Dynamic Tracking of Frequent Items Using Efficient Algorithms
In the study of dynamic data management, particularly in database systems, tracking "hot items" or frequently occurring items is critical for tasks such as anomaly detection and market analysis. This article presents efficient algorithms for handling dynamic insertions and deletions while maintaining quality in identifying hot items. The proposed Divide and Conquer approach, combined with probabilistic methods using hash functions, ensures that space and time complexities remain manageable. The results highlight a significant improvement over existing methods, proving essential for real-time data analytics.

Dynamic Tracking of Frequent Items Using Efficient Algorithms
E N D
Presentation Transcript
Tracking most frequent items dynamically. Article by G.Cormode and S.Muthukrishnan. Presented by Simon Kamenkovich.
Motivation • Most DB management systems maintains “hot items” statistics. • Hot items are used as simple outliers in data mining, anomaly detection in network applications and financial market data. • The proposed algorithm handles deletions and insertions and with better qualities then other existing methods
Introduction Given: n integers in the range [1… m] So there may be up to k hot items and there may be none.
Preliminaries If we’re allowed O(m) space, then simple heap will process each insert and delete in O(log m) and find all the hot items in O(k logk). Lemma 1: Any algorithm which guarantees to find all and only items which have frequency greater then 1/(k+1) must store at Ω(m) bits.
Base method DivideAndConquer(l,r,thresh) if oracle(l,r) > thresh if (l=r) then output(l) else DivideAndConquer(l,r-l/2,thresh) DivideAndConquer(r-l/2+1,r,thresh) Theorem 1: Calling DivideAndConquer(1,m,n/(k+1)) will output all and only hot items. A total of O(k log m/k) calls will be made to the oracle.
Oracle design • N.Alon et al. - requires O(km) space • Gilbert (Random Subset Sums) requires O(k²log m log k/δ) space • Charikar et al. requires O(klogm log k/δ) • Cormode requires O(k logm log k/δ)
Group Testing Idea: To design number of tests, each of which groups together a number of m items in order to find up to k items which test positive. General procedure: for each transaction on item i we determine each subset it’s included in ,S(i). And increment or decrement the counters associated with the subsets. Majority item can be found for insertions only case in O(1) time and space by the algorithm of Boyer and Moore.
Deterministic algorithm Each test includes half of the range [1..m], corres- ponding to binary representations of values int c[0…log m] UpdateCounters(i, transtype, c[0…log m]) c[0]=c[0] + diff for j=1 to log m do If (transtype = ins) c[j] = c[j] + bit(j,i) Else c[j] = c[j] - bit(j,i)
Deterministic algorithm(cont) FindMajority(c[0 ... log m]) Position = 0, t =1 for j=1 to log m do if (c[j] > c[0]/2) then position = position + t t = 2* t return position Theorem 2: The above algorithm finds a majority item if there is one with time O(log m) per operation.
Coupon Collector Problem • X – number of trials required to collect at least one of each type of coupon • Epoch i begins with after i-th success and ends with (i+1)-th success • Xi – number of trials in the i-th epoch • Xi distributed geometrically and pi = p(k-i)/k • p is probability that coupon is good
Using hash functions We don’t store sets explicitly – O(mlogk), instead we choose the set in pseudo-random fashion using hash functions: Fix a prime P > 2k, Take a and b uniformly from [0…P-1] Choose T= log k/δ pairs of a,b ; each pair will define 2k sets.
Data Structure log(k/δ) groups 2k subsets log m counters
ProccessItem Initialize c[0 … 2Tk][0 … log m] Draw a[1 … T], b[1 … T], c=0 ProccessItem(i,transtype,T,k) for all (i,transtype) do if (trans = ins) c = c +1 else c = c – 1 for x = 1 to T do index = 2k(x-1) + (i*a[x]+b[x] mod P) mod 2k //they had 2(x-1) UpdateCounters(i,transtype,c[index]) Space used by the algorithm is O(k log(k/ δ) log m).
Lemma Lemma 2: The probability of each hot item being in at least one good set is at least 1- δ Proof: For each T repetitions we put a hot item in one of 2k buckets. If m < 1/(k+1) then there is a majority and we can find it If m > 1/(k+1) then we won’t be able to find a majority Probability of failure < ½ by Markov inequality. Probability to fail on each T is at most δ/k. Probability of any hot items failing at most δ.
GroupTest GroupTest(T,k,b) for i=1 to 2Tk do // they had T here if c[i][0] > cb position = 0; t =1 for j = 1 to log m do if c[i][j] > cb and c[i][0] – c[i][j] > cb or c[i][j] < cb and c[i][0] – c[i][j] < cb then Skip to next i if c[i][j] > cb position = position + t t = 2 * t return position
Algorithm properties Theorem 4: With proability at least 1- δ, calling the GroupTest(log k/δ,k,1/(k+1)) procedure finds all the hot items using O(k log k/δ logm) space. The time for an update is O(logk/δ log m) and the time to list all hot items is O(k log k/δ log m) Corollary 1: If we have the small tail property, then we will output no items which are not hot. Proof: We will look for hot items only if it exists and only it will be output.
Algorithm properties (cont) Corollary 2: The set of counters created with T= log k/ δ can be used to find hot items with parameter k’ for any k’<k with probability of success 1 – δ by calling GroupTest(logk/δ,k,1/(k’+1) Proof: According to Lemma2, since Lemma 4: The output of the algorithm is the same for any reordering of the input data.
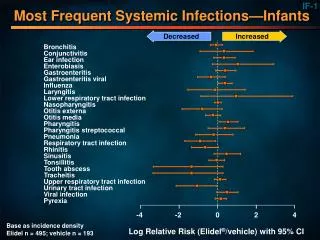
Experiments GroupTesting algorithm was compared to Loosy Counting and Frequent algorithms. The authors implemented them so that when an item is deleted we decrement the corresponding counter if such exist. Definitions: The recall is the proportion of the hot items that are found by the method to the total number of hot items. The precision is the proportion of items identified by the algorithm, which are hot, to number of all output items.
Synthetic data (Recall) Zipf for hot items: 0 – distributed uniformly , 3 – highly skewed
Synthetic data (Precision) GroupTesting required more memory and took longer to process each item.
Real Data (Recall) Real data was obtained from one of AT&T network for part of a day.
Real Data (Precision) Real data has guarantee of having small tail property….
Varying frequency at query time The data structure was build for queries at the 0.5% level, but was then tested with queries ranged from 10% to 0.02% Other algorithms are designed around fixed frequency threshold supplied in advance.
Conclusions and extensions • New method which can cope with dynamic dataset is proposed. • It’s interesting to try to use the algorithm to compare the differences in frequencies between different datasets. • Can we find combinatorial design that achieve the same properties but in deterministic construction for maintaining hot items?






![Finding Frequent Items in Data Streams [Charikar-Chen-Farach-Colton]](https://cdn1.slideserve.com/3361496/finding-frequent-items-in-data-streams-charikar-chen-farach-colton-dt.jpg)