Vector Space Model
Vector Space Model. Rong Jin. How to represent text objects. How to refine query according to users’ feedbacks?. What similarity function should be used?. Basic Issues in A Retrieval Model. Basic Issues in IR. How to represent queries? How to represent documents?


Vector Space Model
E N D
Presentation Transcript
Vector Space Model Rong Jin
How to represent text objects How to refine query according to users’ feedbacks? What similarity function should be used? Basic Issues in A Retrieval Model
Basic Issues in IR • How to represent queries? • How to represent documents? • How to compute the similarity between documents and queries? • How to utilize the users’ feedbacks to enhance the retrieval performance?
IR: Formal Formulation • Vocabulary V={w1, w2, …, wn} of language • Query q = q1,…,qm, where qi V • Collection C= {d1, …, dk} • Document di = (di1,…,dimi), where dij V • Set of relevant documents R(q) C • Generally unknown and user-dependent • Query is a “hint” on which doc is in R(q) • Task = compute R’(q), an “approximate R(q)”
Computing R(q) • Strategy 1: Document selection • Classification function f(d,q) {0,1} • Outputs 1 for relevance, 0 for irrelevance • R(q) is determined as a set {dC|f(d,q)=1} • System must decide if a doc is relevant or not (“absolute relevance”) • Example: Boolean retrieval
Document Selection Approach True R(q) Classifier C(q) - - + - + - + + - + - - - - - - - - - - -
Computing R(q) • Strategy 2: Document ranking • Similarity function f(d,q) • Outputs a similarity between document d and query q • Cut off • The minimum similarity for document and query to be relevant • R(q) is determined as the set {dC|f(d,q)>} • System must decide if one doc is more likely to be relevant than another (“relative relevance”)
0.98 d1 + 0.95 d2 + 0.83 d3 - 0.80 d4 + 0.76 d5 - 0.56 d6 - 0.34 d7 - 0.21 d8 + 0.21 d9 - R’(q) Doc Ranking f(d,q)=? Document Selection vs. Ranking True R(q) - - + - + - + + - + - - - - - - - - - - -
R’(q) 1 Doc Selection f(d,q)=? - - - - + - - - - 0 + - + - + + + - 0.98 d1 + 0.95 d2 + 0.83 d3 - 0.80 d4 + 0.76 d5 - 0.56 d6 - 0.34 d7 - 0.21 d8 + 0.21 d9 - R’(q) Doc Ranking f(d,q)=? Document Selection vs. Ranking True R(q) - - + - + - + + - + - - - - - - - - - - -
Ranking is often preferred • Similarity function is more general than classification function • The classifier is unlikely to be accurate • Ambiguous information needs, short queries • Relevance is a subjective concept • Absolute relevance vs. relative relevance
Probability Ranking Principle • As stated by Cooper • Ranking documents in probability maximizes the utility of IR systems “If a reference retrieval system’s response to each request is a ranking of the documents in the collections in order of decreasing probability of usefulness to the user who submitted the request, where the probabilities are estimated as accurately as possible on the basis of whatever data made available to the system for this purpose, then the overall effectiveness of the system to its users will be the best that is obtainable on the basis of that data.”
Vector Space Model • Any text object can be represented by a term vector • Examples: Documents, queries, sentences, …. • A query is viewed as a short document • Similarity is determined by relationship between two vectors • e.g., the cosine of the angle between the vectors, or the distance between vectors • The SMART system: • Developed at Cornell University, 1960-1999 • Still used widely
Starbucks ? ? D2 ? ? ? ? D4 D3 Java Query D1 Microsoft ?? Vector Space Model: illustration
Vector Space Model: Similarity • Represent both documents and queries by word histogram vectors • n: the number of unique words • A query q = (q1, q2,…, qn) • qi: occurrence of the i-th word in query • A document dk = (dk,1, dk,2,…, dk,n) • dk,i: occurrence of the the i-th word in document • Similarity of a query q to a document dk q dk
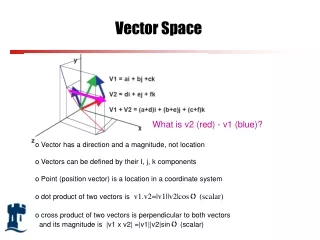
Some Background in Linear Algebra • Dot product (scalar product) • Example: • Measure the similarity by dot product
Some Background in Linear Algebra • Length of a vector • Angle between two vectors q dk
Some Background in Linear Algebra • Example: • Measure similarity by the angle between vectors q dk
Vector Space Model: Similarity • Given • A query q = (q1, q2,…, qn) • qi: occurrence of the i-th word in query • A document dk = (dk,1, dk,2,…, dk,n) • dk,i: occurrence of the the i-th word in document • Similarity of a query q to a document dk q dk
Term Weighting • wk,i: the importance of the i-th word for document dk • Why weighting ? • Some query terms carry more information • TF.IDF weighting • TF (Term Frequency) = Within-doc-frequency • IDF (Inverse Document Frequency) • TF normalization: avoid the bias of long documents
TF Weighting • A term is important if it occurs frequently in document • Formulas: • f(t,d): term occurrence of word ‘t’ in document d • Maximum frequency normalization: Term frequency normalization
TF Weighting • A term is important if it occurs frequently in document • Formulas: • f(t,d): term occurrence of word ‘t’ in document d • “Okapi/BM25 TF”: Term frequency normalization doclen(d): the length of document d avg_doclen: average document length k,b: predefined constants
TF Normalization • Why? • Document length variation • “Repeated occurrences” are less informative than the “first occurrence” • Two views of document length • A doc is long because it uses more words • A doc is long because it has more contents • Generally penalize long doc, but avoid over-penalizing (pivoted normalization)
TF Normalization Norm. TF Raw TF “Pivoted normalization”
IDF Weighting • A term is discriminative if it occurs only in a few documents • Formula: IDF(t) = 1+ log(n/m) n – total number of docs m -- # docs with term t (doc freq) • Can be interpreted as mutual information
TF-IDF Weighting • TF-IDF weighting : • The importance of a term t to a document d weight(t,d)=TF(t,d)*IDF(t) • Freq in doc high tf high weight • Rare in collection high idf high weight
TF-IDF Weighting • TF-IDF weighting : • The importance of a term t to a document d weight(t,d)=TF(t,d)*IDF(t) • Freq in doc high tf high weight • Rare in collection high idf high weight • Both qiand dk,i arebinary values, i.e. presence and absence of a word in query and document.
Problems with Vector Space Model • Still limited to word based matching • A document will never be retrieved if it does not contain any query word • How to modify the vector space model ?
Starbucks Java Microsoft Choice of Bases D Q D1
Starbucks Java Microsoft Choice of Bases D Q D1
Starbucks Java Microsoft Choice of Bases D’ D Q D1
Starbucks Java Microsoft Choice of Bases D’ D Q Q’ D1
Starbucks Java Microsoft Choice of Bases D’ Q’ D1
Choosing Bases for VSM • Modify the bases of the vector space • Each basis is a concept: a group of words • Every document is a vector in the concept space A1 A2
Choosing Bases for VSM • Modify the bases of the vector space • Each basis is a concept: a group of words • Every document is a mixture of concepts A1 A2
Choosing Bases for VSM • Modify the bases of the vector space • Each basis is a concept: a group of words • Every document is a mixture of concepts • How to define/select ‘basic concept’? • In VS model, each term is viewed as an independent concept
Linear Algebra Basic: Eigen Analysis • Eigenvectors(for a square mm matrix S) • Example (right) eigenvector eigenvalue
Linear Algebra Basic: Eigen Decomposition S = U * * UT
Linear Algebra Basic: Eigen Decomposition S = U * * UT
Linear Algebra Basic: Eigen Decomposition • This is generally true for symmetric square matrix • Columns of U are eigenvectors of S • Diagonal elements of are eigenvalues of S S = U * * UT
mm mn V is nn Singular Value Decomposition For an m n matrix Aof rank rthere exists a factorization (Singular Value Decomposition = SVD) as follows: The columns of U are left singular vectors. The columns of V are right singular vectors is a diagonal matrix with singular values
Singular Value Decomposition • Illustration of SVD dimensions and sparseness
Singular Value Decomposition • Illustration of SVD dimensions and sparseness
Singular Value Decomposition • Illustration of SVD dimensions and sparseness
Low Rank Approximation • Approximate matrix with the largest singular values and singular vectors