polyomx
www.polyomx.org. Analysis of Single Nucleotide Polymorphisms in Candidate Genes and Application of Machine Learning Techniques for assessing Susceptibility to Breast Cancer in Alberta Women. Dufour J 1 , Wang Y 1,2 , Cass CE 1,3,4 , Greiner R 1,2 , Mackey J 1,3 and Damaraju S 1,3,4

polyomx
E N D
Presentation Transcript
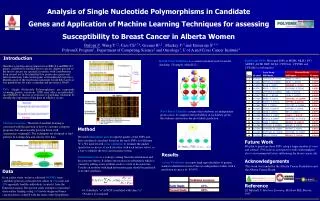
www.polyomx.org Analysis of Single Nucleotide Polymorphisms in Candidate Genes and Application of Machine Learning Techniques for assessing Susceptibility to Breast Cancer in Alberta Women Dufour J1, Wang Y1,2, Cass CE1,3,4, Greiner R1,2 , Mackey J1,3 and Damaraju S1,3,4 PolyomX Program1, Department of Computing Science2 and Oncology3, U of A and Cross Cancer Institute4 - - Introduction Hereditary predisposition (mutations in BRCA1 and BRCA2 genes) contribute to familial breast cancers. Eighty percent of the breast cancers are sporadic in nature, with contributions from several yet to be identified low penetrance genes and their interactions with carcinogenic environmental exposures. Identification of the molecular signatures would help target at-risk populations for early screening and preventive efforts. SNPs (Single Nucleotide Polymorphisms) are commonly occurring genetic variations. SNPs may affect an individual's susceptibility to disease or response to particular treatment by altering the expression of the gene in which it occurs. Significant SNPs: We found SNPs in MSH6, MLH1, P53, ADPRT, AGTR, RET, BCL6, CYP19A1, CYP1B1 and CYP11B2 as informative. K-fold Cross Validation is a common method used for model checking. ( Example: when K=3) - - - Naïve Bayes Classifier assumes that attributes are independent given a class. It computes the probability of each label, given the evidence and returns the most likely prediction. Machine Learning: The field of machine learning is concerned with the question of how to construct computer programs that automatically perform better with (experience) training[1]. The techniques are designed to find patterns in training data and classify new data. Method We used information gain to rank the quality of the SNPs and then considered classifiers based on the top k SNPs, for different "k”s. We used 20-fold cross validation to estimate the quality (predictive accuracy) of each classifier with each feature subset, as a way to identify the best classification system. Future Work We plan to genotype these SNPs using a larger number of cases and controls (750 each) in a prospective study with emphasis also to environmental factors influencing the breast cancer risk. Acknowledgements Results Cancer Prediction: we report high reproducibility of genetic markers identified in each of the two independent studies with a prediction accuracy of 63-65%. Information Gain is a concept coming from the information and decision tree theory. It defines the increase in information which is caused by adding a new attribute node to a rule or decision tree. Usually an attribute with high information gain should be preferred over other attributes. This work was funded by the Alberta Cancer Foundation and the Alberta Cancer Board. Data In an earlier study, we have validated 98 SNPs from candidate genes in a retrospective cohort of 174 cases and 158 apparently healthy individuals (controls) from the Edmonton region. The present study attempts to reproduce these earlier findings using 169 newly diagnosed breast cancer patients, coupled with the same control population. - - Reference [1] Mitchell, T. Machine Learning. McGraw-Hill, Boston, 1997. • 0 if attribute “a” is NOT correlated with class “c” • Positive if correlated