Exploiting Gene Clusters to Curate Annotations
Exploiting Gene Clusters to Curate Annotations . Ross Overbeek, Fellowship for Interpretation of Genomes (FIG). October, 2003. The Emerging Opportunity The Use of Clusters to Find “Missing Genes” Experiences with a Single Pathway “The Project” Tools Needed to Support the Project.


Exploiting Gene Clusters to Curate Annotations
E N D
Presentation Transcript
Exploiting Gene Clusters to Curate Annotations Ross Overbeek, Fellowship for Interpretation of Genomes (FIG) October, 2003
The Emerging Opportunity The Use of Clusters to Find “Missing Genes” Experiences with a Single Pathway “The Project” Tools Needed to Support the Project Outline of the Talk
The amount of available DNA sequence data will double every 18 months The number of available genomes will double every 18 months The cost of sequence will drop by a factor of 2 every 18 months. Three “Laws”
We have about 230-250 publicly available more-or-less complete genomes We will have about 1000 complete genomes within 3 years This will lead to better annotations, not worse The majority of annotations will need to be automated, and the process must accurately follow the steps that a human expert would take Basic Facts
Central Machinery of Life:Horizons of gene discovery • 3,000 - 4,000 functional roles (300 – 3,000 per organism) • Largely conserved across the three kingdoms(sequences; functions; pathways) • “Missing genes” are still there
Missing genes in metabolic pathwaysmaking a case Globally Missing Gene (never identified in any species) Missing gene E1 E2 E3 + + A B C D E F gene A gene B? gene C
Missing genes in metabolic pathwaysmaking a case Missing gene E1 E2 E3 + + A B C D E F gene A gene B? gene C Locally Missing Gene (non-orthologous gene displacement)
Techniques of genome context analysis (I)checking neighbors GENE CLUSTERING ON THE CHROMOSOME (OPERONS) gene G1 gene T1 gene A1 gene X1 gene C1 gene R1 GENOME 1 gene A2 gene M2 gene X2 gene Y2 gene C2 gene N2 GENOME 2 gene Q3 gene X3 gene A3 gene S3 gene U3 gene Y3 GENOME 3
Techniques of genome context analysis (II)checking connections PROTEIN FUSION EVENTS gene A1 gene C1 GENOME 1 gene A3 / Z3 gene C3 GENOME 3 / X4 gene C4 gene A4 GENOME 4 / A5 gene C5 GENOME 5
Techniques of genome context analysis (III)co-regulation SHARED REGULATORY SITES (REGULONS ) gene T1 gene A1 gene X1 gene C1 gene R1 GENOME 1 gene A2 gene W2 gene C2 GENOME 2 gene R5 gene X5 / A5 gene C5 GENOME 5
Techniques of genome context analysis (IV)co-evolution 10 10 10 8 6 4 4 3 5 Score: OCCURRENCE PROFILES IN-GROUP gene A1 gene C1 gene X1 gene G1 gene H1 gene W1 gene Y1 gene Z1 gene I1 GENOME 1 - gene A2 gene C2 gene X2 gene G2 gene H2 gene W2 gene Y2 gene I2 GENOME 2 gene A3 gene C3 gene X3 gene G3 gene H3 gene W3 gene Y3 gene Z3 gene I3 GENOME 3 - - - gene A4 gene C4 gene X4 gene H4 gene W4 gene I4 GENOME 4 - gene A5 gene C5 gene X5 gene G5 gene H5 gene W5 gene I5 - GENOME 5 OUT-GROUP - - - - gene H6 gene W6 gene Y6 gene Z6 gene I6 GENOME 6 - - - - gene G7 gene H7 gene W7 gene Z7 gene I7 GENOME 7 - - - - - gene H8 gene W8 gene Y8 gene I8 GENOME 8 - - - - gene H9 gene W9 gene Y9 gene Z9 gene I9 GENOME 9 - - - - gene W10 gene Y10 gene Z10 gene I10 - GENOME 10
Example I: Chorismate Pathway Missing gene in all archaea D-Erythrose 4-P Shikimate Shikimate - 5 - P + Shikimate Kinase (EC 1.1.1.25) Phosphoenol pyruvate H H H H 5 6 7 3 2 1 4 H H O P O H aroH C O O H C O O H H H O H O H aroF O H O H aroK aroG aroL H H H H 7P-2-Dehydro-3- deoxy-D-arabino -heptulosonate O5-(1-Carboxyvinyl)- 3-P-Shikimate aroB 3-Dehydro-Quinate Chorismate aroD aroA aroC ydiB Trp Phe Tyr syntheses Chorismate catabolism Isochorismate anabolism aroD 3-Dehydro-Shikimate
Chromosomal Clustering: Prediction ?? ?? Fusion Protein Fusion Protein
Functional coupling in chorismate pathway Clustering Fusion Occurence
Example II: “Missing Drug Target” in S.pneumoniae accA accD accB GenefabI of Enoyl-ACP reductase (EC 1.3.1.9) is missing in a number of Streptococci accC fabD fabF fabH fabG fabZ fabI acpP
Clustering of FAB Genes : Prediction g30k L32P PLSX fabH fabD fabG acpP fabF EC 4… 2.7.4.9 2.7.7.7 MAF Escherichia coli fabG fabF fabZ accC accD accA fabI 6.3.4.15 hyp acpP fabD accB hyp TR? 3.5.1.? fabH Genome X acpP fabH ? fabG fabF fabZ accC accD accA fabD accB TR? 2.1.1.79 FRNS Genome Y acpP fabG fabF fabZ accC accD accA fabH fabD accB ? TR? 5.99.1.2 Clostridium acetobutylicum acpP fabH ? TR? fabG fabF fabZ accC accD accA fabD accB hyp Streptococcus pyogenes A conserved hypothetical FMN-binding protein “?” is the best candidate for the missing genefabI in Gram-positive cocci
13 July 2000 Nature406, 145 - 146 (2000) © Macmillan Publishers Ltd. Independent Experimental Verification Microbiology: A triclosan-resistant bacterial enzyme RICHARD J. HEATH AND CHARLES O. ROCK Triclosan is an antimicrobial agent that is widely used in a variety of consumer products and acts by inhibiting one of the highly conserved enzymes (enoyl-ACP reductase, or FabI) of bacterial fatty-acid biosynthesis. But several key pathogenic bacteria do not possess FabI, and here we describe a unique triclosan-resistant flavoprotein, FabK, that can also catalyse this reaction in Streptococcus pneumoniae. Our finding has implications for the development of FabI-specific inhibitors as antibacterial agents.
Missing genes, examples in cofactor pathwaysprediction and experimental verification
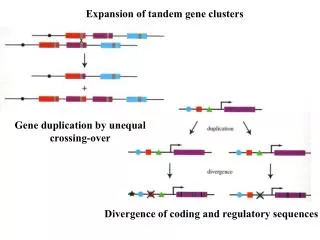
The Leucine Degradation Cluster:Origin of a New Perspective on Uses of Clusters
Context-based enrichment of initial functional assignmentsexample from Brucella melitensis genome analysis Leu Acetyl- CoA deamination oxydation Methylcrotonoyl-CoA carboxylase (EC 6.4.1.4) Isovaleryl-CoA dehydrogenase (EC 1.3.99.10) Methylglutaconyl- CoA hydratase (EC 4.2.1.18) Iso- valeryl- CoA Methyl- crotonoyl- CoA Methyl- glutaconyl- CoA HMG- CoA 4.1.3.4 biotin-containing subunit Aceto- acetate carboxylase subunit 6.2.1.16 TIGR E.C. No Functional role Gene ID No. in cluster 1.3.99.10 ISOVALERYL-COA DEHYDROGENASE BR0020 1 1 6.4.1.4 METHYLCROTONYL-COA CARBOXYLASE - Biotin-containing subunit BR0018 3 - Carboxylase subunit BR0019 4 4.2.1.18 METHYLGLUTACONYL-COA HYDRATASE BR0016 2 -------------------------------------------------------------------------------------------------------------------- 4.1.3.4 HYDROXYMETHYLGLUTARYL-COA LYASE BR0017* 6 6.2.1.16 ACETOACETATE-COA LIGASE BR0021 5 specific BR0020 non-specific* BR0018 non-specific* BR0019 non-specific* BR0016 frameshift BR0017* BR0021 specific * Biotin carboxylase; Carboxyl transferase familty subunit; Enoyl-CoA hydratase/isomerase family
Leucine degradation in Baccili No gene assigned in any organism in KEGG, NCBI, TIGR Gene assigned in B. melitensis 2003 (IG) Gene assignment propagated over 26 organisms using gene clustering
Organism Gene anchor Clustered genes 158 New assignments
Leucine degradation in Baccili ? E.C. No Functional role No. in cluster 1.3.99.10 ISOVALERYL-COA DEHYDROGENASE 2 6.4.1.4 METHYLCROTONYL-COA CARBOXYLASE - BIOTIN CONTAINING SUBUNIT 3 - CARBOXYLASE SUBUNIT1 BIOTIN CARBOXYL CARRIER 7 4.2.1.18 METHYLGLUTACONYL-COA HYDRATASE 4 -------------------------------------------------------------------------------------------------------------- 4.1.3.4 HYDROXYMETHYLGLUTARYL-COA LYASE 5 6.2.1.16 ACETOACETATE-COA LIGASE 6 6.2.1.16* ACETOACETATE-COA LIGASE* 14
By making the task concrete, we force engineering decisions It will be easier to annotate 1000 genomes well than to annotate 50 well (comparative analysis is the key) Analysis by subsystem (rather than by genome) is clearly the key The use of clusters is the key to precise annotation of subsystems The Project: Annotate 1000 Genomes in Three Years
Requires knowledge of known variants Evolution of clusters plays a major role There are three components of the task: Building tools to support analysis Actually doing the analysis on 30-50 subsystems Coordinating with groups doing a limited set of wet lab confirmations Annotation by Subsystem
Releasing the browser/curation tool with approximately 220-230 genomes within a few months Peer-to-peer updates/synchronization Open source and free (initially for Macs and Linux systems) FIG: Building the Initial Annotation Tools