PROYECTO GENOMA
INTRODUCCION A LA BIOTECNOLOGIA. PROYECTO GENOMA. Dra . Silvina M Alvarez 2013. Nuestro cuerpo está formado por aproximadamente 100.000 millones de células. Cada una de ellas tiene un set completo de instrucciones sobre como hacer las células y sus componentes .


PROYECTO GENOMA
E N D
Presentation Transcript
INTRODUCCION A LA BIOTECNOLOGIA PROYECTO GENOMA Dra. Silvina M Alvarez 2013
Nuestro cuerpo está formado por aproximadamente 100.000 millones de células Cada una de ellas tiene un set completo de instrucciones sobre como hacer las células y sus componentes Este set de instrucciones es el GENOMA
Tu genoma es muy similar al genoma de cualquier otra persona. Por ello es que todos somos seres humanos. Todos los organismos vivientes tienen genomas Por ejemplo, los mosquitos tienen un genoma de mosquito, que es un set completo de instrucciones para hacer un mosquito La remolacha tiene un genoma de remolacha y la bacteria tiene un genoma de bacteria
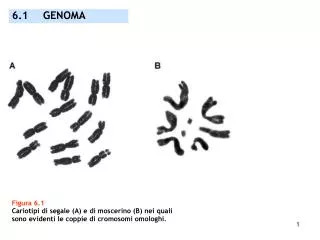
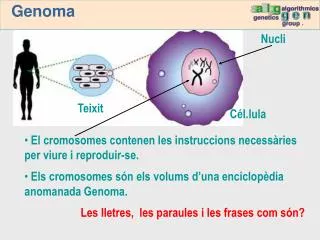
Un genoma es una colección completa de ácido desoxirribonucleico (ADN) de un organismo, o sea el compuesto químico que contiene las instrucciones genéticas necesarias para desarrollar y dirigir las actividades de ese organismo. El genoma humano contiene aproximadamente 3.000 millones de pares de bases, los cuales se encuentran en los 23 pares de cromosomas dentro del núcleo de todas nuestras células. Cada cromosoma contiene cientos de miles de genes, que tienen las instrucciones para hacer proteínas. Cada uno de los 30.000 genes estimados en el genoma humano produce un promedio de tres proteínas.
La estructura del ADN fuedilucidada en 1953, por Watson, Crick y Franklin. Las moléculas del ADN están conformadas por dos hélices torcidas y antiparalelas. Cada hélice está formada por cuatro unidades químicas, denominadas bases nucleotídicas: adenina (A), timina (T), guanina (G) y citosina (C). Las bases en las hélices opuestas se aparean específicamente: una A siempre se aparea con una T, y una C siempre con una G, haciéndolas complementarias. Hasta 1970, el ADN era la molécula mas difícil de analizar para los bioquímicos Hacia mediados de la década de los 80 la metodología del ADN recombinante y sus técnicas asociadas (vectores de clonación, enzimas de restricción, transformación artificial de células, bibliotecas de genes, sondas moleculares, secuenciación, genética inversa, PCR) habían alcanzado una madurez suficiente como para que se planteara la posibilidad de un proyecto de caracterización detallada (hasta nivel de secuencia de nucleótidos) del genoma humano y de genomas de organismos modelos. Ahora es la molécula mas fácil de analizar = se puede aislar una región específica del genoma, producir un número teóricamente ilimitado de copias y determinar su secuencia nucleotídica de un día para el otro.
El Proyecto Genoma Humano (PGH) fue el primer gran esfuerzo coordinado internacionalmente en la historia de la Biología. Origen del ProyectoGenoma Antes de los años 80 ya se había realizado la secuenciación de genes sueltos de muchos organismos, así como de "genomas" de algunos virus y plásmidos. Algunos grupos de investigación tenían la idea de comprender los genomas de algunos microorganismos. Pero la concreción institucional del PGH comenzó en los EEUU en 1986 cuando el Ministerio de Energía (DOE) planteó dedicar una partida presupuestaria a secuenciar el genoma humano, como medio para afrontar la evaluación del efecto de las radiaciones sobre el material hereditario. El año siguiente, tras un congreso de biólogos, se unió a la idea el Instituto Nacional de la Salud (NIH) de Estados Unidos, otro organismo público con más experiencia en biología (pero no tanta como el DOE en la coordinación de grandes proyectos de investigación). En 1988 se publicaron informes de la Oficina de Evaluación Tecnológica del Congreso (OTA) y del Consejo Nacional de Investigación (NRC), que supusieron espaldarazos esenciales para dar luz verde a la Iniciativa. Ese mismo año se formó la Organización del Genoma Humano (HUGO), como entidad destinada a la coordinación internacional, a evitar duplicaciones de esfuerzos, y a diseminar el conocimiento. El comienzo oficial del PGH fue en 1990.
Celera Genomics • Fundada en 1998 por Craig Venter – Su objetivo: secuenciar el genoma en 9 meses y venderlo. Sin hacerlo de libreacceso al público. • Desarrollómétodosmáseficientes – El secuenciamiento “disparo de escopeta”(Shotgun) del genomacompleto (luegoadoptadopor HGP) • Muchacontroversia y malospresentimientos – Celera basósutrabajo en los datospublicadospor HGP • Eventualmente se llegó a un compromiso – Finalmente ambos, Celera y HGP decidieroncolaborar en el mismoproyecto y publicaronsushallazgos en FEB 2001 El genomahumanofueterminado en 2003 (dos años antes de lo previsto)
OBJETIVOS DEL PROYECTO GENOMA HUMANO • Obtener el mapafísico del genoma – Permitir la localización de fragmentos genéticos • Desarrollartecnologías de secuenciamiento máseficientes y rápidas – Para aumentar el rendimiento y disminuir el costo • Obtener la secuencia del ADN humano – Hacerlo con granprecisión y de libreacceso • Analizar la variación de la secuencia humana – Identificar SNPs (polimorfismos de un solo nucleótido) y desarrollarunateoría al respecto
OBJETIVOS DEL PROYECTO GENOMA HUMANO • Crear herramientas de bioinformática – Desarrollar bases de datos y análisis de algoritmos. Desarrollarherramientaspara el análisis de los datos • Identificar genes y regiones codificantes – Desarrollar métodos eficientes in-vitro o in-silico • Secuenciar otros organismos modelos – Bacterias, levaduras, mosca de la fruta, gusanos, ratón • Responder los problemas éticos, legales y sociales – Desarrollar políticas/leyes al respecto
SECUENCIAMIENTO • Habíaunagrancantidad de ADN humanoparasecuenciar(3000 Mb, or 3 x 109pb). • Debido a laslimitaciones de lastécnicasdisponibles, cadareacción de secuenciamiento solo podíagenerarhasta700 pb de secuencia de ADN. • Por lo que la secuencia total debía ser ensamblada a partir de millones de trozospequeños de secuenciasque se superponían entre sí. El puntoinicial de estetrabajofue el uso de clones BAC superponibles (BAC= siglas del inglésparacromosomasartificiales de bacterias). • Cadaclonessubclonado en cientos de fragmentos menores, usando un plásmido vector adecuadoparapreparartempladosparalasreacciones de secuenciamiento de ADN.
SECUENCIAMIENTO CON CLONES BAC Cromosomafragmentado en trozos de 150pb Inserción de fragmentos dentro de cromosomasbacterianosparaformar los BAC Hacer copias múltiples ADN de BAC purificado Biblioteca BAC Fragmentar el ADN físicamente Leer al azar Ensamblar la secuencia Terminación del secuenciamiento Secuencia pre terminada Ensamblado final Secuencia terminada
SECUENCIAMIENTO CON CLONES BAC vs “DISPARO DE ESCOPETA” Generar fragmentos de lectura de todo el genoma con “disparo de escopeta” Generar BAC con los fragmentos de “disparo de escopeta” Combinar los fragmentos superponibles de los fragmentos derivados de BAC y del genomacompleto Luegoque HGP y Celera se asociaron, ambastécnicasfueronutilizadas en conjunto, acelerando el proceso Ensamblado y finalización
CARTOGRAFIAS GENOMICAS El PGH hace uso de dos tipos de cartografía para caracterizar el genoma: cartografía genética de ligamiento, y cartografía física. Cartografía genética de ligamiento La cartografía genética se basa en el cálculo de la frecuencia a la que se co-heredan formas alternativas (alelos) de dos loci genéticos que están ligados formando parte de un mismo cromosoma. Antiguamente, sin técnicas moleculares, se hacía basándose en la comparación de fenotipos normales y los mutantes correspondientes a determinadas enfermedades genéticas, y en el recurso a análisis de familias. La revolución de la cartografía genética de ligamiento fue a fines de los 70, cuando se recurre al análisis molecular de zonas de ADN no codificadoras y que son muy polimórficas: existen varios tipos de secuencias (algunas repetitivas, como los VNTR, los microsatélites, etc.), dispersos por el genoma, cada uno de ellos con varios alelos en el ámbito poblacional. Entre las ventajas de los microsatélites se cuentan: contenido informativo muy alto, con lo que los análisis estadísticos mejoran en fiabilidad; distribución abundante y relativamente uniforme por todo el genoma; y que se pueden ensayar fácilmente mediante PCR. Además sirven en genética clínica como marcadores útiles para localizar genes relacionados con enfermedades. Los polimorfismos moleculares permitieron que el PGH haya generado detallados mapas genéticos del genoma humano a un nivel de resolución en torno a 1 centimorgan (cM) o incluso menos. Esto ya se logró en 1994, un año antes de lo previsto, y en buena parte con resoluciones mejores (0.7 cM).
Cartografía física Los mapas físicos tienen como objetivo especificar distancias físicas medible en pares de bases (pb) o alguno de sus múltiplos. El mapa físico de mayor detalle es la propia secuencia del genoma. Los mapas físicos de menor resolución son los propios cariotipos: la visualización microscópica de la dotación cromosómica haploide humana teñida con colorante de Giemsa nos muestra un patrón alternante de bandas claras y oscuras, en el que cada banda tiene una media de unos 7 millones de pares de bases.
Cartografía física Los mapas físicos de mayor resolución se suelen elaborar a partir de genotecas (bibliotecas de genes). Ordenar los fragmentos del genoma buscando fragmentos que tienen alguna zona en común, es decir parcialmente solapados. Ello conduce al concepto de contig: un contig (o cóntigo) es un conjunto de fragmentos de un genoma que se han clonado por separado, pero que son contiguos y que están parcialmente solapados. Todo el procedimiento está altamente automatizado, como en el famoso laboratorio francés Génethon, provisto de varios robots especializados en procesar y analizar las muestras. El último gran hito en cuanto a metodología de mapas físicos ha sido el desarrollo de una especie de "marcadores físicos universales", los "lugares etiquetados por su secuencia" (STS en inglés). Consisten en trechos cortos de ADN (de entre 100 y 1000 pb) cuya secuencia exacta se conoce y se sabe que es única en todo el genoma. Una vez que un investigador descubre una STS, cualquier otro puede obtenerla por sí, simplemente fabricando in vitro los cebadores correspondientes a sus extremos y amplificando la STS por reacción en cadena de la polimerasa (PCR). Los STS definen puntos concretos únicos, y constituyen balizas fácilmente detectables. Estos mapas de STS permiten la integración de los mapas genéticos y físicos.
Mapas genéticos:estos mapas simplemente indican la posición relativa de los diferentes genes. Para esta confección se estudió principalmente la transmisión de caracteres hereditarios, capaces de ser seguidos de una generación a otra en grandes familias. Por ejemplo, en Estados Unidos se han localizado muchos genes gracias a estudios realizados en comunidades mormonas, cuya endogamia es notoria.
Mapas físicos: de mayor resolución, pues muestra la secuencia de nucleótidos en la molécula de ADN que constituye el cromosoma. Se obtiene la secuencia de nucleótidos de un gen. Originalmente se realizaba fundamentalmente mediante la electroforesis en geles de distintos fragmentos de ADN y la ayuda de computadoras. Posteriormente, con secuenciadores automáticos. Secuenciación de ADN por ordenador con letras y colores.
IMPACTO DEL PGH t Importantes avances en Medicina. Aunque el estudio de las enfermedades en humanos se hacían en ausencia de su comprensión genética, la disponibilidad de técnicas llevo a la secuenciación sistemática, lo que dióun formidable impulso sobre todo para las enfermedades poligénicas y multifactoriales. t Ahora se dispone de sondas y marcadores moleculares para el diagnóstico de enfermedades genéticas, de cáncer y de enfermedades infecciosas. t Por su parte, la secuenciación de genomas de plantas y animales domésticos conducirá a nuevos avances en la mejora agronómica y ganadera. t La bionformática permite comparar genes y genomas completos, lo que junto con otros datos biológicos y paleontológicos, está dando nuevas claves de la evolución de la vida. • Para hacerse una idea de las ventajas del PGH con relación a otros ámbitos tradicionales de investigación médica, se pueden dar algunas cifras: • El aislamiento por clonación posicional del gen de la fibrosis quística costó $ 30 millones. Se calcula que, de haber tenido un buen mapa como los actuales, hubiera costado solamente $ 200.000.
IMPACTO DEL PGH t Se espera que a su vez la investigación genómica permita diseñar nuevas generaciones de fármacos, que sean más específicos y que tiendan a tratar las causas y no sólo los síntomas. t La terapia genética puede aportar soluciones a enfermedades, no sólo hereditarias, sino cáncer y enfermedades infecciosas.
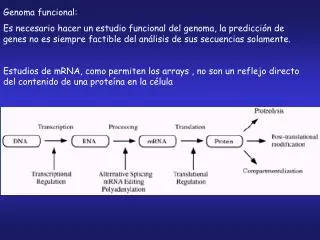
El papel de la informática en los proyectos genoma La informática ha sido uno de los objetivos esenciales del PGH, debido a la gran cantidad de datos que hubo que recoger, analizar, comparar, interpretar y distribuir. La informática aplicada a la biología presenta dos subdisciplinas: la bioinformática en sentido estricto, que se puede definir como el trabajo de investigación y desarrollo que se necesita como infraestructura de información de la actual biología; y la biología computacional, que es la investigación dependiente de la computación dedicada a entender cuestiones biológicas básicas. La bioinformática es un nuevo campo interdisciplinario, en la interfase entre ciencias de la computación, matemáticas y biología. Las cuestiones de gestión de datos que planteó el PGH supuso una revolución para la informática. Aunque para algunas de las tareas se pudo recurrir a enfoques tradicionales, con sólo aumentar la escala del procesamiento, para otros problemas se necesitan arquitecturas y programas informáticos totalmente diferentes.
Bases de datos genéticos y moleculares La difusión de los datos generados en los proyectos genoma se hace por medios electrónicos, depositándolos en bases de datos públicos. El ritmo de acumulación de datos es vertiginoso, y actualmente se duplican en menos de un año. El Consorcio Internacional de Bases de Datos de Secuencias está formado por GenBank, el Banco de datos de ADN de Japón (DDBJ) y el del EMBL. Albergan los datos de secuencias. Las tres bases comparten y complementan la información. En España existe un nodo de EMBL residente en el Centro Nacional de Biotecnología (CNB) de Madrid. La Genome Data Base (GDB) se estableció para albergar los datos de mapas y relacionados (sondas, marcadores, etc.) en Francia. Actualmente la base de datos bibliográfica MEDLINE (mantenida por la NML estadounidense) está vinculada con las bases de datos genéticos y de secuencias. Por ejemplo, se puede hacer una búsqueda desde MEDLINE con palabras clave de una enfermedad, lo que da acceso a OMIM (Herencia mendeliana on-line), con referencias bibliográficas, y de ahí se puede saltar a los mapas genéticos, físicos y las secuencias, si están disponibles.
Adquisición informatizada de datos biológicos La adquisición de datos experimentales por métodos digitales está apurando a la industria a diseñar y fabricar aparatos cada vez más sofisticados, que mejoran y aceleran la parte más rutinaria de la investigación. Para ello los aparatos incorporan sistemas computarizados de análisis y tratamiento de imagen visible. Por ejemplo los secuenciadores automáticos de ADN o en la tecnología del chip de ADN.
Adquisición informatizada de datos biológicos El ensamblaje automático de mapas y secuencias es otra tarea que plantea problemas a las ciencias de la computación, que han de hacer uso de nuevos algoritmos y estrategias en las que tener en cuenta los posibles errores. Predicción de secuencias codificadoras, dominios funcionales y otras zonas interesantes del genoma: aunque disponemos de programas a tal efecto (GRAIL, FASTA, etc.), se requieren nuevos algoritmos capaces de predecir patrones especiales de secuencia dentro de genomas completos. Se están ensayando aproximaciones derivadas de las redes neurales (neuromiméticas). Construcción de árboles filogenéticos: en principio se vienen realizando a base de comparar determinados genes entre pares de organismos, mediante algoritmos de alineamiento de secuencia, pero habrá que mejorar los métodos, incluyendo una adecuada evaluación del grado de fiabilidad de los árboles.
¿Por qué se apartó una porción del presupuesto de PGH para consideraciones éticas? Desde el comienzo del Proyecto Genoma Humano, ha estado claro que la expansión del conocimiento científico sobre el genoma tendría un profundo impacto en la humanidad. El cinco por ciento del presupuesto anual se dedicó al análisis de las implicancias éticas, legales y sociales (ELSI, por sus siglas en inglés) relacionadas con la investigación del genoma humano, incorporando recomendaciones específicas a las actividades del HGP y proporcionando orientación a quienes establecen las políticas y al público. El programa ELSI no tiene precedentes en las ciencias biomédicas en términos de alcance y nivel de prioridad. Un ejemplo es la decisión de secuenciar el ADN de varios individuos anónimos en lugar de hacerlo de un individuo conocido, a fin de proteger la privacidad. Otro ejemplo es el desarrollo de pautas de privacidad genética y borradores de legislación que son ampliamente utilizados. El programa ELSI se utiliza ahora como modelo para los grandes esfuerzos científicos financiados con fondos públicos.
GENOMAS MODELOS En paralelo al estudio del genoma humano se caracterizaron y secuenciaron genomas de organismos modelo, cuya comparación entre sí y con el acervo genético humano tuvieron dos notables efectos: - Aceleraron notablemente la obtención de importantes datos sobre la organización, función y evolución del ADN a lo largo de toda la escala filogenética. La comparación de genomas completos de los tres grandes dominios de la vida (arqueas, bacterias y eucariotas) suministróclaves para comprender más de 3000 millones de años de evolución. - Ayudaron a determinar la función de numerosos genes (incluyendo humanos). - Sirven para emprender nuevos enfoques dentro de la Biotecnología y la Biología industrial. Originalmente se secuenciaron por completo al menos un representante de cada uno de los tres grandes dominios de seres vivos. Ahora hay muchísimos m[as.
Eubacterias. Las siguientes eubacterias están totalmente secuenciadas:
Arqueas (arqueobacterias): Los genomas concluidos son los de Methanococcusjannaschiii y Archaeoglobusfulgidus, ambos obtenidos por el TIGR, y el de M. thermoautotrophicum. Muy avanzados están los de dos arqueobacteriashipertermofílicas (Pyrobaculumaerophilum, Pyrococcusfuriosus). El TIGR de Craig Venter está secuenciando decenas de microorganismos tanto procariotas como eucariotas, muchos de ellos con importancia clínica o industrial (entre las eubacterias: Enterococcusfeacalis, Legionellapneumophila, Mycobacterium tuberculosis, Neisseriameningitidis, Salmonella typhimurium, Vibriocholerae, Deinococcusradiodurans, etc.). El creciente número de secuencias bacterianas facilitará muchos estudios básicos, y por lo que respecta a las patógenas, permitirá aclarar sus mecanismos de patogenicidad y virulencia, lo que podrá sugerir a su vez nuevos tratamientos.
Eucariotas En 1996 se terminó la secuencia de la levadura de panadería (Saccharomycescerevisiae), y posteriormente el de otra levadura muy diferente (Schyzosaccharomycespombe). El proyecto genoma de levadura, que ha costado unos 30 millones de dólares, ha sido un logro esencialmente europeo, con André Goffeau (Universidad Católica de Lovaina) como coordinador. Se evitó a toda costa la duplicación de esfuerzo, "repartiéndose" los cromosomas o regiones entre países y laboratorios. La Unión Europea secuenció el 55%, el Centro Sanger (UK), 17%, la Universidad Washington en St. Louis, 15%, Universidad de Stanford, 7%, Universidad McGill (Canadá), el 4%, y un laboratorio japonés (RIKEN), el 2%. El genoma del nematodo Caenorhabditiselegans se terminó de secuenciar en 1998, con una intervención esencial del Centro Sanger. El de la mosca del vinagre (Drosophilamelanogaster) también fue terminado. Ya ha sido finalizada la cartografía y secuenciación del genoma del ratón. Dentro de la biología Vegetal se descifraron los genomas de especies modelo tanto monocotiledóneas (arroz, maíz) como dicotiledóneas (de estas últimas, se termino Arabidopsisthaliana).
Finalmente el mapa genético de la uva ha sido dilucidado y se han identificados los marcadores genéticos que guardan relación con la calidad, la producción o los factores medioambientales, información de gran valor para poder desarrollar nuevas variedades con mayores propiedades organolépticas, nutricionales, productivas o más resistentes al cambio climático. Esto fue hecho por varios países, entre los que se encuentran España, Canadá y Chile. Un grupo internacional de científicos de 14 países, que incluye a investigadores del INTA Balcarce, analizó y ordenó la secuencia del genoma de la papa, descifrado en 2009. Tiene 39.031 genes. Pequeñas variaciones en la secuencia de estos genes determina que las variedades de papa sean diferentes; esos cambios conforman la diversidad genética.
Entidades y Centros públicos o semipúblicos que participan activamente en Investigación genómica ProyectosNacionales en EEUU: Institutos Nacionales de la Salud (NIH), de los que dependen varios centros, entre ellos el Centro Nacional de Recursos del Genoma Humano (NCHGR), el Centro Nacional de Información Biotecnológica (NCBI)- Ministerio de Energía (DOE), a través, de los Laboratorios Nacionales de Lawrence Livermore, Lawrence Berkeley y Los Alamos. Centro Mixto para la Investigación Genómica, formado por el MIT (Instituto Tecnológico de Massachussetts) e Instituto Whitehead. Instituto Tecnológico de California (CalTech). Universidad de Stanford. Universidad Washington en Saint Louis, con financiación de NIH y de la empresa Merck. OtrasUniversidades.
Francia Francia fue pionera en la elaboración de los primeros mapas genéticos de buena resolución, y ello se debió al esfuerzo de una entidad privada, el Centro de Estudios del Polimorfismo Humano (CEPH) financiada en buena parte por una asociación de apoyo a enfermedades genéticas (la AFM, Asociación Francesa contra las Miopatías). De ahí surgió el Généthon, un laboratorio altamente automatizado que demostró que era viable un enfoque centralizado para elaborar cartografías genéticas y físicas. El CEPH (una vez cumplido su papel pionero en investigación básica) se va a dedicar a aprovechar los mapas para identificar genes de susceptibilidad a enfermedades. Últimamente el Estado está financiando estudios genómicos, y Francia está buscando la manera de hacer frente a la fuerte competencia de la alianza EEUU-Reino Unido (dudas sobre si colaborar o hacer un proyecto propio).
Reino Unido: El papel más destacado corresponde al Centro Sanger, cerca de Cambridge, fundado conjuntamente por el Welcome Trust y el Consejo Británico de Investigación Médica (BMRC). Secuenció un tercio de la secuencia del genoma humano. Se ha centrado en los mapas detallados y secuencias de los cromosomas 1, 6, 20, 22 y X. Es el centro de referencia para el estudio del genoma del nematodo C. elegans. En ese mismo campus tecnológico se asienta otro importante centro genómico británico, el Centro de Recursos del Proyecto Cartográfico del Genoma Humano (HGMP-RC).
Alemania: Alemania ha tardado en apuntarse a la oleada genómica (en buena parte debido a las peculiares reticencias sociales derivadas de los traumas del nazismo). Pero en 1995 el Gobierno por fin decidió una financiación continuada de $ 72 millones al año durante 8 años, con prioridad hacia el estudio de enfermedades genéticas y diseño de terapias. Uno de los centros implicados es el Instituto Max Plank de Genética Molecular (Berlín). Japón Japón tardó en incorporarse plenamente a la investigación genómica. Un centro privado (Instituto Kasuza, cerca de Tokyo) logró una de las primeras secuencias bacterianas, y actualmente estudia genomas de plantas. Dos ministerios (el de Industria y el de Salud) han montado dos empresas (Helix y Pharma-Genocyte) que colaborarán con la industria privada para aprovechar la información genética y transformarla en aplicaciones comerciales.
Iniciativas internacionales HUGO (Organización del Genoma Humano): asociación internacional de científicos implicados en el PGH, creada en 1989 para promover la cooperación. Esencialmente su papel es coordinar los esfuerzos nacionales (evitando la dispersión y duplicación inútil de esfuerzos), difundir datos, promover seminarios y congresos, difundir los temas ELSI, y suministrar consejo e información sobre el genoma humano. Las funciones de coordinación de HUGO no sólo se refieren al campo de la colaboración internacional, sino que también coordina los trabajos de genomas según especies y siguiendo un enfoque interdisciplinar. Organización Europea de Biología Molecular (EMBO): posee uno de los mejores laboratorios mundiales de Biología Molecular (EMBL, en Heidelberg), y está cumpliendo una importante función en la coordinación científica europea. En Cambridge (y muy cerca del centro Sanger) mantiene el Instituto Europeo de Bioinformática (EBI).
Investigación genómica privada e intereses comerciales Durante mucho tiempo las empresas no parecieron mostrar interés por la genómica, hasta que en 1991 Craig Venter (entonces perteneciente al NIH) presentó un método para aislar secuencias génicas, y empezó a pedir las polémicas patentes sobre fragmentos de ADNc. Ahora el panorama ha cambiado radicalmente. La genómica industrial ha obligado a muchas empresas biotecnológicas de primera generación a transformarse o morir, y ha animado a las multinacionales a apostar fuerte. Muchos científicos han pasado de la Universidad a la Industria, o al menos tienen fuertes relaciones con las empresas. La inversión privada ha sido tan fuerte, que la investigación académica no puede competir en este campo aplicado. Actualmente se dice que las instituciones académicas no deben perder el tiempo intentando buscar genes de enfermedades comunes, a no ser que tengan vínculos con la industria, so pena de quedar obsoletos muy pronto. Los académicos deben, en cambio, ir a la caza de enfermedades raras o del tercer mundo que no interesen a las empresas. Es decir, no a la competencia con la industria, pero sí a la especialización en busca de un adecuado "nicho ecológico".
Empresas genómicas de nuevo cuño Las empresas genómicas se pueden clasificar en tres tipos: las que se dedican sobre todo a cartografía y secuenciación, las que hacen clonación posicional, y las que hacen genómica funcional, aprovechando los datos genómicos (a menudo comprados a las primeras) para buscar nuevos medicamentos. Empresas genómicas de secuenciación y gestión de datos: TheInstitute of GenomeResearch (TIGR): está casi monopolizando la secuenciación de genomas microbianos. Secuencian unos 10 genomas por año. Hasta hace poco funcionaba por acuerdos con HGS, pero la alianza se ha roto por desavenencias sobre el control de datos. HumanGenomeSciences (HGS): entre sus directivos se encuentra W. Haseltine (antiguo investigador sobre el sida en la Universidad de Harvard). En 1996 anunciaron que habían secuenciado el genoma de Staphylococcusaureus (aunque no hicieron pública la secuencia). Colabora con empresas para obtener vacunas y medicamentos contra las bacterias que están secuenciando. Hizo acuerdos con el gigante agrícola PionerHiBredpara estudiar el genoma del maíz. Acuerdo por valor de 100 millones de dólares con el gigante farmacéutico SmithKlineBeechampara suministrarle información sobre genes expresados en tejidos y órganos humanos. Incyte: vende acceso no exclusivo a bases de datos relacionados de ESTs (LifeSeq). GenomeTherapeutics: ha lanzado una base de datos microbiana (PathoGenome), la mayor fuente de información de más de una docena de patógenos. Ha llegado a un acuerdo con Bayer. También ha llegado a acuerdos con Astra (Suecia) para terapias y vacunas contra Helicobacter pylori, y con Schering-Plough, para lo mismo respecto de Staphylococcusaureus. Microcide: con un enfoque similar al anterior.
Empresas dedicadas preferentemente a la clonación posicional: Buscan genes de interés haciendo clonación posicional (para lo que deben estudiar marcadores en familias con miembros afectados de alguna enfermedad). Sus campos de aplicación pueden ser de dos tipos: desarrollar sondas genéticas y otras herramientas diagnósticas, y recorrer el a veces largo camino que va de los genes a desarrollar nuevos medicamentos. SequanaTherapeutics: dispone de 30.000 muestras de ADN de pacientes, familias y poblaciones, que le sirven para buscar genes de varias enfermedades. Ha adquirido recientemente la firma NemaPharm, dedicada a desarrollar nuevos medicamentos a partir de la información genómica del nematodo C. elegans. Su especialidad es usar organismos modelo para ensayar nuevas terapias. Alianza con Boehringer para desarrollar terapias contra el asma (basándose en los datos de una población de la isla de Tristan da Cunha). Acuerdo con ZymoGeneticspara encontrar moléculas de señales endocrinas y paracrinas. Millennium Pharmaceuticals: desarrolla diagnósticos y medicamentos. Investiga en diabetes, aterosclerosis, asma y obesidad. Como muchas empresas de este tipo, tiene disputas sobre patentes. MyriadGenetics: se ha hecho famosa (y polémica) por comercializar un test genético de susceptibilidad al cáncer hereditario de mama y ovario dependiente de los genes BRCA1 y BRCA2. Darwin Molecular: Al estar en Seattle, Bill Gates (Microsoft) le dio un buen empujón financiero. Usa no sólo genómica, sino química combinatoria para desarrollar nuevos remedios. Genset (Francia): su énfasis está en desarrollar nuevos medicamentos de pequeño tamaño para enfermedades variadas, incluido el cáncer. Se ha convertido en un gigante capaz de competir con las empresas americanas. Empresas de genómicafuncional Combion, Synteni y Affimetrix están desarrollando tecnologías de hibridación con chips de ADN, que pueden analizar la expresión de cientos de genes al mismo tiempo. Affimetrixposee la prometedoratecnologíaGenChip. NemaPharm, dedicada a usar el nemátodoC. elegans para rastrear moléculas potencialmente terapéuticas en humanos. Actualmenteesuna filial de Sequana. Hexagen (Reino Unido) usa ratones como herramientas para rastrear posibles medicamentos.
Papel de lasmultinacionales Las multinacionales han empleado mil millones de dólares en acuerdos con las empresas genómicas, un presupuesto que ya supera al estatal del PGH americano. Piensan que la ciencia genómica puede acelerar el proceso de descubrimiento, desarrollo y comercialización de nuevos medicamentos. Merck: Su programa genómico está dirigido por Thomas Caskey (otro de los pioneros procedentes de la Universidad). La empresa dispone del Instituto Merck de Investigación Genómica. Ha llegado a acuerdos con Lexicon para análisis a gran escala de función génica. Suministra apoyo financiero a la Universidad Washington en St. Louis para una colección de clones de ADNc. Dispone de más de 250.000 secuencias de ESTs, que representan la mayoría de los genes humanos. Los datos se integran en el Consorcio IMAGE. Su política es distribuir la información de modo inmediato a las bases públicas de datos. Pharmacia & Upjohn: posee un acuerdo con Incyte, que le permite acceder a sus mapas y bases de datos. SmithKlineBeechambasa actualmente el 25% de su I+D en programas genómicos, y en el años 2000 toda su investigación dependerá del genoma. Hoffman-LaRoche: acuerdo con HGS para desarrollar terapias contra Streptococcuspneumoniae. Schering-Plough: acuerdo con GenomeTherapeuthics para medicamentos. Han comenzado su propia investigación genómica. GlaxoWellcome Rhône-Poulenc Rorer
CLONACION ¿Qué es clonar? La clonación puede definirse como el proceso por el que se consiguen copias idénticas de un organismo ya desarrollado, de forma asexual. Estas dos características son importantes: § Se parte de un animal ya desarrollado, porque la clonación responde a un interés por obtener copias de un determinado animal que nos interesa, y sólo cuando es adulto conocemos sus características. § Por otro lado, se trata de hacerlo de forma asexual. La reproducción sexual no nos permite obtener copias idénticas, ya que este tipo de reproducción por su misma naturaleza genera diversidad. ¿Por qué es posible la clonación? La posibilidad de clonar se planteó con el descubrimiento del ADN y el conocimiento de cómo se transmite y expresa la información genética en los seres vivos. Para entender mejor esto hace falta recordar brevemente cómo “está hecho” un ser vivo. Un determinado animal está compuesto por millones de células, que vienen a ser como los ladrillos que forman el edificio que es el ser vivo. Esas células tienen aspectos y funciones muy diferentes. Sin embargo todas ellas tienen algo en común: en sus núcleos presentan el ADN. Cada célula contiene toda la información sobre cómo es y cómo se desarrolla todo el organismo del que forma parte .
Todas las células de un individuo derivan de una célula inicial, el embrión unicelular o zigoto. Esta célula, que es ya una nueva vida, se obtiene de forma natural por la fusión de las células reproductoras, óvulo y espermatozoide, cada una de las cuales aporta la mitad del material genético. En el zigoto tenemos ya la información de cómo va a ser el nuevo organismo: su sexo, sus características físicas, todo. A partir de ese momento esa información se irá convirtiendo rápidamente en realidad por dos procesos: la división celular y la especialización de las células.
§ El zigoto empieza a dividirse. En cada división se hace una copia del ADN, para que cada célula tenga la información de cómo es todo el individuo. Millones de divisiones después, se tiene un organismo desarrollado, con millones de células que tienen toda la información, la misma contenida en el zigoto. § Al aumentar el número de células, estas van especializándose y adquiriendo diferentes funciones. Las células del embrión no tienen características concretas, están poco especializadas, y tienen mucha potencialidad: son capaces de transformarse en cualquier tipo celular, o incluso de dar lugar a un nuevo organismo. En el organismo adulto, las células ya tienen funciones bien definidas y pierden potencialidad. Esta especialización o diferenciación celular viene determinada por el uso del ADN: cada célula utiliza sólo la parte del ADN que corresponde a su función. De modo que, aunque cada célula tenga toda la información, no la utiliza toda, sino sólo la parte que le corresponde.
Cualquier célula del organismo adulto (células somáticas, no reproductoras) puede servir teóricamente para obtener un nuevo ser vivo de las mismas características, ya que tiene en su ADN la información de cómo es y como se desarrolla ese determinado organismo. Se trataría de tomar una célula cualquiera, exceptuando las células reproductoras que tienen una dotación incompleta, y conseguir que esa información se exprese, se ponga en funcionamiento y nos produzca otro ser. Clonar consistiría por tanto en reprogramar una célula somática para que empiece el programa embrionario. Una vez comenzado su desarrollo se implantaría en un útero, donde es posible que los embriones lleguen a término. Además, disponemos de tecnología adecuada, tanto para conseguir que las células vivan y crezcan fuera del cuerpo, mediante las llamadas técnicas de cultivo celular, como para implantar con éxito embriones generados in vitro, por las técnicas de manipulación de embriones.