Sample Size and Statistical Power
Sample Size and Statistical Power. Epidemiology 655 Winter 1999 Jennifer Beebe. Determining Sufficient Sample Size. Purpose: To provide an understanding of the concepts of sample size and statistical power; to provide tools for sample size calculation.


Sample Size and Statistical Power
E N D
Presentation Transcript
Sample Size and Statistical Power Epidemiology 655 Winter 1999 Jennifer Beebe
Determining Sufficient Sample Size • Purpose: To provide an understanding of the concepts of sample size and statistical power; to provide tools for sample size calculation
Why do we worry about Sample Size and Power? • Sample size too big; too much power wastes money and resources on extra subjects without improving statistical results • Sample size too small; having too little power to detect meaningful differences • exposure (treatment) discarded as not important when in fact it is useful • Improving your research design • Improving chances for funding
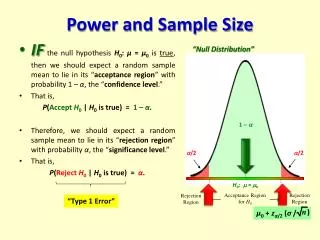
Review of Statistical Concepts • Hypothesis testing • Null hypothesis Ho: • No difference between groups; no effect of the covariate on the outcome • Alternative hypothesis Ha: • The researcher’s theory • Decision rule: • Reject Ho if a test statistic is in the critical region (p<.05)
Hypothesis Testing: Example • Ho: Diabetes is not associated with endometrial cancer in postmenopausal women • Ha: • Diabetes is associated with endometrial cancer; direction of association not specified (two-sided test) • Women with diabetes have an increased risk of developing endometrial cancer (one-sided test) • Women with diabetes have a decreased risk of developing endometrial cancer (one-sided test)
Under optimal conditions, we would examine all postmenopausal women with and without diabetes to determine if diabetes is associated with endometrial cancer • Instead, we collect data on a sample of postmenopausal women • Based on sample data, we would conduct a statistical test to determine whether or not to reject the null hypothesis
Errors • Our sample may not accurately reflect the target population and we may draw an incorrect conclusion about all postmenopausal women based on the data obtained from our sample • Type I and Type II errors
Two Types of Error • Type I: Rejecting the Ho when Ho is true • The probability of a Type I error is called • is the designated significance level of the test • Usually we set the critical value so =0.05 • In our example, we could conclude based on our sample, that diabetes is associated with endometrial cancer when there really is no association
P-values • Measure of a Type I error (random error) • Probability that you have obtained your study results by chance alone, given that your null hypothesis is true • If p=0.05, there is just a 5% chance that an observed association in your sample is due to random error
Example:Diabetes and Endometrial Cancer • From our sample data, we found that women who have diabetes are 2 times more likely to develop endometrial cancer when compared to women without diabetes (p=0.01) • If diabetes and endometrial cancer are not associated, there is a 1% probability that we would find this association by chance • if we set the critical value as 0.05; 0.01<0.05; we would reject Ho in favor of Ha
Type II Error • Type II: Accept Ho when Ha is true • The probability of a type II error is called • depends on the effect size (How far from Ho are we?) • If we are far from Ho, then is small • If we are close to Ho, then is large • In our example, we could conclude that there is no association between diabetes and endometrial cancer when in fact there is an association
Truth in the Population Association No association Study b/w predictor b/w predictor Results and outcome and outcome Reject Ho CorrectType I error Fail to Type II errorCorrect Reject Ho
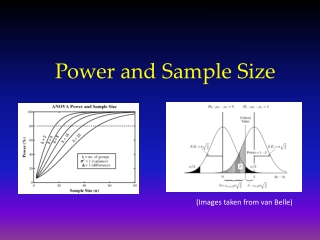
Power • Power is the probability of observing an effect of a particular magnitude in the sample if one of a specified effect size or greater actually exists in the population • Power = 1- • if =.20 then power =.80; we will accept a 20% chance of missing an association of a particular size b/w an exposure and an outcome if one really exists
and Levels • Usually range from 0.01-.10 () and from 0.05-.20 () • Convention =0.05 and =0.20 • Use low alpha’s to avoid false positives • Use low beta’s to avoid false negatives • Increased sample size will reduce type I and type II errors
Asking the sample size question? • What sample size do I need to have adequate power to detect a particular effect size (or difference)? • I only have N subjects available. What power will I have to detect a particular effect size (or difference) with that sample size?
Preparing to Calculate Sample Size • What kind of study are you doing? • Case-control, cross-sectional, cohort • What is the main purpose of the study? • What question(s) are you asking? • What is your outcome measure? • Is it continuous, dichotomous, ordinal? • The prevalence of exposure(s) in study population?
Preparing to Calculate Sample Size • What statistical tests will be used? • (t-test, ANOVA, chi-square, regression etc) • Will the test be one or two tailed? • What level will you use? • =0.05 • The hard one: How small an effect size (or difference) is important to detect? • What difference would you not want to miss? • With what degree of certainty (power) do you want to detect the effect? (80-95%)
Tradeoffs with Sample Size • Sample size is affected by effect size, , , power • If detected effect size is (Big OR or RR) then sample size • If detected effect size is (Small OR or RR) then sample size • If the effect size is fixed; • ; ; (1-); sample size
Tradeoffs with Power • Power affected by sample size, prevalence of exposure, , , effect size • sample size; power • effect size to detect; power • ; power • Power of study is optimal usually when prevalence of the exposure in the control or referent group is b/w 40-60% • Equal numbers of subjects in each group will increase power
Sample Size Requirements in a Cohort / Cross-sectional Study • In addition to specified and power, sample size depends on the • Incidence or probability of outcome among the unexposed • Ratio of exposed / unexposed • Relative risk/prevalence ratio that one regards as important to detect
Sample Size Requirements for a Case-control Study • In addition to specified and power, sample size depends on the • Ratio of cases to controls • Proportion of controls exposed • Odds ratio that one regards as important to detect
Sample Size and Power Software • EpiInfo • ProgramsStatcalcSample size and Power • User-friendly; easily accessible • nQuery • More sophisticated, lots of options, you need to supply program with more information • PASS, Power and Precision, GPower
Helpful Hints • Choose an effect size reasonable for observational studies (this may be based on previous literature) • Knowledge of prevalence of exposures of interest (also based on previous literature) • Increase sample size 10-20% for each major confounder