Learning from Infinite Training Examples
Explore the concept of learning from infinite web data with limited computing power, focusing on online learning methods and stochastic gradient descent. Discover how to optimize learning algorithms for maximum efficiency and accuracy.


Learning from Infinite Training Examples
E N D
Presentation Transcript
Learning from Infinite Training Examples 3.18.2009, 3.19.2009 Prepared for NKU and NUTN seminars Presenter: Chun-Nan Hsu (許鈞南) Institute of Information Science Academia Sinica Taipei, Taiwan
The Ever Growing Web(Zhuang, -400) • Human life is finite, but knowledge is infinite. Following the infinite with the finite is doomed to fail. • 人之生也有涯,而知也無涯。以有涯隨無涯,殆矣。 • 莊子,西元前四百年
Analogously… • Computing power is finite, • but the Web is infinite. • Mining infinite Web with finite computing power… • is doomed to fail?
Other “holy grails” in Artificial Intelligence • Learning to understand natural languages • Learning to recognize millions of objects in computer vision • Speech recognition in noisy environment, such as in a car
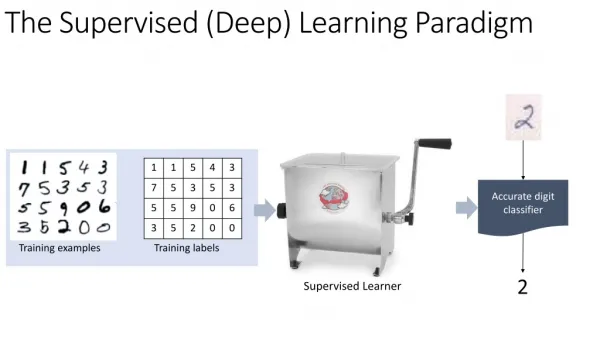
On-Line Learning vs. Off-Line Learning • Nothing to do with human learning by browsing the web • Definition: Given a set of new training data, • online learner can update its model without reading old data while improving its performance. • By contrast, off-line learner must combine old and new data and start the learning all over again, otherwise the performance willsuffer.
Off-Line Learning • Nearly all popular ML algorithms are off-line today • They scan the training examples many passes iteratively until an objective function is minimized • For example: • SMO algorithm for SVM • L-BFGS algorithm for CRF • EM algorithm for HMM and GMM • Etc.
Single-pass on-line learning • The key for on-line learning to win is to achieve satisfying performance right after scanning the new training examples for a single pass only
Previous work on on-line learning • Perceptron • Rosenblatt 1957 • Stochastic Gradient Descent • Widrow & Hoff 1960 • Bregment Divergence • Azoury & Warmuth 2001 • MIRA (Large Margin) • Crammer & Singer 2003 • LaRank • Borde & Bottou 2005, 2007 • EG • Collins & Peter Bartlet et al. 2008
Stochastic Gradient Descent (SGD) • Learning is to minimize a loss function given training examples
Optimal Step Size(Benveniste et al. 1990, Murata et al. 1998) • Solving gradient = 0 by Newton’s method • Step size is asymptotically optimal if it approaches to
Single-Pass Result (Bottou & LeCun 2004) • Optimum for n+1 examples is a Newton step away from the optimum for n examples
2nd Order SGD • 2nd order SGD (2SGD): Adjusting the step size to approach to Hessian • Good News: from previous work, given sufficiently large training examples, 2SGD achieves empirical optimum in a single pass! • Bad News: it is prohibitively expensive to compute H-1 • e.g. 10K features, H will be a 10K by 10K matrix = 100M floating point array • How about 1M features?
Approximating Jacobian(Aitken 1925, Schafer 1997) • Learning algorithms can be considered as fixed-point iteration mapping =M() • Taylor expansion gives • Eigenvalues of J can be approximated by
Approximating Hessian • Consider SGD mapping as a fixed-point iteration, too. • since J=M’=I-H, we have eig(J)=eig(M’)=eig(I-H), • therefore, (since H is symmetric) eig(J)=1- eig(H) eig(H-1)= / 1-eig(J)= / 1-γ.
Estimating Eigenvalue Periodically • Since the mapping of SGD is stochastic, estimating the eigenvalues at each iteration may yield inaccurate estimations. • To make the mapping more stationary, we use Mb=M(M(…M(θ)…)) • From the law of large number, b consecutive mappings, Mb, will be less “stochastic” • From Equation (4), we can estimate eig(Jb) by b
Experimental Results • Conditional Random Fields (CRF) (Lafferty et al. 2001) • Sequence labeling problems – gene mention tagging
In effect, CRF encodes a probabilistic rule-based system with rules of the form: If fj1(X,Y) & fj2(X,Y) & … & fjn(X,Y) are non-zero, then the labels of the sequence are Y with score P(Y|X) • If we have d features and considers w context, then an order-1 CRF encodes this many rules:
CoNLL 2000 base NP Tag Noun phrases 8936 training 2012 test 3 tags, 1015662 features CoNLL 2000 chunking Tag 11 POS types 8936 training 2012 test 23 tags, 7448606 features Performance measure: F-score: BioNLP/NLPBA 2004 Tag 5 types of bio-entities (e.g., gene, protein, cell lines, etc.) 18546 training 3856 test 5977675 features BioCreative 2 Tag gene names 15000 training 5000 test 10242972 features Tasks and Setups
Feature types for BioCreative 2 O(22M ) rules are encoded in our CRF model!!!
First Pass 23.74 sec Execution TimeCoNLL 2000 base NP
First Pass 196.44 sec Execution TimeCoNLL chunking
First Pass 287.48 sec Execution TimeBioNLP/NLPBA 2004
First Pass 394.04 sec Execution TimeBioCreative 2
Experimental results for linear SVM and convolutional neural net • Data sets
Linear SVM • Convolutional Neural Net (5 layers) ** Layer trick -- Step sizes in the lower layers should be larger than in the higher layer
Mini-conclusion: Single-Pass • By approximating Jacobian, we can approximate Hessian, too • By approximating Hessian, we can achieve near-optimal single-pass performance in practice • With a single-pass on-line learner, virtually infinitely many training examples can be used
Analysis of PSA • PSA is a member in the family of “discretized Newton Methods” • Other well-known members include • Secant method (aka. Quickprop) • Steffensen’s method (aka. Triple Jump) • General form of these methods where A is a matrix designed to approximate the hessian matrix without actually computing the derivative
PSA • PSA is not secant nor is it steffensen’s method • PSA iterates a 2b-step “parallel chord” method (i.e., fixed rate SGD) followed by an approximated Newton step • Off-line 2-step parallel chord method is known to have an order 4 convergence
Are we there yet? • With single-pass on-line learning, we can learn from infinite training examples now, at least in theory • A cheaper, quicker method to annotate labels for training examples • Plus a lot of computers…
The human life is finite, but the knowledge is infinite. Learning from infinite examples by applying PSA to 2nd Order SGD is a good idea!
Thank you for your attention! http://aiia.iis.sinica.edu.tw http://chunnan.iis.sinica.edu.tw/~chunnan This research is supported mostly by NRPGM’s advanced bioinformatics core facility grant 2005-2011.