Bayes becslések
Bayes becslések. Boha Roland 2006. november 21. PPKE-ITK. Miről lesz szó?. Bevezetés Ismétlés A becslés elve A becslés eredménye (valószínűségi sűrűségfüggvényként) Elméleti tulajdonságok Maximum a posteriori becslés. I. Bevezetés.


Bayes becslések
E N D
Presentation Transcript
Bayes becslések Boha Roland 2006. november 21. PPKE-ITK
Miről lesz szó? • Bevezetés • Ismétlés • A becslés elve • A becslés eredménye (valószínűségi sűrűségfüggvényként) • Elméleti tulajdonságok • Maximum a posteriori becslés
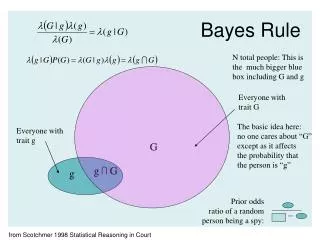
I. Bevezetés • Thomas Bayes (1702-1761): angol matematikus, teológus • Bayes tétele: Ha egy ,,kétfázisú'' kísérletben a második fázis eredményeiből akarunk visszakövetkeztetni az első fázis eredményére, akkor a Bayes-tétel hasznos segédeszköz. Legyen A és B két, pozitív valószínűségű esemény. A feltételes valószínűség definíciójából: P(B|A) = P(A|B)P(B)/P(A)(Bayes-formula).
Bayes becslések: fontosak, mert nemlineáris és korrelált mérési hibával terhelt rendszerek esetén is alkalmazhatók. • Alkalmazott Bayes: irányításelmélet, paraméterbecslés, spamszűrés, stb.
Véletlen: Klasszikus vs. Bayes • Identifikációs probléma Bayes-i megközelítésben • „Klasszikus” véletlen fogalma: az értékére vonatkozó mérések/kísérletek nem minden esetben ugyanolyanok, hanem ingadozást mutatnak. (Így egy rendszer paramétereinek értéke invariáns esetben konstans, azaz (nem véletlen) determinisztikus változó.) • Klasszikus felhasználás: véletlen természetű folyamatok (pl. radioaktív bomlás) && sok kicsi, egymástól fgtlen, de külön nem modellezett folyamat jelenléte
Véletlen Bayes-féle értelmezése: a megfigyelést végző személy tudása szerint osztályozza a változókat; • Bayes értelemben véletlen változó minden változó és paraméter is akár, ami előttünk, mint megfigyelő előtt nem ismert. Így az ismeretlen rendszerparaméterek valószínűségi változónak tekintendők • A Bayes megközelítés képes egy jónak tűnő alapot adni különböző döntésekhez, például egy irányítási probléma esetében.
II. Ismétlés, elméleti alapok • Mindennek az alapja: Bayes formula és láncszabály (később) • Véletlen változóegy valós értéket vehet fel. • Általában a várható érték: x, véletlen változó valós, de ismeretlen értékkel, amit x-vel jelölünk. Az összes lehetséges, x által felvehető érték: Sx. • Ha Sx egy intervallum a valós tengelyen, vagy egy általános vektor, akkor folyamatos típusú véletlen változóról beszélünk • Így Sx = (x1, x2, …, xn), ami egy véges halmaz.
Szubjektív valószínűség: egy egység (pl.: 100%), ami Sx –en eloszlik, és megmutatja, hogy melyik értékek bekövetkezése lehetséges: x = xi, ha Pr [x = xi] = P(xi), és P(x) egy Sx-en értelmezett, valós nem negatív függvény. • Innen következik az, hogy Pr [x = xi vagy x = xj] = P(xi) + P(xj), és • Továbbá: Nem csak számok elhetnek ezek, például érmefeldobás: P(fej)+P(írás) = 1 • Sűrűség fgv: , ahol részhalmaza Sx-nek, és a függvénynek teljesítenie kell a relációt
Megjegyzés: P(.) és p(.) semmilyen jelentéssel nem bír, ha nem adjuk meg, hogy milyen véletlen változóról beszélünk. Pl.: p(x) = f(x) fgv, p(y) = f(y), p(2)-re nem jelenthetjük ki, hogy f(2), vagy g(2) lenne. • Együttes eloszlás: (2 vagy több változóra) pl.: ha x= (a, b) és Sx = Sa * Sb rendezett párok halmaza, ahol a eleme Sa és b eleme Sb, ott p(x) = p(a, b) az együttes eloszlása a két véletlen változónak. • Pl: a folytonos az Sa =(a1, a2) intervallumon, b pedig diszkrét: Sb = (b1, b2, b3). Ekkor p(a, b) meghatározható 3 fügvénnyel: {p(a, bi)= fi(a), i = 1, 2, 3} és fel is rajzólhatók úgy, hogy teljesítik a
Bayes-i értelemben a statisztikai beavatkozás nem más, mint a megelőző egyéni valószínűségi eloszlások korrekciója az elvárásoknak megfelelő (valós) adatokkal. • Ez azt jelenti, hogy az feltételes valószínűségi eloszlások adják egy-egy döntés alapját.
Bayes formula klasszikus esetben • Adottak Bi események és P(Bi) valószínűségeik B1, B2,…,Bm elemei B eseményalgebrának, ahol: B1, B2,…,Bn teljes eseményrendszer: Továbbá P(Bi)>0 i=1,2,…,N A más sokat emlegetett Bayes tétel.
II/b. Alapvető műveletek: • Adott egy együttes valségi eloszlás 2 véletlen változóra: a és b meghatározza b valségi eloszlását, anélkül, hogy a-ról bármit is tudnánk. Matematikailag: • Adot p(a, b), a eleme Sa b eleme Sb. p(b) így határozható meg:
a eleme Sa bizonyos esetekben igaz: Egyezményesen, ha a diszkrét, az integrált szummázással lehet helyettesíteni. Ha p(b) összefügg p(a,b)-val, akkor marginálisról beszélünk.
Tekintsük azt az esetet, hogy a és b nem ismert, de valahogy meghatározható a szubjektív valségi eloszlásuk, p(a,b). Ezután valahogy (pl. méréssel) megszerezzük b valódi értékét: • Így már csak a értéke ismeretlen, amihez a következőképpen juthatunk el: Adott p(a,b), meghatározzuk a feltételes eloszlást: p(a|b=ß), b≠ß esetben p(a,b)-nak nincs jelentősége, de mégsem változtatunk. Így meghatározni p(a|b=ß)-t, megfelel annak az esetnek, mikor p(a,b), b=ß. Tehát: p(a|b=ß) =κ* p(a,b)| b=ß , ahol κ az arányossági együttható. Így minden a-ra: p(a,b)| b=ß =O, tehát p(a|b=ß) = O.
Κ-t így kaphatjuk meg: Tudjuk, hogy:
Továbbá átírhatjuk a p(a|b=b) alakot egyszerűen p(a|b)-vé, és az előzőek alapján kimondhatjuk, hogy p(a|b)=p(a,b)/p(b). Ezt tovább alakítva kapjuk a p(a,b)= p(a|b) p(b) formulát. • Így kaphatunk együttes valségi eloszlást olyan esetekben, amikor feltételes (p(a|b)) és marginális (p(b)) eloszlások állnak rendelkezésünkre.
II/c. Független bizonytalan mennyiségek: • Két mennyiség akkor független, ha az egyik valódi értéke nem hordoz semmiféle információt a másikról, tehát: p(a|b)=p(a) Ha b ismeretlen p(b) valségi eloszlással, akkor p(a,b)= p(a|b) p(b) és p(a|b)=p(a) formulákból következik, hogy p(a,b) = p(a)p(b) Emellett p(a,b)= p(a|b)p(a), ha p(b|a)=p(b) Ez azt jelenti, hogy ha egy bizonytalan mennyiség nem függ egy másik bizonytalan mennyiségtől, akkor kölcsönösen függetlenek.
Hasznos lehet definiálni a feltételes függetlenséget: ha egy bizonytalan mennyiség valódi értéke: c, és b szintén bizonytalan mennyiség valódi értéke nem hordoz információt a bizonytalan mennyiségről, tehát a és b feltételesen függetlenek c tükrében, ha c ismert. Formálisan: p(a|b,c)=p(a|c) ebből következően: p(b|a,c) = p(b,c), viszont nem következik belőle p(a|b,c)=p(a|b)!
II/d. Származtatott relációk és a és b felcserélése itt: Bayes formula:
N db együttes valségi eloszlás: x1, x2,…, xn és alkalmazzuk: p(a,b)= p(a|b)p(b) –t: p(xN,xN-1,…,x1)=p(xN|xN-1,…,x1)* p(xN-1,xN-2…,x1)= p(xN|xN-1,…,x1)* p(xN-1,xN-2…,x1)* p(xN-2,…,x1) és N lépés után a láncszabályból következik: p(xN-1,xN-2…,x1)= A láncszabály tehát a feltételes és együttes sűrűségfüggvényekre vonatkozó összefüggés általánosítása több (N) valószínűségi változóra.
II/e. Kiegészítések • A rendszer identifikációs probléma csak része egy sokkal összetettebb döntési problémának. (pl.: előrejelzés, irányítás, stb.) • „A megfigyelés változtat egy véletlen változót valós számmá.” (Lindley, 1974) • Egyesek szerint a Bayes-i statisztikai módszerek nem másak, mint valószínűségi elméletek statisztikai problémákon alkalmazva. • Ez igaz is, egy bizonyos fokig, de a valségi elméletek a valségi eloszlásokat csak alakítani tudják egymásba, teljes biztonsággal létrehozni őket lehetetlen. • A bayes-i módszerekkel dolgozóknak is szüksége van az elsődleges eloszlásokra, és ezt felhasználva ismeretlen/bizonytalan mennyiségekről/eseményekről használható állításokat készíteni.
III. A becslés elve • A rendszer ezentúl a világ egy részét jelenti, amin egy identifikációs problémát szeretnénk megoldani. • Ennek elvégzésére egy idősorozat szerű megfigyelést végzünk a rendszeren, az egyes megfigyelések: D(1),…,D(t),…, ezek az adatok. Általában két adatfajta figyelhető meg: bementi (u(t)) és kimeneti (y(t)) adatok. Így tehát: D(t)= {u(t), y(t)} • Kimenetek passzívan figyelhetők meg, ha D(t)={y(t)}, akkor a rendszert autonómnak hívjuk. • Az első megfigyelési pár általában a D(1)={u(1), y(1)}.
Rövidített jelölés: x. Helyettesíti u-t, y-t, D-t is: x(j)(i) = {x(i), x(i+j),…,x(j)}. Ha j<i, akkor üres halmaz. Tehát: • x(j)(i) ={x(j), x(j-1)(i)} és D(j)(i) ={y(j),u(j), D(j-1)(i)} , (i) kihagyható, ha 1-et jelent. Az összes adat D(t)={D(1),…,D(t-1), D(t)} • Mit kell ahhoz tudni, hogy képesek legyünk megoldani ezt a problémát? • Ha van egy ismert állapot: D(to), amihez tervezni kell egy irányítási stratégiát a következő N (tetszőleges, de véges) lépésre: • D(to+N)(to+1) megad minden szükséges információt • Ahhoz, hogy optimális műveletsort találjunk, képesnek kell lennünk arra, hogy előrejelezzünk, mielőtt alkalmazzuk az u(to+1) bemenetet. Így: p(D(to+N)(to+1) | D(to)) feltételes valségi eloszlásra van szükségünk.
Alkalmazva a láncszabályt: p(D(to+N)(to+1) | D(to))= Alapvető egyenlőségeket felhasználva: p(D(t)|D(t-1)) = p(y(t), u(t)|D(t-1))=p(y(t)|u(t), D(t-1))p(u(t)|D(t-1)), ahonnan megkapható: Ahol a feltételes valségi eloszlás p(u(t)|D(t-1)) leírja a transzformációt. Így a rendszer előző állapotai és t=to+1,…,t0+N segítségével egy irányítása megadható.
Ha az irányítási stratégia determinisztikus, pl.: u(t)= f(t) (D(t-1)), akkor p(u(t)|D(t-1))=δ(u(t)- f(t) (D(t-1))), ahol δ Lehet Dirac (ha u(t) folyamatos) és Kronecker δ (δ(δ(0)=1) és δ(x)=0, ha x ≠ 0) is, ha u(t) diszkrét. • Amit nem ír le, pl.: a feltételes valségi eloszlást p(y(t)|u(t), D(t-1)) leírja minden t-re y(t) függvényében. • Egy rendszermodellen olyan matematikai modellt értünk, ami leírja a feltételes valségi eloszlásokat egy időintervallumra, véges számú paraméterbeállítás mellet. (Paraméter itt: időinvariáns mennyiség, egy konstans.)
Abban az esetben, amikor néhány, vagy az összes paraméter halmaza véges, azt mondjuk Θ ismeretlen vagy bizonytalan: p(y(t)|u(t), D(t-1), Θ) definiálja a feltételes eloszlásokat. Amikor nem ismerjük Θ valódi értékét, akkor ez a formula addig használhatatlan, amíg nem ejtjük ki a modell ismeretlen paramétereit: p(y(t)|u(t), D(t-1)) = Ahol az integrál első fele az előbb látott eloszlás, a második pedig a valségi eloszlás, ami leírja a paraméterek bizonytalanságát egy adott időpillanatban.
Így a rendszer identifikációs problémája két részre bontható: a.) a modellstruktúra olyan megválasztására, ami leírja a feltételes valségi eloszlásokat b.) a modell paraméterek értékelése (pl.: feltételes valségi eloszlás meghatározása)
III/b.:1. Példa • Tekintsünk egy autonóm rendszert, nem megfigyelhető bemenetekkel, és egy olyan kimenettel, ami véletlen események sorozatának a kimenete 2 lehetséges kimenettel: A és Ā. Így y(t) ≡ A, vagy y(t) ≡ Ā, de azt nem tudjuk, hogy melyik fog megvalósulni. Világos, hogy a kimeneti halmaz kételemű: Sy = {A, Ā}, és p(y(t))=f(t)(y(t)), aminek teljesítenie kell a következő relációt: f(t)(A)+f(t)(Ā) = 1. Ez jól leírható egy számmal: f(t)(A) = α és f(t)(Ā) = 1-α. A modell megalkotásához néhány feltétellel kell élnünk:
Ha a rendszerről rendelkezésre álló alapvető információk alapján meghatároztuk a rendszermodellt, a valségi eloszlása p(y(t)), azaz α(t) szám is a priori információkon alapul. Emellett a rendszer előző állapotai egyéb információval nem szolgálnak y(t)-ről. • Emellett a rendszerről feltételezhetjük a priori információk alapján, hogy α(t) mindenhol ugyanaz. • Így a modellünk: p(y(t)|y(t-1)) = α, minden y(t) ≡ A-ra, és p(y(t)|y(t-1)) = 1-α minden y(t) ≡ Ā-ra. És ezt jól leírja egy Θ= α paraméter. • Minden valségi eloszlás feltételes, gyakran nehéz egyszerűen kifejezni őket.
Van olyan eset, amikor az első feltevésünk alapján nem határozható meg α paraméter. Ekkor átfogalmazhatjuk a következőképpen: Ha többet tudunk a rendszerről és meg tudjuk határozni α paramétert, akkor a rendszer „előéletéről” több információt is kaphatunk a folyamat várható kimeneteléről. (y(t)) Így a függetlenséget feltételes függetlenségre cseréltük így: p(y(t)|y(t-1), α)= p(y(t)| α). Így az ismeretlen paraméter egy folyamatos véletlen változóként figyelhető meg (α), ami 0 és 1 közötti valós értékű. Sα= <0,1>. • A modell az előzőek helyett így definiálható: p(y(t)|y(t-1), α) = α, minden y(t) ≡ A-ra, és p(y(t)|y(t-1), α) = 1-α minden y(t) ≡ Ā-ra. Ahol α változó és nem konstans.
A kimenetek előrejelzéséhez a formula itt így használható: • y(t) ≡ A-ra: • y(t) ≡ Ā-ra:
III/c.: Diszkrét fehér zaj • Ha a kimenet egy véletlen változó, akkor érdemes bevezetni egy függő valváltozót, ami megadja a y(t) és a korábbi ki és bemeneti adatok feltételes középértéke közti kapcsolatot. (e(t)) • Ha y(t) kimenet egy v oszlopvektor, akkor e(t)-t így definiálhatom:
e(t) (t=1,2,…) sorozat tulajdonságai: E[e(t)]=0 (1) E[e(t) eT (t-i)]=0; i ≠ 0, i<t (2) E[e(t) yT (t-i)]=0; 0<i<t (3) E[e(t) uT(t-i)] = 0; 0≤i<t (4) Ha létezik véletlen változók egy sorozata, (1) alapján nulla értékkel, ha kölcsönösen korrelálatlanok (2), akkor diszkrét fehér zajról beszélünk.
i>0 estetben: • i<0-ra időeltolás: τ=t-1 g() időinvariáns, a kovariancia mátrix konstans: Adott u(t) és D(t-1), akkor y(t) és e(t) az előzőek alapján:
A műveleti modell megadható egy sztochasztikus egyenlet formájában: (láttuk már ezt az előbb is…) • g(e(t))~N(O,R), ahol a modell jól le van írva, ha R kovariancia mátrixszal y^(t) kifejezett a ki- és bemenetekből.
III/d.: Lineáris regressziós modell • Tekintsünk egy rendszert, aminek bemenetei:μ kimenetei: v, mindkettő folytonos a megfelelő u(t) є Rμ és y(t) є R v intervallumon. y (t) függ az u(t) és a megelőző n ki- és bemeneti állapottól, D(t-1)(t-n) megadható. • Ha n elég nagy, akkor lehetnek olyan korábbi állapotok, amik nem hordoznak elég információt y(t)-ről. • Matematikailag: p(y(t)|u(t),D(t-1))=p(y(t)|u(t),D(t-1)(t-n)) és y^(t)(u(t), D(t-1))=y^(t)(u(t), D(t-1)(t-n))
N-ed rendű lineáris regressziós modell Ahol {e(t)} diszkrét fehér zaj konstans R kovariancia mátrixszal. T>n esetben a modell jól leírható a paraméterekkel: Θ={Ai (i=1,…,n), Bi (i=0,1,…,n), c, R}
III/e.: Inkrementális regressziós modell • Gyakran a valódi feladatok nem stacionáriusak • A c konstansból egy elég nehezen előrejelezhető változó lesz, ilyenkor ez a legmegfelelőbb eljárás:
A modell a következő formára írható át: y(t-1): az utolsó ismert állapot. ,ahol {c(t)} egy független növekedésű sztochasztikus folyamat. c(t)= c(t-1)+ e(t) , azaz egy összeadott fehér zaj. {e(t)}
III/f.: ARMA modell • y^(t)-ről feltesszük, hogy a megelőző ki és bemenetek függvénye. Ez azt jelenti, hogy egy determinisztikus függvény lesz az egész eddigi ki és bemenetek alapján. • Emellett feltesszük, hogy rekurzívan így definiálható: A homogén rész stabil, mert minden gyök kívül van az egységkörön.
Ha az y^(t)=y(t)-e(t) helyettesítéssel élünk, akkor egy közismertebb formát kapunk: Ahol Ai=Ci-Gi, és általában a modell a konstans c nélkül használatos, ugyanis ehy helyes átskálázással (u(t) és/vagy y(t)) kiiktatható, de ismerni kell hozzá a mátrix-együtthatókat.
Az ilyen modelleket ARMA modelleknek hívjuk, és közvetlenül függnek a valségi eloszlásoktól: p(y(t)|u(t), D(t-1)) • A diff. egyenletek felírásához szükséges: Θ={Gi (i=1,2,…,n), Bi (i=0,1,…,n), Ci (1,2,…,n), c, R y^(i) (1,2,…,n)}, ahol y^(i) a kezdeti állapotok. Ha a rendszer „előélete” elég hosszan ismert, akkor y^(i) elhagyható: 0-nak és ismertnek tekinthető. Az ARMA modell sajnos csak akkor használható jól, ha Ci rögzített, mint ismert információ.
III/g: Állapottér modell • A rendszermodellel kapcsolatban felvetődik a probléma, hogy hogyan paraméterezzünk egy feltételes valségi eloszlást t>t0 esetben. • Általában t-től különböző dimenziójú skalárfüggvény lesz • Emellett s(t-1) véges dimenziós halmazzal is leírható, ami elegendő statisztikát tartalmaz y(t)-ről, így: p(y(t)|u(t), D(t-1)) = Ψ(y(t),u(t),s(t-1)) és legyen igaz: s(t)=Φ(s(t-1),u(t),y(t)). Így a modellezési probléma lecsökkenthető s(t) dimenziómegválasztására és Ψ skalár fgv parametrizálására.
dekompozíció y^(t) és Φ(t) linearitásából • Összeadva néhány előző egyenlettel: p(e(t)|u(t),s(t-1))=p(e(t))~N(O,R) • Együtt az előzővel definiálja Ψ függvényt. • s(t)=A s(t-1)+B u(t)+ H e(t), ahol A=H+GC B=GD+F • y(t)-t és a másodi s(t)-t megadó egyenletet innovációs formulának hívják
III/h.: Mérhető külső zajok • adatgyűjtés modellezés előtt, vannak priori információk, amik mindig elérhetőek • Ilyen, és a legfontosabb a kimenet: y(t) Két részhalamzra osztható: y(t)={v(t), ys(t)}, Ahol v(t) a mérhető külső zaj, ami függ a múltjától, de a jelentől nem. A múltbeli értékek megfigyelhetők: p(v(t)|ys(t), u(t), D(t-1))=p(v(t)|v(t-1)). Tekinthetőek egy önálló irányíthatatlan környezetnek. ys(t): pedig a „külső világ” irányított részének kimenete
Felírhatjuk továbbá: p(y(t)|u(t), D(t-1))= p(v(t), ys(t)|u(t), D(t-1))=p(v(t)|ys(t),u(t), D(t-1)) * p(ys(t)|u(t),D(t-1)) és a külső zajok definiálása szerint: p(y(t)|u(t), D(t-1))= p(v(t)|v(t-1)) p(ys(t)|u(t), D(t-1)), így a modell felbontható két részre, ahol az első rész a külső, mérhető zajokat a második pedig a rendszert magát írja le. A valségi eloszlás pedig egy általános leírást ad az irányításról, magában foglalva a mérhető zajokat: p(u(t)|D(t-1))=p(u(t)|u(t-1), ys(t-1),v(t-1))
IV. Paraméter értékelés és kimenet becslés • Tegyük fel, hogy egy rendszermodellt ismerünk Θ paramétereiből. Így egy bizonyos τ időintervallumon (τ= t0+1, t0+2,…,t) a feltételes valségi eloszlás a következőképpen alakul: p(y(τ)|u(τ), D(τ-1), Θ) • Ezzel kapcsolatban felmerülő kérdések: Hogyan nyerhetők ki azok a paraméterek, amik a ki- és bemeneti adatokat tartalmazzák? (Bayes-i feltevésben: Hogyan számolható aposteriori valségi eloszlás? p(Θ|D(t)) ) Hogyan jelezhető előre egy adott bemenetre egy kimenet, ha csak az előző kimenetek ismertek? (Bayes-i feltevésben: Hogyan számítható y(t+1) feltételes valségi eloszlása u(t+1) és D(t) feltételével, (Θ, mint feltétel itt nem szerepel) )
Ahol az első rész a feltételes valségi eloszlás, amit a modell szerkezete határoz meg. A fenti kérdések közül második megoldódik, ha az első megválaszolható, és megadható a kapcsolat aposzteriori valsédi eloszlás és az integrál második fele között. Valós idejű esetben az új ki- és bemeneti párokkal is frissítik a valségi eloszlást.
Valós időben és egy pillanatnyiban is következőképpen fogalmazhatjuk meg a problémát: Adott p(Θ|D(t-1)) és az adatok D(t)(t1+1) t1<t,határozzuk meg p(Θ|D(t)). • Ha boldogulunk vele T1=0 esetben, akkor az egy pillanat esetét megoldottuk, innen már csak t1=t-1 beállítást kell használnunk egy rekurzív formulához. Alkalmazva a Bayes formulát a=Θ, b= D(t)(t1+1) és c= D(t1)-re azt kapjuk, hogy: A használatához ki kell fejezni a feltételes valségi eloszlást
IV/b: Bemenetgenerálás • Autonóm rendszer – nincs megfigyelhető bemenete: D(τ)=y(τ) és a feltételes eloszlás itt p(y(τ)|y(τ-1), Θ), amik a modellben adottak. • A bemenet determinisztikus: minden u(k) (k= 1,2,…, τ) minden τ konstans paraméternek tekinthető és elhagyhatóak p(y(τ)|u(τ), D(τ-1), Θ)-ből. Ez az eset az előzőre vezethető vissza. • Sztochasztikus bemeneti sorozat: pl.: a kimenettől/ismeretlen (Θ) paraméterektől függetlenül jöttek létre: p(u(τ), D(τ-1), Θ)= p(u(τ)|u(τ-1)) • Zárt rendszer (pl. adaptív szabályozó) által generált bemenetek: függnek az előző kimenetektől és az ismeretlen (Θ) paraméterektől is. Mindegyik ugyanúgy megoldható…