Download

1 / 46
470 likes | 776 Vues
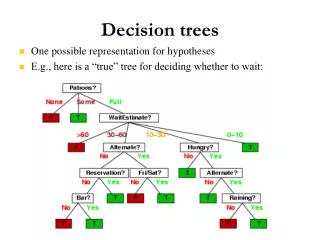
Decision Trees and Decision Tree Learning Philipp Kärger. Outline: Decision Trees Decision Tree Learning ID3 Algorithm Which attribute to split on? Some examples Overfitting Where to use Decision Trees?. Decision tree representation for PlayTennis. Outlook. Sunny. Overcast. Rain.

E N D
Outline: • Decision Trees • Decision Tree Learning • ID3 Algorithm • Which attribute to split on? • Some examples • Overfitting • Where to use Decision Trees?
Decision tree representation for PlayTennis Outlook Sunny Overcast Rain Humidity Yes Wind Weak Strong Normal High No Yes Yes No
Decision tree representation for PlayTennis Outlook Attribute Sunny Overcast Rain Humidity Yes Wind Weak Strong Normal High No Yes Yes No
Decision tree representation for PlayTennis Outlook Value Sunny Overcast Rain Humidity Yes Wind Weak Strong Normal High No Yes Yes No
Decision tree representation for PlayTennis Outlook Classification Sunny Overcast Rain Humidity Yes Wind Weak Strong Normal High No Yes Yes No
Logical expression for PlayTennis=Yes: (Outlook=Sunny Humidity=Normal) (Outlook=Overcast) (Outlook=Rain Wind=Weak) If-then rules IF Outlook=Sunny Humidity=Normal THEN PlayTennis=Yes IF Outlook=Overcast THEN PlayTennis=Yes IF Outlook=Rain Wind=Weak THEN PlayTennis=Yes IF Outlook=Sunny Humidity=High THEN PlayTennis=No IF Outlook=Rain Wind=Strong THEN PlayTennis=Yes PlayTennis:Other representations
Decision Trees - Summary • a model of a part of the world • allows us to classify instances (by performing a sequence of tests) • allows us to predict classes of (unseen) instances • understandable by humans (unlike many other representations)
Goal:Learn from known instances how to classify unseen instances • by means of building and exploiting a Decision Tree • supervised or unsupervised learning?
Classification Task Application:classification of medical patients by their disease seen patients DecisionTree unseen patients rules telling whichattributes of the patient indicates a disease check attributes of an unseen patient
Basic algorithm: ID3 (simplified) ID3 = Iterative Dichotomiser 3 - given a goal class to build the tree for - create a root node for the tree - if all examples from the test set belong to the same goal class C then label the root with C - else • select the ‘most informative’ attribute A • split the training set according to the values V1..Vn of A • recursively build the resulting subtrees T1 … Tn • generate decision tree T: A Humidity vn v1 ... Low High T1 Tn ... No Yes
lessons learned: • there is always more than one decision tree • finding the “best” one is NP complete • all the known algorithms use heuristics • finding the right attribute A to split on is tricky
Search heuristics in ID3 • Which attribute should we split on? • Need a heuristic • Some function gives big numbers for “good” splits • Want to get to “pure” sets • How can we measure “pure”? odd even sunny rain
Measuring Information: Entropy • The average amount of information I needed to classify an object is given by the entropy measure • For a two-class problem: p(c) = probability of class Cc(sum over all classes) entropy p(c)
What is the entropy of the set of happy/unhappy days? odd even sunny rain
Residual Information • After applying attribute A, S is partitioned into subsets according to values v of A • Iresrepresents the amount of information still needed to classify an instance • Ires is equal to weighted sum of the amounts of information for the subsets p(c|v) = probability that an instance belongs to class C given that it belongs to v =I(v)
What is Ires(A) if I split for “weather” and ifI split for “day”? odd even sunny rain Ires(weather) = 0 Ires(day) = 1
Information Gain: = the amount of information I rule out by splitting on attribute A: Gain(A) = I – Ires(A) = information in the current set minus the residual information after splitting The most ‘informative’ attribute is the one that minimizes Ires, i.e., maximizes the Gain
Triangles and Squares Data Set: A set of classified objects . . . . . .
Entropy • 5 triangles • 9 squares • class probabilities • entropy of the data set . . . . . .
. . . . . . . . red green yellow . . . . Entropyreductionbydata setpartitioning Color?
. . . . . . . . . . . . red Color? green residual information yellow
. . . . . . Information Gain . . . . . . red Color? green yellow
Information Gain of The Attribute • Attributes • Gain(Color) = 0.246 • Gain(Outline) = 0.151 • Gain(Dot) = 0.048 • Heuristics: attribute with the highest gain is chosen • This heuristics is local (local minimization of impurity)
. . . . . . . . . . . . red Color? green yellow Gain(Outline) = 0.971 – 0 = 0.971 bits Gain(Dot) = 0.971 – 0.951 = 0.020 bits
. . . . . . . . . . . . . . red Gain(Outline) = 0.971 – 0.951 = 0.020 bits Gain(Dot) = 0.971 – 0 = 0.971 bits Color? green yellow solid Outline? dashed
. . . . . . . . . . . . . . red . yes Dot? . Color? no green yellow solid Outline? dashed
Decision Tree . . . . . . Color red green yellow Dot square Outline yes no dashed solid triangle square triangle square
A Defect of Ires • Ires favors attributes with many values • Such attribute splits S to many subsets, and if these are small, they will tend to be pure anyway • One way to rectify this is through a corrected measure of information gain ratio.
Information Gain Ratio • I(A) is amount of information needed to determine the value of an attribute A • Information gain ratio
. . . . . . Information Gain Ratio . . . . . . red Color? green yellow
Overfitting Overfitting Underfitting: when model is too simple, both training and test errors are large
Notes on Overfitting • Overfitting results in decision trees that are more complex than necessary • Training error no longer provides a good estimate of how well the tree will perform on previously unseen records
How to Address Overfitting Idea: prune the tree so that it is not too specific Two possibilities: Pre-Pruning - prune while building the tree Post-Pruning - prune after building the tree
How to Address Overfitting • Pre-Pruning (Early Stopping Rule) • Stop the algorithm before it becomes a fully-grown tree • More restrictive stopping conditions: • Stop if number of instances is less than some user-specified threshold • Stop if expanding the current node does not improve impurity measures (e.g., information gain). • Not successful in practice
How to Address Overfitting… • Post-pruning • Grow decision tree to its entirety • Trim the nodes of the decision tree in a bottom-up fashion • If generalization error improves after trimming, replace sub-tree by a leaf node. • Class label of leaf node is determined from majority class of instances in the sub-tree
Occam’s Razor • Given two models of similar generalization errors, one should prefer the simpler model over the more complex model • For complex models, there is a greater chance that it was fitted accidentally by errors in data • Therefore, one should prefer less complex models in general
Appropriate problems for decision tree learning • Classification problems • Characteristics: • instances described by attribute-value pairs • target function has discrete output values • training data may be noisy • training data may contain missing attribute values
Strengths • can generate understandable rules • perform classification without much computation • can handle continuous and categorical variables • provide a clear indication of which fields are most important for prediction or classification
Weakness • Not suitable for prediction of continuous attribute. • Perform poorly with many class and small data. • Computationally expensive to train. • At each node, each candidate splitting field must be sorted before its best split can be found. • In some algorithms, combinations of fields are used and a search must be made for optimal combining weights. • Pruning algorithms can also be expensive since many potential sub-trees must be formed and compared