Download
1 / 1
10 likes | 114 Vues
Stage 1: Data preparation and loading. Global Motivation. * Obtain fast text query methods for a variety of “data-driven” NLP techniques * Develop practical methods for querying current gigabyte corpora (web collections…)

E N D
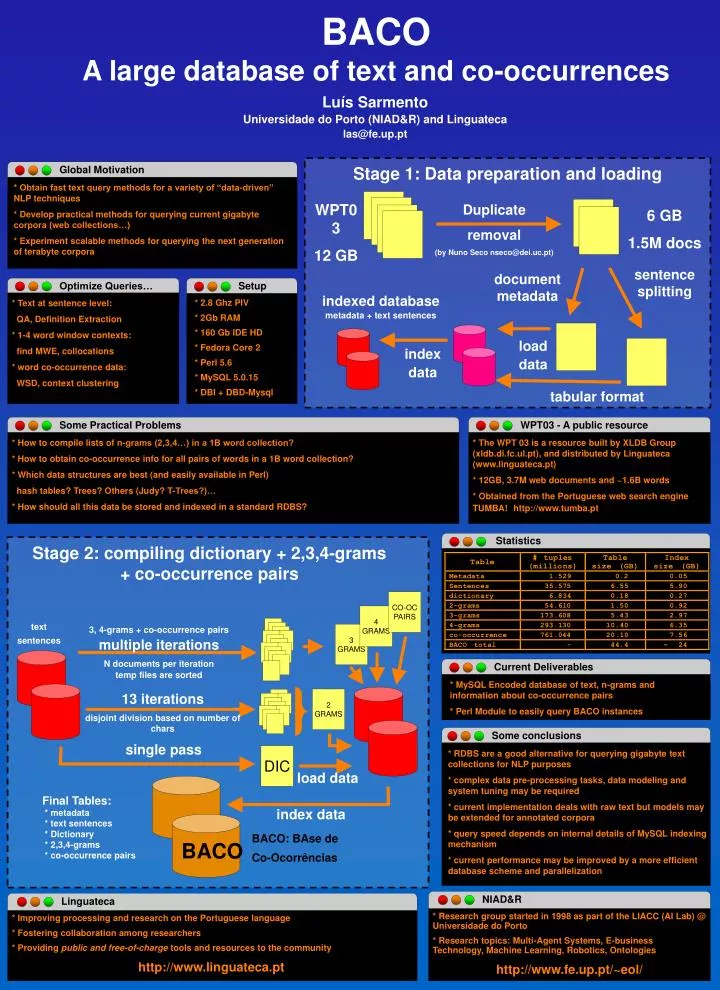
Stage 1: Data preparation and loading Global Motivation * Obtain fast text query methods for a variety of “data-driven” NLP techniques * Develop practical methods for querying current gigabyte corpora (web collections…) * Experiment scalable methods for querying the next generation of terabyte corpora WPT03 12 GB Duplicate removal (by Nuno Seco nseco@dei.uc.pt) 6 GB 1.5M docs sentence splitting document metadata Optimize Queries… Setup * Text at sentence level: QA, Definition Extraction * 1-4 word window contexts: find MWE, collocations * word co-occurrence data: WSD, context clustering * 2.8 Ghz PIV * 2Gb RAM * 160 Gb IDE HD * Fedora Core 2 * Perl 5.6 * MySQL 5.0.15 * DBI + DBD-Mysql indexed database metadata + text sentences load data index data tabular format WPT03 - A public resource Some Practical Problems * The WPT 03 is a resource built by XLDB Group (xldb.di.fc.ul.pt), and distributed by Linguateca (www.linguateca.pt) * 12GB, 3.7M web documents and ~1.6B words * Obtained from the Portuguese web search engine TUMBA!http://www.tumba.pt * How to compile lists of n-grams (2,3,4…) in a 1B word collection? * How to obtain co-occurrence info for all pairs of words in a 1B word collection? * Which data structures are best (and easily available in Perl) hash tables? Trees? Others (Judy? T-Trees?)… * How should all this data be stored and indexed in a standard RDBS? Statistics Stage 2: compiling dictionary + 2,3,4-grams + co-occurrence pairs CO-OC PAIRS 4 GRAMS 3, 4-grams + co-occurrence pairs multiple iterations N documents per iteration temp files are sorted text sentences 3 GRAMS Current Deliverables 2 GRAMS 13 iterations disjoint division based on number of chars * MySQL Encoded database of text, n-grams and information about co-occurrence pairs * Perl Module to easily query BACO instances single pass DIC Some conclusions load data * RDBS are a good alternative for querying gigabyte text collections for NLP purposes * complex data pre-processing tasks, data modeling and system tuning may be required * current implementation deals with raw text but models may be extended for annotated corpora * query speed depends on internal details of MySQL indexing mechanism * current performance may be improved by a more efficient database scheme and parallelization Final Tables: * metadata * text sentences * Dictionary * 2,3,4-grams * co-occurrence pairs index data BACO Linguateca NIAD&R * Improving processing and research on the Portuguese language * Fostering collaboration among researchers * Providing public and free-of-charge tools and resources to the community http://www.linguateca.pt * Research group started in 1998 as part of the LIACC (AI Lab) @ Universidade do Porto * Research topics: Multi-Agent Systems, E-business Technology, Machine Learning, Robotics, Ontologies http://www.fe.up.pt/~eol/ BACO A large database of text and co-occurrences Luís Sarmento Universidade do Porto (NIAD&R) and Linguateca las@fe.up.pt BACO: BAse de Co-Ocorrências

