Download

1 / 23
230 likes | 247 Vues
This class discusses how children detect triggers in their input and explores the practical limits of decoding in language acquisition. It also explores the efficiency of on-line decoding compared to domain search models and the importance of dealing with parametric ambiguity in learning.

E N D
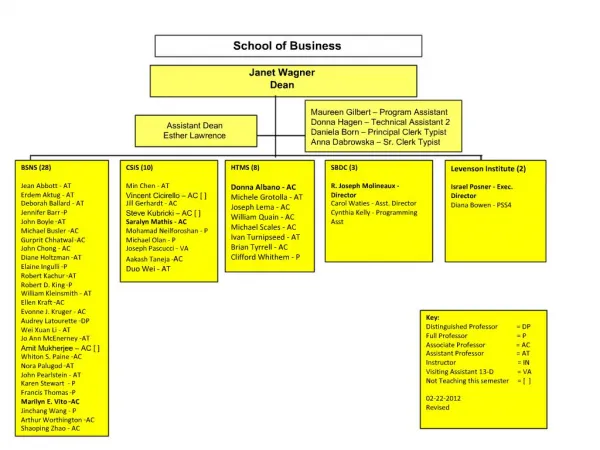
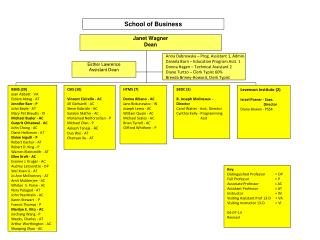
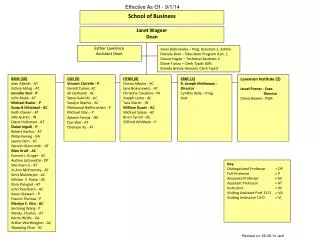
Introduction to Language Acquisition Theory Janet Dean Fodor St. Petersburg July 2013 Class 7. How could children detect the triggers in their input?
Preview of today’s class • Last time: How much parametric information does the input contain? We found unambiguous triggers, which could permit ‘squeaky-clean’ deterministic P-setting. • Today, how well can LM extract the info that is there? • Recap: Input guidance (parametric decoding) extracts much more information per sentence than trial-and-error grammar testing. • But today we’ll see there are practical limits on decoding: Ambiguous inputs can’t be exhaustively decoded. Syntactic parsing is not fail-safe. • So we may have to settle for decoding that is not squeaky clean. A non-deterministic version of the treelet-based LM, which engages in some guesswork.
On the trail of the optimal learner (= a child)First decision: Search or decode? To set parameters search domain decode input sentences(trial-and-error) if ambig, guess wait for unambig½ random with innate list of parser finds walk memory unambig triggers unambig triggers Deterministic STL TLA Yang’s VM
Recap Class 2: On-line decoding is best • Wasteful to choose a grammar hypothesis (Gh) to try out, before examining the properties of the input sentence (as the domain-search models do). • Instead, let the parsing process reveal which grammar could work. • Start with Gc (LM’s current grammar). If succeeds, fine.If it fails, it will fail at a particular place in the parse tree being built. Failure = the next word of the sentence can’t be fitted into the tree structure. • Details of the tree structure there + the incoming word provide clues to what new parameter value (treelet) is needed in order to make them compatible, i.e., to bridge the gap in the parse tree. • Simple example in Class 2: preposition-stranding.
Patching up gaps in parse trees • FR: Pierre comptesouventsespoulets.EN: Peter often counts his chickens. • In FR, the verb moves up out of VP, into TP. In EN, the Tense moves down onto the verb in VP. (See trees, next slides) • A child just beginning to acquire adverbs. She knows what ‘souvent/often’ means but not how to use it in a sentence. • The FR learner can parse as far as ‘Pierre compte’ but is expecting the object right after the verb. She needs a treelet that lets her attach the Advinto the tree before the object. • An EN learner expects the verb to follow the subject. She needs a treelet that lets her attach Advinto the tree preceding the verb.
Treelets for VP-adverbs • In GB theory this difference is not due to a word-order parameter. It is due to two different ways in which a verb can acquire tense (e.g., walk+Past walked). • Both children need a treelet in which the Adv is left-adjoined to the VP: • But this adjunction treelet must fit inside a larger treelet which makes it possible for the verb to acquire tense even though Adv prevents it from being adjacent to the T head of the clause (TP). • UG offers two different treelets for achieving this. Why left? Because this adverb precedes the object in both FR & EN.
Parametric treelets for V-raising & Tns-lowering • French: Verb raising English: Affix-hopping (= tense lowering) • The French learner will find that only the Verb Raising treeletfills the gap in her parse tree. • The English learner will find that only the Tns-lowering treelet fills the gap in her parse tree.
The greater efficiency of on-line decoding compared with domain search models • With decoding, an input sentence provides a word-by-word guide on how to improve Gc when necessary. This extracts far more info from the input than just succeed/fail feedback on an antecedently selected Gh. • Sothis on-line learning-by-parsing approach predicts faster convergence on the target grammar. • We measure learning speed in terms of how many input sentences are needed for convergence. • Calculated by Fodor & Teller (2000). For 30 parameters, the TLA needs over a billion more input sentences than a (perfect) decoding learner needs. • Savings due to decoding confirmed in simulation studies compared with both TLA and VM (Fodor & Sakas, 2004).
Second decision: Within decoding,how to deal with parametric ambiguity? decode input sentences if ambig, guess wait for unambig innate list of parser findsunambig triggers unambig triggers
For deterministic learning, LM must wait for unambiguous input • Deterministic learning is good – it avoids to-and-fro re-setting of parameters; it predicts children make few errors of comission; it solves the SP-retrenchment problem. • But rigorous discipline! A deterministic LM must not set parameters based on parametrically ambiguous input. If a sentence is ambiguous, it must be rejected for learning (though the child may comprehend and respond to it). • In Class 6 we estimated that there might be enough unambiguous input for a deterministic LM to set all the parameters accurately. • But we stalled on: How could LM know whether an input sentence is parametrically unambiguous?
How to recognize unambiguity? • An innate list of unambiguous triggers?That seems to be what Chomsky’s original ‘switch-setting’ model would have required. • Each parameter was associated with a 2-way switch, pre-programmed with knowledge of what sentences each setting could license. Presumably via some sort of E-language pattern detector, but that was never specified. • When an unambiguous sentence is heard, it activates the appropriate pattern detector, thus goes directly to the relevant switch, and flips it if set wrong. • When an ambiguoussentence is heard, it would activate the pattern detectors of two or more switches. • For deterministic learning, we could assume that conflicting activations cancel each other out, so no switch is re-set. • Easy! But implausible: Huge reliance on innate E-language.
Better: Can the parserdetect parametric unambiguity? • A parallel parsing mechanism could do so. Compute all possible parse-trees for the sentence, using all possible treelets. If there’s more than one parse, it’s ambiguous. • But even adults don’t have the capacity to parallel parse. • Many psycholinguists claim that parsing is only serial (only one analysis is computed). Some assume there’s limited parallelism. But not enough for full ambiguity detection. • Within capacity of a serial parser: A sentence is unambig if the parser finds no choice-points in the parse. • Good, but: We’ll see that many input sentences must be discarded because of choice-points in the parse – even though they are not in fact parametrically ambiguous. • Maybe a temporary ambiguity only, resolved later in the sentence. E.g. Sue knows Bill (is a librarian).
A super-cautious learner may fail • Everything to the right of a choice-point is off-limits for cautious learning. But it is possible that every trigger for Pi(v) is to the right of a choice-point! If so, Pi(v) can’t be set. • E.g. In every language that’s +Subj-initial and –NullSubj, the initial subject is ambiguous between a topic and a non-topic. That blocks learning from any part of the sentence! • A merely temporary ambiguity: Sentence starts NPACC V, could be NullSubj with no movement of NP or V. Or could be VerbSecond (NP and V both move). But it continues with NPDAT which rules out the no-movement analysis. • Only one potential analysis survives, but the parser can’t know that unless it computes both = parallel parsing!*** • Conclusion: Even if the language domain does contain unambiguous triggers, LM may fail to recognize them. Discarded unnecessarily, due to lack of parsing power.
Unrealistic, in any case, to assume the parser never makes mistakes • Even if the learning mechanism aims to be squeaky clean, its front end is a parsing mechanism which is not. • Even in adult parsing, with a complete and correct grammar, parsing mistakes occur on-line. • Especially relevant here: There’s a tendency to overlook the presence of ambiguity, i.e., to fail to spot a choice-point. (Examples, next slide.) • Thus a sentence for which the parser reports only analysis A might in reality be ambiguous between A and B. • That can be bad for comprehension. But a disaster for learning: it could mis-set a parameter.
Adults sometimes overlook ambiguity (1) The horse raced past the barn fell.Could mis-trigger the P-value for asyndetic coordination. ( …past the barn and fell. As in Spanish.) (2)While Mary was mending the sock fell off her lap. Could mis-trigger [+null subject] (…mending the sock, pro fell off her lap.) (3)Put the frog on the napkin in the box.See scenario Does PP1 modify the preceding noun, or is it an argument in the VP? On-line, the parser favors VP-attachment (napkin is GOAL). But 2nd PP then forces reanalysis: (napkin modifies frog; box is GOAL). • In this case, adults typically recover from the garden path.
Children overlook ambiguity more than adults • Trueswell, Sekerina, Hill & Logrip(1999) Act-out task, with eye-movements monitored. Age 4;8 – 5;10 Put the frog on the napkin in the box.
A learner’s parser is not fully reliable • Most common response by children: Put the frog (THEME) onto the spare napkin (GOAL), then put it/them into the box (GOAL-2) – or ignore the box! • Adult control group: Early gaze pattern like children (on-line garden path). But their action response is correct: pick up [the frog that is on the napkin] (THEME) and put it into the box (GOAL). Shows they have recovered from the g-path. • Conclusion: Children have the same parsing biases as adults, and are subject to the same garden-path mis-analyses. (As expected if parsing mechanism is innate.) • But they are worse than adults at recovering from them – they are inflexible, perhaps due to resource limits. • Child might deduce asyndetic coordination, from mis-parse!
More arguments for non-deterministic learning • Determinism is badly impacted by ‘noisy’ (imperfect) input. • Mis-heard sentences could be disruptive, permanently. Not-yet-acquired bits of a sentence may be ignored by child receiving ungrammatical input. (E.g., overlooking finiteness in root clauses.) • Prosody and semantics can provide valuable hints about novel syntactic structure: Prosody can indicate surface constituent bracketing. Semantics can indicate theta roles, argument structure, agreement features, etc. • But these are only hints - sometimes suggest wrong syntactic structure. E.g. [Jeremy hates] [mean people]. • So a deterministic learner could not afford to accept any help at all from these not-fully-reliable sources.
Instead: Parametric decoding with guessing • So let’s consider now a decoding learner that doesn’t check for ambiguity. Just makes its best guess on every sentence. • A non-deterministic treelet-based learner. Different versions possible. Here: the Parse Naturally STL(Fodor 1998b) • Assuming an innate stock of parametric treelets, from which to select the correct ones for the target language. • Builds tree structure, applying the usual innate human parsing principles: Minimal Attachment, etc. and priority to more frequent/accessible structures.♦ It parses every input sentence with all the treelets accessible, though to different degrees. ♦ Every time a treelet is used its activation level automatically rises slightly (just as for lexical items), so it’s more accessible in future. Helpful treelets thus become dominant.
Parse Naturally STL – In favor • When input happens to be unambiguous, the PN-STL finds the right parse (within its resource limits) and sets parameters correctly. • The PN-STL doesn’t discard any input. For an ambiguous input, it guesses one of the grammars that can license it. • Guesses are linguistically smart, since parsing principles (Minimal Attachment, Minimal Chain Principle) parallel UG economy principles (minimize structure, shortest movement chains). • Affords an account of default P-values: Different innate starting-levels of activation of the various treelets. E.g., the VO treelet may start out more active than OV. • This predicts "strength markedness”, i.e., a non-default value needs more input to become dominant. (Pinker 1979)
Parse Naturally: more advantages • Predicts gradual shift to a marked P-setting, with some fluctuation for a while as neck-and-neck with default value. Compatible with data on slow time-course of stabilizing some parameter values. (Yang; van Kampen) • Frequency-sensitivity permits recovery from errors that occurred due to guessing or noisy input. • Maybe even recovery from superset errors. The treelet for the 'superset' value won’t be used falls below threshold. • All of this is because PN is just a normal working parser, trying to comprehend each sentence it encounters. • Unlike VM, its memory store for the relative strengths of the parameters is not an add-on, but an integral automatic consequence of the parser using the treelets.
Parse Naturally: General assessment • PN-STL extracts as much parametric information as possible from every input sentence (within the limit of employing a merely serial parser). • It has flexibility in face of real-life imperfect input and parsing errors (unlike deterministic treelet model). • It employs no learning mechanism at all, other than what must be available for sentence processing in any case. • Makes few demands on evolution – just an innate mental collection of bits of tree structure that humans can deploy. • BUT: It sacrifices precision. Its reliability needs to be evaluated. (No simulation data yet.) • Open questions at this time: Can it obey SP without massive retrenchment? Can it make safe use of conditioned triggers? These require certainty about other parameters.
Precision or flexibility? • Competing demands unresolved. More research needed. • Awaiting your contributions! REMINDER: WRITING ASSIGNMENT • Prepare a question, to ask in class on Friday, about some aspect of language learnability that we haven’t touched on, or haven’t dealt with satisfactorily. Indicate why it is important or of interest. • Hand in a written copy to me on Wednesday (to include in your grade). Keep a copy so that you can ask it in class on Friday. TODAY!