Early Profile Pruning on XML-aware Publish-Subscribe Systems
20 likes | 149 Vues
This research evaluates a bottom-up filtering approach for XML-based publish/subscribe systems, focusing on two innovative sequences that enhance query optimization. It discusses the increased relevance of content-based dissemination systems and their operational mechanics surrounding document processing and profile matching using the Prüfer sequence. The study offers insights into algorithmic efficiencies in managing subscriptions and publishing messages, highlighting advancements in matching algorithms for XML content, as presented at the 33rd International Conference on Very Large Data Bases (VLDB) in 2007.

Early Profile Pruning on XML-aware Publish-Subscribe Systems
E N D
Presentation Transcript
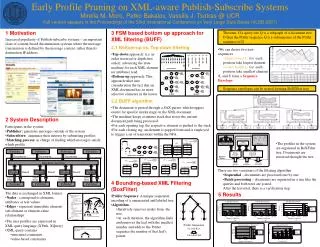
Bib article article vol year title title root no Q1 a Q2 a Q4 a Q5 e Q6 e Q3 a 7 1996 Profile Index Profiles proceedings t1 11 t2 a a a a a a a a a a a year SIGMOD journal a1 author b c e e f g P1 P2 P3 1 </e> b b b b b b b b b b b 2006 TPDS Prüfer Sequence b2 b5 </d> c d f f h h last first c c c c c c c c c c c author d c3 c6 d <d> c d b d h 4 1 2 d 3 Florescu Daniela e last mi first (a) (b) (c) c c c <c> (a) Document (b) Queries Q1 d4 d7 e9 0 Structural constraints: ////article[/author[@last=``Smith'']]//procs[@conf=``VLDB''] f b b b <b> DeWitt J David c b a 5 6 7 8 a e8 a a a c d f10 <a> Profile Manager Matching Algorithm Tree pattern: 3 2 4 b 3 4 Q2 b c article (a) Document and BUFF (b) (c) (d) Q1 1 2 Q1 d a c d 5 6 1 5 Matching Module author proceedings Q2 e Q2 5 1 a </f> </e> 2 </d> f h f e a 3,6 </c> 7 8 9 6 7 0 8 last conf 0 Q4 Q3 Q3 e h 5 1 e Profiles (queries) Input Documents Matched Documents h e a f f 11 12 10 11 12 1,2 1,2,5 1,2 c c c Q5 10 9 Q5 Q4 b b b b g h g e 13 14 14 13 a a a a Q6 Q6 (c) NFA (d) BUFF (e) (f) (g) (h) Publisher Publisher Publisher Publisher Publisher Publisher Documents Documents Documents Matching algorithm Profile Profile Profile Profile Result Result Result Submit, Modify Submit, Modify Submit, Modify Submit, Modify Publisher Publisher Publisher Publisher 1 A 2 B 5 D 3 C 6 E 8 F 4 E 7 E 9 D Prüfer Sequence 3 2 1 6 5 8 5 1 C B A E D F D A 1.03 0.95 0.35 Early Profile Pruning on XML-aware Publish-Subscribe Systems Mirella M. Moro, Petko Bakalov, Vassilis J. Tsotras @ UCR Full version appears in the Proceedings of the 33rd International Conference on Very Large Data Bases (VLDB 2007) 1 Motivation 3 FSM based bottom up approach for XML filtering (BUFF) Theorem: If a query tree Q is a subgraph of a document tree D then the Prüfer sequence Q is a subsequence of the Prüfer sequence of D Increased popularity of Publish-subscribe systems – an important class of content-based dissemination systems where the message transmission is defined by the message content, rather than its destination IP address. 2.1 Bottom-up vs. Top-down filtering • We can derive two new sequences • Upper bound U: for each position take largest element • Lower bound L: for each position take smallest element • L and U form a Sequence Envelope. • Top-down approach: (i.e. in-order traversal or depth first order): advancing the state machine for each XML element (or attribute) read. • Bottom-up approach: This approach takes into consideration the fact that an XML document has its more selective elements in the leaves Sequence envelopes can be nested forming BoXFilter tree 2.2 BUFF algorithm • The document is parsed through a SAX parser, which triggers events for specific marks (tags) in the XML document • The machine keeps a runtime stack that stores the current document path being processed. • For each opening tag, the respective element is pushed to the stack • For each closing tag, an element is popped from and is employed to trigger a set of transitions within the NFA. 2 System Description • Participants in the system: • Publisher: generates messages outside of the system • Subscribers: announce their interest by submitting profiles • Matching process: in charge of finding which messages satisfy which profile • The profiles in the system are organized in BoXFilter tree. Documents are traversed thought the tree Documents • There are two variations of the filtering algorithm • Sequential – documents are processed one by one • Batch processing – documents are organized in a tree like the queries and both trees are joined. • After the traversal, there is a verification step 4 Bounding-based XML Filtering (BoxFilter) • The data is exchanged in XML format. • Nodes - correspond to elements, attributes or text values • Edges - represent immediate element-sub element or element-value relationships 5 Results • Prüfer Sequence: A unique sequential encoding of a enumerated and labeled tree • Algorithm: • Iteratively removes nodes from the tree. • At each iteration, the algorithm finds and removes the leaf with the smallest number and adds to the Prüfer sequence the number of that leaf's parent. <Bib> <article vol=“7” no=“11”> <title>t1</title> <author> <last>DeWitt</last> <mi>J</mi> <first>David</first> </author> <journal>TPDS</journal> <year>1996</year> </article> <article> <title>t2</title> <author> <last>Florescu</last> <first>Daniela</first> </author> <proceedings>SIGMOD </proceedings> <year>2006</year> </article> </Bib> (b) Tree representation • The user profiles are expressed in XML query language (XPath, XQuery) • XML query contains • structural constraints • value-based constraints (a) Document





















