Single-Layer Perceptron: Architectures and Learning Methods
370 likes | 461 Vues
Explore the concepts of Adaline, a linear learning perceptron, and understand the differences in real-valued and binary outputs. Learn about the Perceptron, Madaline, and Backpropagation in Chapter 2.

Single-Layer Perceptron: Architectures and Learning Methods
E N D
Presentation Transcript
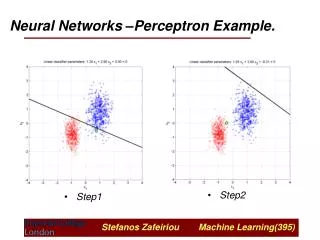
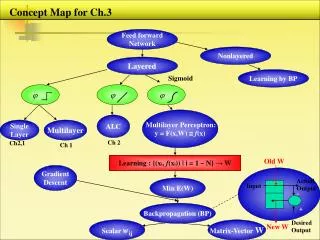
Ch 2. Concept Map Single Layer Perceptron = McCulloch – Pitts Type Learning starts in Ch 2 Architecture, Learning Adaline : Linear Learning Perceptron : Nonlinear Learning Real valued output Binary output Binary output Objective : W x> 0 , x ω₁ W x < 0 , x ω₂ T ⊂ T T • Objective : W x = Any Desired • Real Value • Can be used for Both • Classification / Regression Objective : W x = 1 +- ⊂ T • Correction for Correct Sign, too • No correction for correct sign • Always Finds Perfect hyperplanes • for Linearly Separable Cases • All Patterns x Move Hyperplanes • by an Amount Proportional to x • Finds Optimum Hyperplanes for • Linearly Nonseparable Cases • Error Patterns Push & Pull • Hyperplanes
x (n) 2 x (n) D ( ) n 1 y ( n ) ( n ) 2 e ( n ) d ( n ) Chapter 2. Single Layer Perceptron 1. Perceptron Ref. Perceptron, Madaline and Backpropagation, Widrow, Proc.IEEE 90. Rosenblatt - Perceptron Learning 2 D 1 Adjusted Training Set Adjustable Weights x (n) 1 Adder s(n) å M M M (n)=Bias D+1 1 (n) + D - Error signal response Desired
Perceptron Learning – Error Correction Learning • Initialize to zero or some random vector. 2) Input and Adjust the weights as follows: . α = Learning Rate that scales x. Rosenblatt set α = 1. The choice does not affect stability but it affects convergence time only if w(0) ≠ 0. A. Case 1: d(n) – y(n) = 1 or d(n) = 1 and y(n) =0 ; y(n+1) y(n) B. Case 2: d(n) – y(n) = –1 or d(n) = 0 and y(n) = 1 ; C. Case 3: d(n) = y(n) Do nothing. 3) Repeat 1)2) until No Classification Error for a Linearly Separable Case.
x ( 1 ) w ( 1 ) 0 w ( 2 ) 0 D ( 2 ) (2) Patterns of Classification Error - push and pull the decision hyperplanes. ( 1 ) D Same as (1) except
(3) Example – OR Learning x(1) pullsdown to , x(2) pulls up to . 3 1 2 2 or (0) X = 0 w T 1 : Error at x(1) 1 2 (1) X = 0 w (2) X = 0 T T 3 w Error at x(2) – Overcorrection 3 2 No Error for All Patterns– Terminate Learning
2. Adaptive Linear Element – ADALINE = Linear Neuron If d(n) = Real, Regression. If d(n) = Integer (0/1 or -1/+1), Classification. Perceptron Adaline s(n) y(n) x(n) - Perceptron error å D + D e(n) d(n)
- LMS Learning Rule – Normalized, controls stability and speed of conv. • In general, Data Set is not completely specified in advance. • LMS is good for training data stream drawn from stationary distribution at least for x(n) In practice 0.1 < <1 cf. -LMS : Instantaneous Gradient Descent
(2) Minimum Disturbance Principle – Adapt to reduce the Output Errorfor the Current Training Pattern, with Minimal disturbance to Responses already learned x(n) w(n+1) D w(n) w(n)
(3) Learning Rate Scheduling (Annealing) α, μ = Learning Rate, Step Size μ(n+1) = μ(n) – β or μ(n) = c/n or μ0 / [1 + n/τ] The Perceptron Learning Rule can also be derived from the LMS-Rule :
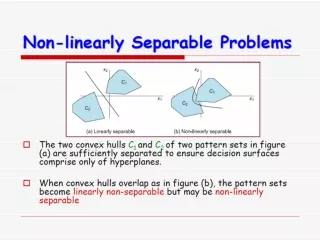
Perceptron Learning Works with binary (bipolar)outputs LMS Learning Works with both binary and analog Always converges for linearly separable cases - Theorem May not converge even for linearly separable cases May be unstable for linearly nonseparable cases – Use pocket Alg. Also works well for linearly nonseparable cases – finds minimum error solution No correction for correct classification Always corrects Objective: > 0 or < 0 Objective: = 1 or − 1 Nonlinear rule Linear rule
Graphical Representation of Learning For classification with Adaline, one could just stop learning when the signs are all correct – way to speed up Adaline learning. Perceptron ω 1 1 1 ω 1 Adaline After Learning -1 -1 ω ω 2 2
(4) ADALINE To Noise Cancellation, Equalization, Echo Cancellation
Student Questions -2005 • Adaline Learning takes longer than Perceptron in general. But, still it may have an edge over Perceptron in some aspect ? • Diff. between α–LMS and μ–LMS. Self-normalizing vs. const. Latter always converges in the mean to the minimum MSE solution. • Anyway to learn without desired outputs ? • What does it mean when Perceptron learning can be derived from LMS using J = … • Not clear on Regression. • How can we guarantee a whole system convergence ? • Which of Perceptron and Adaline performs better, is more efficient ?