HMM for CpG Islands
450 likes | 604 Vues
HMM for CpG Islands Parameter Estimation For HMM Maximum Likelihood and the Information Inequality Lecture #7. Background Readings : Chapter 3.3 in the text book, Biological Sequence Analysis , Durbin et al., 2001. Shlomo Moran, following Danny Geiger and Nir Friedman. HMM for CpG Islands.

HMM for CpG Islands
E N D
Presentation Transcript
HMM for CpG IslandsParameter Estimation For HMMMaximum Likelihood and the Information Inequality Lecture #7 Background Readings: Chapter 3.3 in the text book, Biological Sequence Analysis, Durbin et al., 2001. Shlomo Moran, following Danny Geiger and Nir Friedman
M M M M S1 S2 SL-1 SL T T T T x1 x2 XL-1 xL Reminder: Hidden Markov Model Next we apply HMM for the question of recognizing CpG ilands
Hidden Markov Model for CpG Islands Domain(Si)={+, -} {A,C,T,G} (8 values) The states: … … A- T+ G + … … A T G In this representation P(xi| si) = 0 or 1 depending on whether xi is consistent with si . e.g. xi= G is consistent with si=(+,G) and with si=(-,G) but not with any other state of si.
M M M M S*1 S*2 S*L-1 S*L T T T T x1 x2 XL-1 xL Reminder: Most Probable state path Given an output sequence x = (x1,…,xL), Amost probablepaths*= (s*1,…,s*L)is one which maximizes p(s|x).
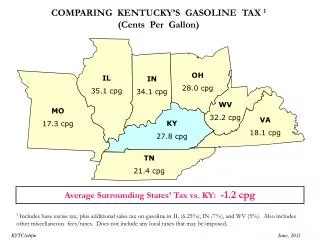
A- C- T- T+ G + A C T T G Predicting CpG islands via most probable path: • Output symbols: A, C, G, T (4 letters). • Markov Chain states: 4 “-” states and 4 “+” states, two for each letter (8 states total). • A most probable path (found by Viterbi’s algorithm) predicts CpG islands. Experiment (Durbin et al, p. 60-61) shows that the predicted islands are shorter than the assumed ones. In addition quite a few “false negatives” are found.
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi Reminder: Most probable state Given an output sequence x = (x1,…,xL), si is amost probablestate (at location i)if: si=argmaxkp(Si=k |x).
A- C- T- T+ G + A C T T G Finding the probability that a letteris in a CpG island via the algorithm for most probable state: i • The probability that the occurrence of G in the i-th location is in a CpG island (+ state) is: • ∑s+p(Si =s+|x) = ∑s+F(Si=s+)B(Si=s+) • Where the summation is formally over the 4 “+” states, but actually only state G+ need to be considered (why?)
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi mkl k l ek(b) b Defining the Parameters An HMM model is defined by the parameters: mkland ek(b), for all states k,l and all symbols b. Let θdenote the collection of these parameters:
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi Training Sets To determine the values of (the parameters in) θ, use a training set = {x1,...,xn}, where each xjis a sequence which is assumed to fit the model. Given the parameters θ, each sequence xj has an assigned probability p(xj|θ).
Maximum Likelihood Parameter Estimation for HMM The elements of the training set{x1,...,xn}, are assumed to be independent, p(x1,..., xn|θ) = ∏j p (xj|θ). ML parameter estimation looks for θ which maximizes the above. The exact method for finding or approximating this θdepends on the nature of the training set used.
M M M M S1 S2 SL-1 SL T T T T x1 x2 XL-1 xL Data for HMM • The training set is characterized by: • For each xj, the information on the states sji (the symbolsxji are usually known). • Its size (sum of lengths of all sequences).
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi Case 1: ML when Sequences are fully known We know the complete structure of each sequence in the training set{x1,...,xn}. We wish to estimate mkland ek(b) for all pairs of states k, l and symbols b. By the ML method, we look for parameters θ* which maximize the probability of the sample set: p(x1,...,xn| θ*) =MAXθ p(x1,...,xn| θ).
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi Case 1: Sequences are fully known For each xjwe have: Let Mkl= |{i: si-1=k,si=l}| (in xj). Ek(b)=|{i:si=k,xi=b}| (in xj).
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi Case 1 (cont) By the independence of the xj’s, p(x1,...,xn| θ)=∏jp(xj|θ). Thus, if Mkl = #(transitions from k to l) in the training set, and Ek(b) = #(emissions of symbol b from state k) in the training set, we have:
Case 1 (cont) So we need to find mkl’sand ek(b)’s which maximize: Subject to:
Case 1 (cont) Rewriting, we need to maximize:
Case 1 (cont) Then we will maximize also F. Each of the above is a simpler ML problem, which is similar to ML parameters estimation for a die, treated next.
Defining The Problem Let X be a random variable with 6 values x1,…,x6 denoting the six outcomes of a (possibly unfair) die. Here the parameters are θ ={1,2,3,4,5, 6} , ∑θi=1 Assume that the data is one sequence: Data = (x6,x1,x1,x3,x2,x2,x3,x4,x5,x2,x6) So we have to maximize Subject to: θ1+θ2+ θ3+ θ4+ θ5+ θ6=1 [and θi0 ]
Side comment: Sufficient Statistics • To compute the probability of data in the die example we only require to record the number of times Ni falling on side i (namely,N1, N2,…,N6). • We do not need to recall the entire sequence of outcomes • {Ni | i=1…6} is called sufficient statistics for the multinomial sampling.
Datasets Statistics Sufficient Statistics • A sufficient statistics is a function of the data that summarizes the relevant information for the likelihood • Formally, s(Data) is a sufficient statistics if for any two datasets D and D’ • s(Data) = s(Data’ ) P(Data|) = P(Data’|) Exercise: Define “sufficient statistics” for the HMM model.
¶ log P ( Data | ) N N θ = - = j 6 0 å ¶ q q 5 - q 1 j j i = i 1 Maximum Likelihood Estimate By the ML approach, we look for parameters that maximizes the probability of data (i.e., the likelihood function ). We will find the parameters by considering the corresponding log-likelihood function: A necessary condition for (local) maximum is:
Finding the Maximum Rearranging terms: Divide the jth equation by the ith equation: Sum from j=1 to 6: So there is only one local – and hence global – maximum. Hence the MLE is given by:
Note: Fractional Exponents are possible Some models allow ni’s to be fractions(eg, if we are uncertain of a die outcome, we may consider it “6” with 20% confidence and “5” with 80%). Our analysis didn’t assume that the ni are integers, thus it applies also for fractional exponents.
Generalization for distribution with any number n of outcomes Let X be a random variable with k values x1,…,xkdenoting the k outcomes of Independently and Identically Distributed experiments, with parameters θ ={1,2,...,k} (θi is the probability of xi). Again, the data is one sequence of length n, in which xi appears ni times. Then we have to maximize Subject to: θ1+θ2+ ....+ θk=1
Generalization for n outcomes (cont) By treatment identical to the die case, the maximum is obtained when for all i: Hence the MLE is given by the relative frequencies:
ML for a Single Dice, Normalized Version • Consider the two experiments for a 3-sided dice: • 8 tosses: 2 x1,, 3 x2, 5 x3. • 800 tosses: 200 x1,, 300 x2, 500 x3 • Clearly, both imply the same ML parameters. • In general, when formulating ML for a single dice, we can ignore the actual number n of tosses, and just use the fraction of each outcome.
Normalized version of ML (cont.) Thus we can replace the number of outcomes ni by pi=ni/n, and get the following normalized setting of the ML problem for a single dice: And the same analysis yields that a maximum is obtained when:
Rephrasing the ML inequality We can rephrase the “ML for single dice” inequality: Taking logarithms, we get
Using the Solution for the“Dice Maximum Likelihood” to Find Parameters for HMMWhen all States are Known
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi The Parameters Let Mkl = #(transitions from k to l) in the training set. Ek(b) = #(emissions of symbol b from state k) in the training set. We need to:
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi Apply to HMM (cont.) We apply the previous technique to get for each k the parameters {mkl|l=1,..,m} and {ek(b)|bΣ}: Which gives the optimal ML parameters
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi Summary of Case 1: Sequences are fully known We know the complete structure of each sequence in the training set{x1,...,xn}. We wish to estimate mkl and ek(b) for all pairs of states k, l and symbols b. When everything is known, we can find the (unique set of) parameters θ* which maximizes p(x1,...,xn| θ*) =MAXθ p(x1,...,xn| θ).
s1 s2 sL-1 sL si X1 X2 XL-1 XL Xi Adding pseudo counts in HMM We may modify the actual count by our prior knowledge/belief (e.g., when the sample set is too small) : rkl is our prior belief on transitions from k to l. rk(b) is our prior belief on emissions of b from state k.
Case 2: State Paths are Unknown. Here we use ML with Hidden Parameters
Dice likelihood with hidden parameters Let X be a random variable with 3 values 0,1,2. Hence the parameters are θ ={0,1,2} , ∑θi=1 Assume that the data is a sequence of 2 tosses which we don’t see, but we know the the sum of the outcomes is 2. The problem: Find parameters which maximize the likelihood (probability) of the observed data. Basic fact: The probability of an event is the sum of the probabilities of the simple events it contains. The probability space here: all sequences of 2 tosses:
Defining The Problem Thus, we need to find parameters θ which maximize: • Finding an optimal solution is in general a difficult task. • Hence we do the following procedure: • “Guess” initial parameters • Repeatedly improve the parameters using the EM algorithm (to be studied later in this course). • Next, we exemplify the EM algorithm on the above example.
E step: Average Counts: We use the probabilities of the events to generate “average counts” of the outcomes: Average count of 0 is 2*0.125=0.25. Average count of 1 is 2*0.0625=0.125 . Average count of 2 is 2*0.125=0.25.
M step: Updating probabilities by the average counts The total of all average count is: 2*0.25+0.125=0.625. The new relative frequencies equal the new parameters, λ1, λ2, λ3 : The probabilities of the simple events according to the new parameters: The probability of the events by the new parameters:
Summary of the algorithm: • Start with some estimated parameters θ. • Use these parameters to define average counts of the outcomes. • define new parameters λ by the relative frequencies of the average counts. We will show that this algorithm never decreases, and usually increases the likelihood of the data. An application of this algorithm for HMM is known as the Baum Welch algorithm, which we will see next.