider now only the s largest singular values of S, and their corresponding columns in K and Dt • (The remaining singular values of S are deleted) • The resultant matrix Ms (rank s) is closest to the original matrix M in the least square sense • s<r is the dimensionality of a reduced concept space
Latent Semantic Indexing (3/5) • The selection of s attempts to balance two opposing effects • s should be large enough to allow fitting all the structure in the real data • s should be small enough to allow filtering out all the non-relevant representational details
Latent Semantic Indexing (4/5) • Consider the relationship between any two documents
Latent Semantic Indexing (5/5) • To rank documents with regard to a given user query, we model the query as a pseudo-document in the original matrix M • Assume the query is modeled as the document with number k • Then the kth row in the matrix provides the ranks of all documents with respect to this query
Computing an Example • Let (Mij) be given by the matrix • Compute the matrices (K), (S), and (D)t
Latent Semantic Indexing transforms the occurrence matrix into a relation between the terms and concepts, and a relation between the concepts and the documents • Indirect relation between terms and documents through some hidden (or latent) concepts Taipei Taiwan … ? doc
Taipei Taiwan … (Latent)Concepts doc
Alternative Probabilistic Model Bayesian Networks Inference Network Model Belief Network Model