
Backgammon
Players race to a) get all their men into their inner table, then b) move them to any imaginary point beyond their end point. Max 15 men per point. Backgammon.

Backgammon
E N D
Presentation Transcript
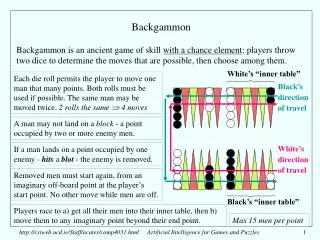
Players race to a) get all their men into their inner table, then b) move them to any imaginary point beyond their end point. Max 15 men per point Backgammon • Backgammon is an ancient game of skill with a chance element: players throw two dice to determine the moves that are possible, then choose among them. White’s “inner table” Each die roll permits the player to move one man that many points. Both rolls must be used if possible. The same man may be moved twice. 2 rolls the same 4 moves Black’s direction of travel A man may not land on a block - a point occupied by two or more enemy men. If a man lands on a point occupied by one enemy - hits a blot - the enemy is removed. White’s direction of travel Removed men must start again, from an imaginary off-board point at the player’s start point. No other move while men are off. Black’s “inner table” http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Gambling, Sizes of win • Backgammon is played for stakes (matchsticks? money?) and for championships. • If a player wins before his opponent has removed any men, he wins double. • If in addition the opponent still has men in his first quadrant, he wins triple. • There is a “doubling cube”, bearing the numbers 2,4,8,16,32,64. • A player may “double” - offer to continue the game for twice the stake. • If the opponent refuses, he resigns the game and loses the current stake. • If he accepts, only he may offer the next double. http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Search complexity of backgammon • On each turn, the two dice can be rolled in 21 different ways. • Typically there are around 20 moves possible for any result of the dice. • Therefore the branching factor is approx 400. • It is estimated there are around 1020 possible arrangements of the men. • Less than chess, go; • comparable with checkers, othello; • still much too large for exhaustive analysis. http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Berliner’s BKG program • In 1979 Berliner’s BKG9.8 won a 7-game exhibition match against Luigi Villa, the then World Champion. Caveats: • 7 games is too short a series to be conclusive, since luck plays a part • Villa had reason not to take the comic-robot program very seriously • It was an exhibition match, not a championship • BKG was a pure no-search Type-B program, it evaluated moves at 1 ply. • Its hand-crafted evaluation method was called SNAC • Smoothness (as opposed to generalised form of Horizon Effect) • Non-linearity (importance of features inter-dependent, not just additive) • Application Coefficients (program computed higher-level features, the evaluation function was not expressed directly in terms of positions of men) http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Tesauro’s TD-GAMMON • TD-Gammon was (primarily) a connectionist system. • It learnt move decisions by self-play, it had hand-crafted doubling algorithm. • Its two main features were • Use of the “Method of Temporal Differences” to solve the (temporal) credit assignment problem • Use of “Rollout analysis” to generate reliable statistics • TD-Gammon did (in mid-1990s) play the then champion, and other world-class players, in substantial numbers of games, and showed near parity with them. http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Inputs Hidden layer Outputs win x2 w@3:1 w@3:2 w@3:3 w@3:4+ win x1 all hidden connect to all outputs all inputs connect to all hidden lose x1 lose x2 MLP (Multi Layer Perceptron) http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Temporal Difference learning • TD learning applies when a series of choices leads to an eventual outcome. • Like reinforcement learning, over many trials, • those choices that lead to good outcomes should be preferred • those choices that lead to bad outcome should be deprecated • The essence of TD learning is that • the valuation of a situation before a choice is made • should become more similar to • the valuation of the situation after the choice is made • Situations just before a win (or loss) should be assessed virtually as if they themselves were a win (loss) - and so on back through all prior choices. http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Learning from self play vs Tuition • Human experts are good, but fallible. • They get tired, make mistakes, cannot communicate everything. • Community opinions change over time • Indeed TD-Gammon rollouts have helped change expert opinion! • Very large numbers of games can be self-played by machine. • 200k training games and TD-Gammon showed “feature discovery” • Successive versions with more training showed continuing improvements vis à vis top class players • Danger of self-play: random strategy at start may be very bad http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Early learning • A danger in learning by self play is that the random strategy at the beginning of learning may be very bad. • Games may last 1000’s of moves, rather than the typical 50-60 • Nothing of value might then be learnt. • TD-Gammon however did learn some elementary tactics and strategy from its early games. The trend towards the end of the game, forced by the generally forward movement of men, meant that even random games were brief. • By scoring every possible move, choosing the one with highest expected outcome, it learnt early on some basic concepts: • hit the opponent; play safe; build blocks • Later learning could build on this to discover interesting evaluation features http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Judgment and Calculation • Experts commenting on TD-Gammon’s play noted contrast with chess programs: • Chess programs excel at laborious calculation but show poor judgment • TD-Gammon showed good positional judgment • Pure TD-learning from experience, using only raw coding of positions, enabled TD-Gammon to match the performance of Tesauro’s earlier NeuroGammon. • Adding further inputs - giving access to precomputed tables of “strength of blockade”, precomputed “probability of being hit” - brought TD-Gammon to near parity with world championship level. http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Rollout Analysis • TD-Gammon also performs the most trusted “rollout analysis” operation: • Where commentators & analysts look over championship games, they sometimes disagree about the merits of positions resulting from alternative possible moves. A “rollout” can be used to determine which is better: • from each resulting position, generate and play out 10,000 random dice sequences, pick the move that gives the best result • Even though the absolute error in the original scoring might be large, the relative error would not be - faults in the evaluations of related positions are highly correlated. http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
Rare success for TD learning • TD learning was very successfully applied in TD-Gammon; but it has not proved so successful in other domains. Possible reasons for its success at backgammon: • because of the nature of the rules of backgammon, even a random strategy gives sequences brief enough to be learned from. Go could go on for ages. • the randomness of the dice causes noise, meaning that the same strategy will on different occasions explore different parts of the search space. The learner will not play deterministically and get stuck on a poor strategy. (Noise Injection has been found helpful in other applications) • there are simple “linear” concepts that can be learned early (blots are bad, blocks are good, bear off asap), and later learning can bootstrap from these. http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles
References • Berliner, H. 1980. Performance Note: Backgammon computer program beats world champion. Artificial Intelligence v.14 pp205-220 • Tesauro, G. 1995. Temporal Difference learning and TD-Gammon. CACM v38:3 pp58-68 http://csiweb.ucd.ie/Staff/acater/comp4031.html Artificial Intelligence for Games and Puzzles





![get [PDF] Download Backgammon: From Basics to Badass](https://cdn7.slideserve.com/12382760/slide1-dt.jpg)

