
Analyzing Memory Performance and Bandwidth in High-Performance Computing Applications
This work investigates the memory hierarchy performance of high-performance computing applications, focusing on the DGEMV kernel. We present a detailed analysis of memory references, L1 and L2 hit rates, and bandwidth metrics using simulations and experiments. The study identifies performance bottlenecks and proposes optimizations based on fundamental application characteristics. Tools and frameworks such as PAPI, Sigma++, and compiler methods are utilized to understand and measure application performance. Key contributors include leading national laboratories and universities, ensuring a comprehensive approach to enhancing memory performance in scientific computing.

Analyzing Memory Performance and Bandwidth in High-Performance Computing Applications
E N D
Presentation Transcript
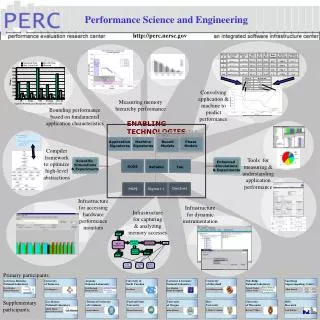
Block # Procedure Name Memory Ref. Mem. Ref. % L1 hit Rate L2 hit Rate Ratio Random Memory Bandwidth Weighted Bandwidth Block # Bandwidth 180155 dgemv_n 4.82E+09 0.9198 93.47 93.48 0.07 4166.0 3831.7 source files 180159 dgemv_n 1.42E+08 0.0271 90.33 90.39 0.00 1809.2 49.1 Performance Science and Engineering 180155 dumpMap .addr 180160 dgemv_n 1.22E+08 0.0232 94.81 99.89 0.00 5561.3 129.3 180159 SigmaCompile/Link 5885 MatSetValues 6.56E+07 0.0125 77.32 90.00 0.20 1522.6 19.0 180160 ProgramExecution trace files Instrumentedbinary 5885 http://perc.nersc.gov .lst files CacheSimulator PredictionTool MemoryRef Tool Enhanced Simulations & Experiments 2831.7 49.1 Mflop/s 129.3 19.0 Convolvingapplication &machine topredictperformance Analytic Performance Bounds for a PETSc Kernel Measuring memoryhierarchy performance Bounding performancebased on fundamentalapplication characteristics ENABLING TECHNOLOGIES C O N V O L U T I O N S Application Signatures Machine Signatures Bound Models Phase Models Compilerframeworkto optimizehigh-levelabstractions Tools formeasuring &understandingapplicationperformance Scientific Simulations & Experiments MAPS for TCSini for random and non-random loads SvPablo Tau ROSE DynInst PAPI Sigma++ Infrastructurefor accessinghardwareperformancemonitors Infrastructurefor dynamicinstrumentation Infrastructurefor capturing& analyzingmemory accesses Primary participants: Lawrence BerkeleyNational Laboratory Universityof Tennessee ArgonneNational Laboratory University of North Carolina Lawrence LivermoreNational Laboratory Universityof Maryland Oak RidgeNational Laboratory San DiegoSupercomputing Center Dan QuinlanBronis de Supinski David BaileyErich Strohmaier Paul HovlandBoyana Norris Patrick Worley Jeffrey Vetter Allan Snavely Jack Dongarra Dan Reed Jeff Hollingsworth Supplementaryparticipants: Los AlamosNational Laboratory Technical Universityof Catalonia Portland StateUniversity Universityof Oregon RiceUniversity Universityof Wisconsin IBMResearch Karen Karavanic Adolfy HoisieHarvey Wasserman J. Mellor-Crummey Barton P. Miller Luiz DeRose Jesús Labarta Allen Malony