Download
1 / 9
90 likes | 177 Vues
Learn how DynaSAND technology revolutionizes data storage, format generation, and metadata creation for linguistic resources in the CLARIN project. Discover the plan to integrate other Meertens language resources into the system.

E N D
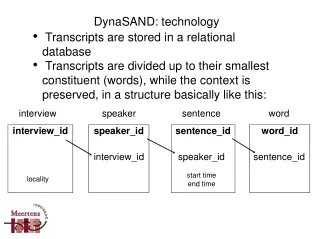
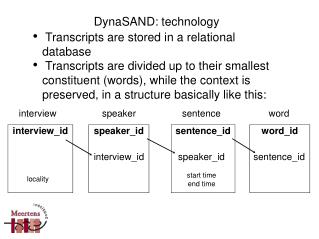
interview speaker sentence word interview_id speaker_id sentence_id word_id interview_id speaker_id sentence_id start time end time locality DynaSAND: technology • Transcripts are stored in a relational database • Transcripts are divided up to their smallest constituent (words), while the context is preserved, in a structure basically like this:
category category_id word_id word attributes word_id attribute_id value_id word_id DynaSAND: technology • This means that individual words can be addressed, e.g. for POS tagging • The POS tags are themselves stored as separate categories, attributes and values, not as opaque strings:
Generating other formats • The fact that the data is stored in its smallest constituent parts makes it relatively easy to generate other formats • Example: we realize that a binary format like a relational database is not appropriate for long-term archival, so we made the SAND transcriptions available as TEI XML by creating a template and filling that with data from the database with a script • Another example: the IMDI metadata for another corpus (The Goeman-Taeldeman-Van Reenen Project, or GTRP corpus) were created in the same way
Generating metadata for CLARIN • Previous experience with SAND and GTRP indicates that generating XML metadata for CLARIN from our databases should be doable • The TEI and IMDI for SAND and GTRP were created once and are static; we plan to make the process more dynamic for CLARIN metadata by creating the XML on the fly (and implementing a caching mechanism for performance reasons) so that the metadata is always up to date
Edisyn (European Dialect Syntax) • One of the goals of Edisyn is the development of a search engine which uses one tag set to search different corpora, including the SAND, concurrently • Central tag set is being developed by Franca Wesseling; we plan to make it compatible with ISOcat • Search engine translates these tags to the native tag sets of the corpora • Ideal case: corpora are hosted by their own organizations and accessible via a web service • In practice: the Meertens has local copies of the corpora • Participating corpora: SAND, CORDIAL-SIN (Portuguese), ASIS (Italian), EMK (Estonian); more to come
Other Meertens language resources • PLAND (Plant Names in Dutch Dialects) • NVD (Dutch Database of First Names) • NFD (Dutch Database of Family Names) • Corpus of free dialect speech (sound recordings) • Dutch Database of Toponyms (in development) • Dutch Song Database • Dutch Folktale Database
Other Meertens language resources • Apart from part of the sound recordings, all these are web-based and based on the same database technology • We plan to make CLARIN metadata available for these resources in a stepwise manner: first metadata on the corpus level, later also metadata on the record level • The technologies involved (OAI-PMH) are new to us, so we want to do this in close cooperation with a “harvesting” institution to make sure that our stuff is correct
Further in the future • The Meertens Institute wants to be part of CLARIN and in the future we also hope to contribute to the development of tools to work with language resources