Download

1 / 1
10 likes | 146 Vues
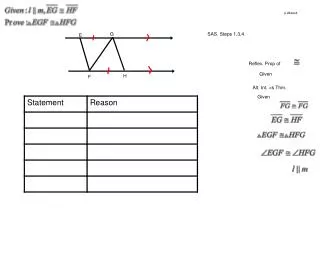
Explorations in Zero-Resource Spoken Term Detection Justin Chiu Language Technology Institute, Carnegie Mellon University. What is STD?. Preliminary Results. Given a query (text or audio ) Detection the query within target audio Common Approach: Recognized -> Search.

E N D
Explorations in Zero-Resource Spoken Term Detection Justin Chiu Language Technology Institute, Carnegie Mellon University What is STD? Preliminary Results • Given a query (text or audio) • Detection the query within target audio • Common Approach: Recognized -> Search Evaluation Measurement: ATWV Why Zero Resource? • Common approach rely on high quality recognizer • Language have not enough knowledge to construct recognizer • Dictionary • Language Model DET Graph: Development Set Preliminary Attempt 1.Extract the MFCC feature from audio DET Graph: Evaluation Set • 2.Clustering • Goal: Get a better higher level representation for audio • K-mean Clustering • GMM Clustering • 3.Representation • Hard representation • Vectors to fixed label (Available for both clustering) • Soft representation • Vector to different vector (Available for GMM clustering) Proposed Approach Using Successive State Splitting algorithm to train HMM Initially using 1 state HMM to describe the training audio Splitting the HMM state, then prune the state according to Maximum Likelihood Deciding the number of iteration for splitting and pruning Train an “acoustic model” to model these sub-word units Representing queries and audios with decoding Indexing and searching to perform term detection Advantage: Increasing the system’s robustness by giving stronger assumption compare to preliminary approach 3.Segmental Dynamic Time Warping Conclusions We have some explorations on the Zero-Resource STD Pattern matching does not work on speaker independent case We proposed a modeling approach to address this issue Stronger assumptions might make the system more robust • Hard distance: mismatch = 1, match = 0 • Hard distance can use Inverted Frequency Weighting • Soft distance: -log(a∙q) • Distance below certain Threshold treated as detection