Download

1 / 16
160 likes | 276 Vues
A Generic Fault Tolerant System for Dynamic Scheduling in Distributed System. Class project by Piyush Ranjan Satapathy & Van Lepham. Problem Addressed. What happens when scheduled jobs in a real distributed system fail due to fault causing behaviors?

E N D
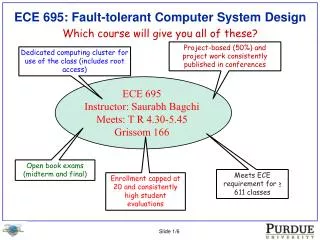
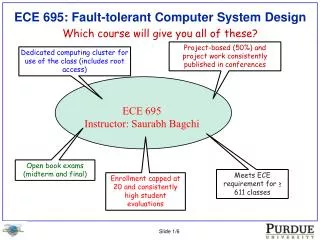
A Generic Fault Tolerant System for Dynamic Scheduling in Distributed System Class project by Piyush Ranjan Satapathy & Van Lepham CS253 Fall 05 by Dr Vana Kalogeraki
Problem Addressed • What happens when scheduled jobs in a real distributed system fail due to fault causing behaviors? • Can I schedule my jobs in different type of resources? • Is there a very generic tool for dynamic distributed scheduling of jobs? • Generic in the sense of any kind of resource, any kind of job, suitable algorithm and fault tolerant ? • Jobs ranging from running regression test cases to complex scientific calculations; anything which can run in parallel CS253 Fall 05 by Dr Vana Kalogeraki
Motivation • Can we have a system which can execute our distributed jobs dynamically or statically irrespective of any fault behaviors, minimizing the number of resources used and minimizing the total time of completion? • Can we make it up to a standard of both academics and industry? CS253 Fall 05 by Dr Vana Kalogeraki
Our Contribution • A system from scratch • Monitoring and Feedback Mechanism in real life parallel job execution • Implemented and Evaluated 5 Algorithms • A Java GUI for better user interaction CS253 Fall 05 by Dr Vana Kalogeraki
Outline • Introduction • Tools Visited (Related Work) • Our Central Idea (Architecture) • Implementation • Evaluation • Conclusion • Next Step CS253 Fall 05 by Dr Vana Kalogeraki
Introduction • There is no such tool academically or industry-wise which can fit into lot of environments • Our objective is easy to use, port and enhance • We monitor the running jobs and scheduled machines, collect info and use it for scheduling analysis • Our initial result of evaluation goes up to 10-15% of better performance over a resource of 40 machines out of which 11 are faulty CS253 Fall 05 by Dr Vana Kalogeraki
Tools Visited • OpenSTARS (2005) • A flexibleReal time and optimized tool to schedule the jobs in distributed system • But Don’t take care of any fault tolerant behaviors • Source: http://rtdev.cs.uri.edu/svn/repos/trunk/ • SPHINX(2005) • A fault tolerant system for scheduling on dynamic Grid environment • Source: http://sphinx.phys.ufl.edu/ • Cheddar(2004) • Free Real Time Scheduling Tool based EDF and LLF • Source: http://beru.univ-brest.fr/~singhoff/cheddar/ • VEST(2003) • Real time Schedulability Analysis for software to Hardware allocations. • Source: http://www.cs.virginia.edu/~ty4k/vestpage/ CS253 Fall 05 by Dr Vana Kalogeraki
Tools Visited • STAF(2001) • Software Test Automation FrameWork (IBM) across a number of machines. Good for software nightly build • Source: http://staf.sourceforge.net/index.php • TimeWiz(2000) • A Comprehensive tool for real-time modeling and analysis. • Source:http://www.timesys.com/products/timewiz/ • RapidRMA(1993) • Based on EDF and CORBA based Real time system • Source: http://www.tripac.com/html/downloads.html CS253 Fall 05 by Dr Vana Kalogeraki
Core Architecture 3 Layers: 1. Adoptive Analyzer 2. Monitoring and Feedback 3. Information Storage History Storage Native Machine Supervisor & Keeping History List of Machines Resource Monitor Analyzer Grid Clusters Sets Algorithm User scheduling job Job Monitor LSF Middleware Wide Variety of Resources CS253 Fall 05 by Dr Vana Kalogeraki
Implementation • An individual Job is presented as a script • Job list contains all jobs to be executed • Machine list contains name of machines or name of grid sites • Login Information (submit command, status command, kill command) for Grid/Lsf/Remote machine given • Either can be static or Dynamic • Monitoring and feedback can be turned on and off CS253 Fall 05 by Dr Vana Kalogeraki
Implementation (GUI) CS253 Fall 05 by Dr Vana Kalogeraki
Experimental Setup • 40 Machines inside the EBII Building • Fault Causing behaviors as below; • 5 Machines are not connected at all • 6 Machines connect and hang • 60 Jobs • Execution time differs from 2 sec to 5 minutes • 4 Algorithms considered • Round Robin (Working) • # CPU Based (Working) • Job Completion Based (Working) • EDF (..Yet to Work ) • LLF (…Yet to Work) CS253 Fall 05 by Dr Vana Kalogeraki
Evaluation CS253 Fall 05 by Dr Vana Kalogeraki
Conclusion • Designed a top to bottom dynamic distributed system • Implemented the fault tolerant techniques by monitoring and feedback • Stored the type of job and job history which executes once to make analyzer’s job easy • Got some initial interesting results over small experiments CS253 Fall 05 by Dr Vana Kalogeraki
What’s Next ? • We didn’t get a login ID either in Planet lab or in grid3 • Experiment in some grid • Implementing more algorithms • Running in real benchmarks CS253 Fall 05 by Dr Vana Kalogeraki
Thank You CS253 Fall 05 by Dr Vana Kalogeraki