
Artifact and Structured Data Management
This document outlines a sophisticated pipeline for the collection, transformation, and management of functional data, specifically focused on EEG and ERP processing. It details artifact generation, file handling (including CSV and XLS formats), and the use of auto-labeling techniques. Additionally, the framework incorporates a middleware layer for information consumers, facilitating data upload and browser functionalities, leveraging technologies like SPARQL, Sesame, and Pellet for scalable reasoning. The system ensures effective archival and provenance tracking for enhanced data usability and analysis.
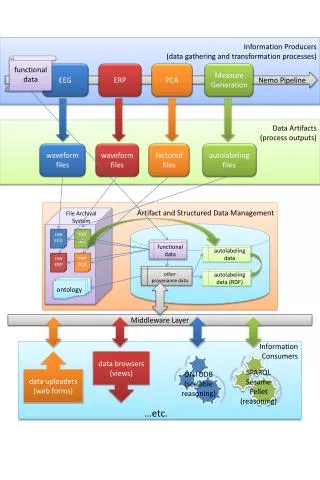

Artifact and Structured Data Management
E N D
Presentation Transcript
Information Producers (data gathering and transformation processes) functional data EEG ERP PCA Measure Generation Nemo Pipeline Data Artifacts (process outputs) waveform files waveform files factored files autolabeling files Artifact and Structured Data Management File Archival System raw EEG csv xls functional data autolabeling data raw ERP raw PCA other provenance data autolabeling data (RDF) ontology Middleware Layer Information Consumers data uploaders (web forms) data browsers (views) SPARQL Sesame Pellet (reasoning) ONTODB (scalable reasoning) …etc.


















