Exploring Social Network Dynamics: Author Prestige and Co-authorship Analysis
This presentation, delivered by Miha Grčar under the guidance of Dr. Nada Lavrac at the Ljubljana Knowledge Management Course in January 2007, focuses on social network analysis. It covers data preprocessing techniques, the construction of directed networks, and the interplay between structural and social prestige. The session includes insights from a triad census of strong components within a co-authorship network and introduces methods for calculating proximity prestige. Conclusions emphasize the effectiveness of directed network models and qualities of Pajek software in analyzing author rankings based on citations.


Exploring Social Network Dynamics: Author Prestige and Co-authorship Analysis
E N D
Presentation Transcript
ILPnet2 social network analysis Miha Grčar Course in Knowledge Management Lecturer: prof. dr. Nada Lavrac Ljubljana, January 2007
Outline of the presentation • Data preprocessing • Directing the network • Social vs. structural prestige • Correlation between the two • Triad census of strong components in the co-authorship network • Hierarchy of authors with respect to co-authorship • Conclusions Miha Grčar
Data preprocessing # citations # (joint) publications Miha Grčar
Data preprocessing Pajek network file SQL Miha Grčar
Directing the network • Create a complete directed network • Logarithmize and normalize values • Allow each author to keep at most k outgoing arcs – the ones with the highest weights • Calculate proximity prestige for several different values of k and a, and determine its correlation with/to the social prestige represented by the number of citations Miha Grčar
Correlation Miha Grčar
Strong components triad census for k=3, a=1 ------------------------------------------------------------------------------------------------------ Type Number of triads (ni) Expected (ei) (ni-ei)/ei Model ------------------------------------------------------------------------------------------------------ 3 - 102 0 61.84 -1.00 Balance 16 - 300 0 0.00 -1.00 ------------------------------------------------------------------------------------------------------ 1 - 003 2985835 2984491.39 0.00 Clusterability ------------------------------------------------------------------------------------------------------ 4 - 021D 10 61.84 -0.84 Ranked Clusters 5 - 021U 1534 61.84 23.80 9 - 030T 28 0.33 85.14 12 - 120D 0 0.00 -1.00 13 - 120U 0 0.00 -1.00 ------------------------------------------------------------------------------------------------------ 2 - 012 44402 47062.30 -0.06 Transitivity ------------------------------------------------------------------------------------------------------ 14 - 120C 0 0.00 -1.00 Hierarchical Clusters 15 - 210 0 0.00 -1.00 ------------------------------------------------------------------------------------------------------ 6 - 021C 55 123.69 -0.56 Forbidden 7 - 111D 0 0.33 -1.00 8 - 111U 0 0.33 -1.00 10 - 030C 0 0.11 -1.00 11 - 201 0 0.00 -1.00 ------------------------------------------------------------------------------------------------------ Chi-Square: 37695.2629*** 10 cells (62.50%) have expected frequencies less than 5. The minimum expected cell frequency is 0.00. Miha Grčar
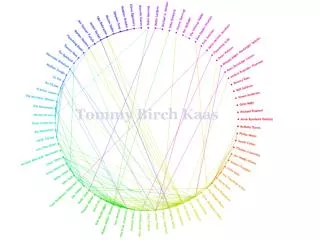
Strong components in k=3, a=1 Miha Grčar
Strong components, hierarchical view Miha Grčar
People, ranked clusters 1. Remove inter-cluster arcs 2. Convert bidirected intra-cluster arcs into edges 3. Remove all remaining arcs Miha Grčar
People, hierarchical view Miha Grčar
Conclusions • (Typical) data-mining data preprocessing process was presented • We have shown that some directed network models reflect the ranking of authors according to the citations quite well • We showed Pajek can be used to explore rankings and hierarchies in social networks • Slovene ILP team rocks! Miha Grčar