Download

1 / 16
160 likes | 322 Vues
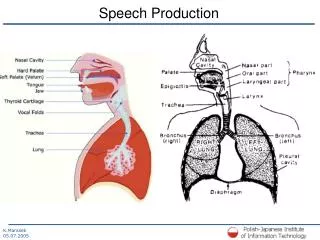
Fundamentals of speech production and analysis. Speech production and analysis: Web tutorium. Speech production Basic speech units: phoneme, syllable, word, phrase, sentence, speaking turn phone: subphonetic units, diphone, triphone, syllable as recognition units types of sounds:

E N D
Speech production and analysis: Web tutorium • Speech production • Basic speech units: phoneme, syllable, word, phrase, sentence, speaking turn • phone: subphonetic units, diphone, triphone, syllable as recognition units • types of sounds: • manner and place (constriction of vocal tract) of articulation, • vowels and consonants: • sonorants (vowels, diphtongs, glides, liquides, nasals) • obstruents (stops, fricatives, affricates) • consonants classification depending on vocal tract configuration: • labials, dentals, alveolars, palatals, glottals and pharingeals • transient sounds (diphtongs, glides, stops and affricates) and continuant sounds • vowels: front, back, middle, low, high - vowels rectangle • IPA chart • coarticulation • prosodic features: sentence intonation and word stress • voice quality and paralinguistic features • time and frequency features: • formants and duration, wide- and narrow-band spectrograms
Principles of speech analysis • Speech detection: remove silence and noise • signal preprocessing and conditioning: • pre-emphasis to enhance speech signal at higher frequencies H(z)=1-az-1, a=0.95 • high-pass filtering • spectral analysis • short -time Fourier transform (STFT) • where w(n-m) is a window sequence for observation of n-th time instant • window is usually tapered to avoid effects of multiplication in time domain, so called convolution ex. Hamming window • frequency and time resolution trade-off (FFT principle) • vector of coefficients as an output, magnitude in log-scale considered only: power spectrum • side-effects: spectral leakage, picket-fence effect etc., biased estimator of PFD • do not fit to F0: fluctuations, pitch synchronous analysis • spectrograms reading: exercises
Other methods of speech analysis • Time-frequency distributions: • where f(q,t) is the kernel function defining smoothing properties of the TFDs: Wigner-Ville, Rihacek, and others • spectrogram is a special case of TFD • no trade-off between time and frequency resolution - limited only by Heisenberg’s uncertainty principle (sampling frequency), but interference between signal components • wavelet transform: future analysis tool? Non-uniform sampling of time-frequency plane • Filter bank analysis: • the most specific cues of the signal are located in specific frequency bands • FIR-filters better (linear phase), but can be very long, IIR shorter, usually filtering in frequency domain used, • powerful enough for small vocabulary application: ex. 7 bands for DTW 60 words recognizer Filter bank for telephony
Wigner-Ville distribution • /a/ vowel
Wigner-Ville distribution • /t/ stop • sig1=wavread('d:\pjwstk\charlotte\lectures\ata2.wav'); • plot(sig1); • tfrwv(sig1);
Linear Predictive Coding (LPC) • Wiener (1966), Markel and Gray (1976), Makhoul (1973) • ARMA model of a process: • where p and q are model orders of pole and zero filters, and a and b represent sets of coefficients • LPC=AR, in order to compute coefficients is necessary to define the prediction error, so called residual signal: • the coefficients of the filter can be than computed applying last-square criterion to minimize a total squared error • once the predictor coefficients have been estimated, the e(n) signal can be used for a perfect signal reconstruction
LPC • speech synthesis application: • critical: model order, quantization of parameters and excitation signal • computation of coefficients: many methods, usually autocorrelation or auto-covariance • features of LPC: • modeling of peaks of the spectrum: good for formant frequency and bandwidth estimation • smoothed spectrum - spectral envelope • acoustic model of a tube with p/2 cylindrical sections • model order: rule of thumb: sampling frequency in kHz + 2 • SVD for model order estimation • application in speech recognition: signal parametrization, but not commonly used • RASTA filtering for noisy signals • exercises: LPC analysis using Praat LPC Synthesis
LPC-based coeffcients • Usually not LPC coefficients are used, rather derivates • reflection coefficients: directly obtainable during LPC computations (Levinson-Durbin recursion) • E(I) is the total prediction error at the i-th recursion step and al(I) is the l-th coefficient. Let E(0)=R(0) where R(i) is i-th autocorrelation coeffcient, then recursively for i=1…p • where ki denote the reflection coefficient (PARCOR), k<1 • acoustic tube model: let Ai be the cross-section of i-th segment; then for neighboring sections holds: • line spectral frequencies: poles of AR filter:concentration of two or more LSFs in a narrow frequency interval indicates the presence of a resonance in the LPC spectrum • LPC cepstral coeffcients ( ), Mel-based possible, • perceptual LPC (PLP, Hermansky), using hearing properties, effective for noisy data
LPC • Vowel LPC spectrum for various model orders
Homomorphic cepstral analysis • Signal decomposition into components having different spectral charcteristics • the objective is to decompose given signal s(n) into source e(n) and vocal tract h(n) components: s(n)=e(n)*h(n) (*-convolution), what in frequency domain equals to • taking log one gets: • the frequency response of the vocal tract log(|H|) is a slowly varying component and represents the envelope of log(|S|), while log(|E|) is rapidly varied excitation component: • the components can be separated in the log spectral domain by computing IFFT and retaining lowest order coefficients to account for the vocal-tract transfer function • inverse Fourier transform of log(|S|) is called cepstrum (real cepstrum, exists also complex cepstrum) Block diagram of homomorphic analysis
Cepstral Analysis and Auditory Models • Cepstrally smoothed spectrum: examples • widely used in pattern-matching problems, because Euclidean distance between two cepstral vectors represents a good measure for comparing log-spectra • Auditory Models • separating the message from surounding noise • modeling of output from cochlea • bark or mel scale of frequency axis: linear to ca. 1000 Hz, logarithmic above • Acoustic features for SR • static: short time interval (20-50 ms) • dynamic: change of parameters • The features describe Front-End of the recognizer
Filter bank based coefficients • Reduce the dimensionality of spectral signal representation • fundamental decisions: structure of the filter bank: number of filters, their response and spacing in frequency • symmetric triangular filter used to weight DFT values: “quick and dirty” approximation of band-pass filtering • Example of a filter bank (24 triangular filters) spaced according to Mel-scale • Mel based cepstral coeffcients (MFCC), most popular in ASR: usually computed as IFFT of log-energy output of filter bank consisting of i triangular filter masks: • C0 approximates log-energy of the signal, higher order coefficients represents log-energy ratio between bands (i.e. c1 provides log-energy ratio between intervals [0,Fs/4] and [Fs/4, Fs/2]- higher for sonorants, lower for fricatives), but for higher order coefficients interpretation is complicated • IFFT is orthogonal transform, i.e. coeffcients are uncorrelated -> simplified acoustic models can be used • MFCC speech reconstruction (IBM, ICASSP-2000)
Fundamental Frequency and Formants • F0 estimation: (Hess) determining the main period in quasi-periodic waveform • usually using autocorrelation function and the average magnitude difference function (AMDF) where L is the frame length Npis number of point pairs (peak in ACF and valley in AMDF indicates F0) • usually speech signal is first low-pass filtered to avoid influence of formants • cepstral analysis: peak at T0 • Formant ferquency estimation: • resonances in vocal tract are related to complex poles of LPC model zk=Re(zk)+jIm(zk) • cepstral smoothed spectrum also used • a lot of methods, but.. • tracking of formant frequencies is a problem not solved yet
Dynamic features • Temporal variation and contextual dependency • time derivative features • not sensitive to slow channel-dependent variations of static parameters • first order difference is affected by various types of noise, thus smoothing necessary • polynomial expansion of time derivatives (Furui) • second order derivatives: acceleration also often used • Typical set of parameters: E,12 MFCC, DE, DMFCC, DDE, DD MFCC: observation vector consists of 39 parameters • Other types of dynamic features: • spectral variation function • dynamic cepstrum • Karhunen-Loeve Transformation (KLT): segmenting speech into subword units depending only on acoustic properties without a priori defined units, like phonemes • RASTA processing - band-pass filtering