GPU Computing
GPU Computing. Burim Kameri Fachhochschule Hannover (FHH) Institut für Solarforschung Hameln (ISFH). Inhalt. Motivation Sequentielle vs. parallele Programmierung GPGPU – OpenCL Beispiel – Matrix-Skalar-Multiplikation Optimierung Zusammenfassung. Motivation.


GPU Computing
E N D
Presentation Transcript
GPU Computing BurimKameri Fachhochschule Hannover (FHH) Institut für Solarforschung Hameln (ISFH)
GPU - Computing Inhalt • Motivation • Sequentielle vs. parallele Programmierung • GPGPU – OpenCL • Beispiel – Matrix-Skalar-Multiplikation • Optimierung • Zusammenfassung
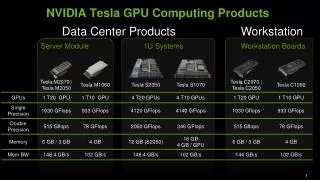
GPU - Computing Motivation
GPU - Computing Sequentielle vs. parallele Programmierung • Sequentielle Programmierung Quelle: https://computing.llnl.gov/tutorials/parallel_comp/
GPU - Computing Sequentielle vs. parallele Programmierung • Parallele Programmierung Quelle: https://computing.llnl.gov/tutorials/parallel_comp/
GPU - Computing GPGPU - OpenCL „localmemory“ ist um 100x-150x schneller als der „global memory“! • Zusätzliche Verwendung der GPU für allgemeine Aufgaben memory localmemory privat memory global andconstantmemory Quelle: CUDA C Programming Guide Quelle: http://de.wikipedia.org/wiki/OpenCL
GPU - Computing Beispiel (Matrix-Skalar-Multiplikation) • CPU • GPU (OpenCL) voidmultMatrix(float* A, float c, float* B) { for( i = 0;i < 225;i++ ) { B[i] = A[i] * c; } } __kernel__ voidmultMatrix(float* A, float c, float* B) { intidx = get_global_id(0); B[idx] = A[idx] * c; }
GPU - Computing Optimierung
GPU - Computing Zusammenfassung • Aufteilung des Domänenproblems • Tieferes Verständnis des Domänenproblems nötig • Wissen über das Programmiermodell • work-items, work-groups, Kernels, Speicherhirachien, etc. • Synchronisierung • Tiefes Wissen über die GPU-Architektur • Shared Memory • Kontrollstrukturen mit bedingten Verzweigungen vermeiden
GPU - Computing Dankeschön! Fragen?