SYNTAX ANALYSIS - II
This document offers an in-depth look at bottom-up parsing techniques, covering key concepts such as parse trees, handle pruning, and shift-reduce parsing. It discusses how bottom-up parsing operates by reducing strings to the start symbol of the grammar via a systematic sequence of reductions, and introduces the stack structure used in shift-reduce parsing. The guide aims to facilitate understanding of automatic parser generation and the handling of LR grammars, along with tackling common conflicts faced during parsing processes.


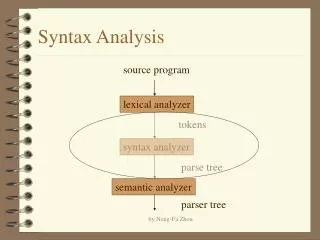
SYNTAX ANALYSIS - II
E N D
Presentation Transcript
UNIT - 3 SYNTAX ANALYSIS - II -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
BOTTOM-UP PARSING • Constructs a parse tree beginning at the leaves and working up towards the root • Bottom-up parse for id*id • Can handle a larger class of grammars (LR grammars) • Suitable for automatic parser generation -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
BOTTOM-UP PARSING • REDUCTIONS • Bottom-up parsing is the process of “reducing” a string w to the start symbol of the grammar • At each reduction step, a specific substring matching the body of a production is replaced by the nonterminal at the head of the production • Key decisions are when to reduce and what production to apply • The previous sequence of reductions can be discussed in terms of sequence of strings id * id, F * id, T * id, T * F, T, E • A reduction is the reverse of a step in a derivation where a nonterminal is replaced by the body of one of its productions • The goal is to construct a derivation in reverse -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
BOTTOM-UP PARSING • HANDLE PRUNING • A “handle” is a substring that matches the body of a production, and whose reduction represents one step along the reverse of a rightmost derivation • The handles during the parse of id1 * id2 • The leftmost substring that matches the body of some production need not be a handle -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
BOTTOM-UP PARSING • HANDLE PRUNING • If , then the production in the position following αis a handle of αβw • A handle of a right-sentential form γ is a production A β and a position of γ where the string β may be found • Such that replacing βat that position by A produces the previous right-sentential form in a rightmost derivation of γ • A rightmost derivation in reverse can be obtained by “handle pruning” • Start with a string of terminals w to be parsed. • If w is a sentence of the grammar, then let w = γn , where γn is the nth right-sentential form of some unknown rightmost derivation -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Shift-Reduce Parsing • Stack holds grammar symbols and an input buffer holds the rest of the string to be parsed • The handle always appears at the top of the stack just before it is identified as the handle • Initially the stack is empty, and the string w is on the input STACK INPUT $ w$ • During left-to-right scan, the parser shifts zero or more input symbols onto the stack until it is ready to reduce a string β on top of the stack • It then reduces βto the head of the appropriate production • The parser repeats this until it has detected an error or until stack contains the start symbol and input is empty STACK INPUT $S$ The parser now halts and announces successful completion of parsing -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Shift-Reduce Parsing • Configurations of a Shift-Reduce parser on the input string id1 * id2 -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Shift-Reduce Parsing • Four actions a shift-reduce parser can make • Shift • Shift the next input symbol onto the top of the stack • Reduce • The right end of the string to be reduced must be at the top of the stack • Locate the left end of the string within the stack and decide with what nonterminal to replace the string • Accept • Announce successful completion of parsing • Error • Discover a syntax error and call an error recovery routine -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Shift-Reduce Parsing • The use of stack in shift-reduce can be justified by the fact that the handle will always appear on top of the stack and not inside -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Conflicts During Shift-Reduce Parsing • There are CFG’s for which shift-reduce parsing cannot be used • Every shift-reduce parser for such a grammar can reach a configuration in which the parser knowing the entire stack contents and next input symbol • Cannot decide whether to shift or to reduce (a shift/reduce conflict) • Cannot decide which reductions to make (a reduce/reduce conflict) • Examples • Dangling-else grammar -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Introduction to LR Parsing : Simple LR • LR(k) Parsing • “L” : left to right scanning of the input • “R” : constructing a rightmost derivation in reverse • k : number of input symbols of lookahead used in making parsing decisions • Introduce basic concepts of LR parsing and methods for constructing shift-reduce parsers called “simple LR” (SLR) • Discuss about “items” and “parser states”; the diagnostic output from an LR parser generator includes parser states -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Why LR Parsers? • LR Parsers are table-driven like non-recursive LL parsers • For a grammar to be LR, it is sufficient that a left-to-right shift-reduce parser be able to recognize handles of right-sentential forms when they appear on top of the stack • Why LR Parsers? • Can be constructed to recognize all programming language constructs for which CFG’s can be written • Most general non-backtracking shift-reduce parsing method and can be implemented as efficiently as primitive shift-reduce methods • Can detect syntactic error as soon as possible on a left-to-right scan • Class of grammars that can be parsed using LR methods is a proper superset of the class of grammars that can be parsed with predictive or LL methods -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Items and LR(0) Automaton • How does a shift-reduce parser know when to shift and to reduce? • Example: with stack contents $T and next input symbol *, how does the parser know that T on top of the stack is not a handle, so action is to shift and not reduce • LR parser makes shift-reduce decisions by maintaining states to keep track of where we are in a parse • States represent set of “items” • An LR(0) item of a grammar G is a production of G with a dot at some position of the body of the production • So, production A X Y Z yields four items A . X Y Z A X .Y Z A X Y . Z A X Y Z . -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Items and LR(0) Automaton • An item indicates how much of a production we have seen at a given point in the parsing process • The item A . X Y Z indicates that we hope to see a string derivable from XYZ next on input • Item A X . Y Z indicates that we have just seen a string derivable from X and hope to see a string derivable from Y Z • Item A X Y Z . Indicates that we have seen the body X Y Z and that it may be time to reduce X Y Z to A • Canonical LR(0) collection provides basis for constructing a DFA used to make parsing decisions • Such an automaton is called an LR(0) automaton • Each state of the LR(0) automaton represents a set of items in the canonical LR(0) collection -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Items and LR(0) Automaton • To construct canonical LR(0) collection for a grammar • Define an augmented grammar • Two functions, CLOSURE and GOTO • If G is a grammar with start symbol S, then Ǵ the augmented grammar for G, is G with a new start symbol Ś and production Ś S • Purpose of this new production is to indicate to the parser when it should stop parsing and announce acceptance of the input • Acceptance occurs when and only when the parser is about to reduce by Ś S -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Items and LR(0) Automaton • Closure of Item Sets • If I is a set of items for a grammar G, then CLOSURE(I) is the set of items constructed from I by the two rules • Initially, add every item in I to CLOSURE(I) • If A α . B β is in the CLOSURE(I) and B γis a production, then add the item B . γ to CLOSURE(I), if it is not already there Apply this rule until no more ne w items can be added to CLOSURE(I) • The set of items can be divided into two classes • Kernel items : the initial item , Ś . S, and all items whose dots are not at the left end • Nonkernel items : all items with their dots at the left end, except for Ś . S -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Items and LR(0) Automaton • Consider the augmented expression grammar É E E E + T | T T T * F | F F ( E ) | id I is the set of one item {[É . E]}, then CLOSURE(I) contains the set of items I0 É . E E . E + T E .T T . T * F T . F F . ( E ) F . id -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Items and LR(0) Automaton • The Function GOTO • GOTO(I,X) where I is a set of items and X is a grammar symbol • GOTO(I,X) is defined to be the closure of the set of all items [A α X .β] such that [A α . X β] is in I • The GOTO function is used to define the transitions in the LR(0) automaton for the grammar • States of the automaton correspond to sets of items and GOTO(I,X) species the transition from the state for I under input X • If I is the set of two items {[É E .] , [E E . + T]}, then GOTO(I,+) contains the items E E + . T T . T * F T . F F . ( E ) F . id -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Items and LR(0) Automaton -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
LR(0) Automaton for the Expression Grammar -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Use of the LR(0) Automaton • Central idea behind SLR parsing is the construction of the LR(0) automaton • The states of this automaton are the sets of items from the canonical LR(0) collection • Transitions are given by the GOTO function • Start state of the LR(0) automaton is CLOSURE({[S ́ . S]}), where S ́ is the start symbol of the augmented grammar • “state j” refers to the state corresponding to the set of items Ij • How LR(0) automata help with shift-reduce decisions? • Suppose that the string γ of grammar symbols takes the LR(0) automaton from start state 0 to some state j • Then, shift on next input symbol a if state j has a transition on a • Otherwise, chose to reduce; the items in state j will tell us which production to use -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Use of the LR(0) Automaton • Actions of a shift-reduce parser on input id*id, using the LR(0) automaton -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
The LR Parsing Algorithm • Consists of an input, output, a stack, driver program and a parsing table that has two parts (ACTION and GOTO) • Parsing program reads characters from an input buffer one at a time • A shift-reduce parser would shift a symbol, LR parser shifts a state • Each state summarizes the information contained in the stack below it -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
The LR Parsing Algorithm • Stack holds a sequence of states, s0s1s2… sm, where smis on top • In the SLR method, stack holds states from the LR(0) automaton • Each state has a corresponding grammar symbol • States correspond to set of items and there is a transition from state ito state j if GOTO(Ii , X) = Ij • All transitions to state j must be for the same grammar symbol X • Thus, each state, except the start state 0, has a unique grammar symbol associated with it -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
The LR Parsing Algorithm • Structure of the LR Parsing Table • Parsing table consists of two parts : parsing-action function ACTION and goto function GOTO • The ACTION takes as arguments a state iand a terminal a (or $). The value of ACTION[i,a] can have one of the four forms: • Shift j, where j is a state. The action taken by the parser shifts input a to the stack, but uses state j to represent a. • Reduce A β. The action of the parser reduces βon the top of the stack to the head A. • Accept. The parser accepts the input an finishes parsing • Error. The parser discovers an error in its input an takes some corrective action • Extend the GOTO function defined on set of items, to states : if GOTO[Ii , A] = Ij, then GOTO also maps a state i and a nonterminalA to state j. -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
The LR Parsing Algorithm • LR-Parser Configurations • Have a notation representing the complete state of the parser : its stack and the remaining input • A configuration of an LR Parser is a pair (s0s1s2… sm, aiai+1… an$) first component is stack contents and second is the remaining input • This configuration represents the right-sentential form X1X2… Xmaiai+1… an in a shift-reduce parser • Here, Xi is the grammar symbol represented by state si • State s0, the start state of the parser, does not represent a grammar symbol and serves as the bottom-of-stack marker -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
The LR Parsing Algorithm • Behavior of the LR Parser • The next move of the parser from the configuration is determined by reading ai, the current input symbol, and sm, the state at the top of the stack, and then consulting the entry ACTION[sm, ai] in the parsing action table • The configurations after each of the four types of move are as follows: • If ACTION[sm, ai] = shift s, parser executes a shift move; shifts next state s onto stack and enters the configuration : (s0s1s2… sms, ai+1… an$) • If ACTION[sm, ai] = reduce A β, parser executes a reduce move, entering the configuration : (s0s1s2… sm-r s, aiai+1… an$) where r is length of β, and s = GOTO[sm-r,A]. Here parser popped r state symbols off the stack, exposing state sm-r. Parser then pushed s, the entry for GOTO[sm-r,A], onto the stack • If ACTION[sm, ai] = accept, parsing is completed • If ACTION[sm, ai] = error, parser has discovered an error and calls an error recovery routine -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
The LR Parsing Algorithm • LR-parsing Program -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Constructing SLR-Parsing Tables -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers