Download

1 / 28
280 likes | 296 Vues
Learn about the use of biometrics and voice recognition in identifying individuals based on physiological and behavioral characteristics such as fingerprints, face recognition, and speech patterns.

E N D
BIOMETRICS VOICE RECOGNITION
Meaning • Bios : Life Metron : Measure • Biometrics are used to identify the input sample when compared to a template, used in cases to identify specific people by certain characteristics. • Possession based • Knowledge based
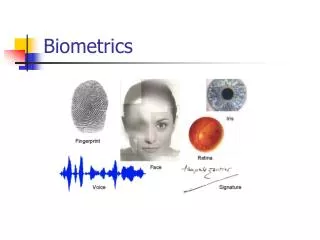
Physiological are related to the shape of the body. The oldest traits, that have been used for more than 100 years, are fingerprints. Other examples are face recognition, hand geometry and iris recognition.
Behavioral are related to the behavior of a person. The first characteristic to be used, still widely used today, is the signature. More modern approaches are the study of keystroke dynamics and of voice • Strictly speaking, voice is also a physiological trait because every person has a different pitch, but voice recognition is mainly based on the study of the way a person speaks, commonly classified as behavioral.
Introduction • Speaker recognition has a history dating back some four decades and uses the acoustic features of speech that have been found to differ between individuals.
There is a difference between speaker recognition (recognizing who is speaking) and speech recognition (recognizing what is being said). These two terms are frequently confused, as is voice recognition. • Voice recognition is a synonym for speaker, and thus not speech, recognition. In addition, there is a difference between the act of authentication (commonly referred to as speaker verification or speaker authentication) and identification.
If the speaker claims to be of a certain identity and the voice is used to verify this claim this is called verification or authentication. On the other hand, identification is the task of determining an unknown speaker's identity. • In a sense speaker verification is a 1:1 match where one speaker's voice is matched to one template (also called a "voice print") whereas speaker identification is a 1:N match where the voice is compared against N templates.
Variants of speaker recognition • Each speaker recognition system has two phases: Enrollment and verification. • ENROLLMENT • During enrollment, the speaker's voice is recorded and typically a number of features are extracted to form a voice print, template, or model.
Speech Samples are waveforms • Time on horizontal axis and Loudness on vertical axis • Speaker recognition system analyses frequency content • Compares characteristics such as the quality, duration intensity dynamic and pitch of the signal
. In the verification phase, a speech sample or "utterance" is compared against a previously created voice print.
Front-end processing - the "signal processing" part, which converts the sampled speech signal into set of feature vectors, which characterize the properties of speech that can separate different speakers. Front-end processing is performed both in training- and recognition phases. • Speaker modeling - this part performs a reduction of feature data by modeling the distributions of the feature vectors.
Speaker database - the speaker models are stored here. • Decision logic - makes the final decision about the identity of the speaker by comparing unknown feature vectors to all models in the database and selecting the best matching model.
Speaker recognition systems fall into two categories: text-dependent and text-independent. • If the text is same for enrollment and verification this is called text-dependent recognition • In a text-dependent system, prompts can either be common across all speakers (e.g.: a common pass phrase) or unique • In addition, the use of shared-secrets (e.g.: passwords and PINs) or knowledge-based information) can be employed in order to create a multi-factor authentication scenario.
Text-independent systems are most often used for speaker identification as they require very little if any cooperation by the speaker. • In this case the text during enrollment and test is different. In fact, the enrollment may happen without the user's knowledge, as in the case for many forensic applications. • As text-independent technologies do not compare what was said at enrollment and verification, verification applications tend to also employ speech recognition to determine what the user is saying at the point of authentication.
Erorrs • False Match Ratio(FMR) • False Non-match Rate(FNMR) • Failure To Enroll Rate
FMR • System gives false +ve matching a user biometrics with another user's biometrics. Type 1 error • Occurs when two people have high degree of similarity • It may used to eliminate the non matches. And continue the process again.
FNR • User’s templates is matched with the enrolled templates and an incorrect decision of non match is made. Type 2 error • Due to environment, aging, sickness.
FER • Biometric data of some user may not be clear.
Technology • The various technologies used to process and store voice prints include frequency estimation, hidden Markov models, gaussian mixture models, pattern matching algorithms, neural networks, matrix representation and decision trees. Some systems also use "anti-speaker" techniques, such as cohort models, and world models.
VQ Speaker Verification • Speech Feature Extraction
Cepstral Coefficients • Power of the triangular filter = summarized • Log calculated • Convert them to time domain using the Discrete Cosine Transform (DCT) • Result is called the mel frequency cepstral coefficients (MFCC).
Verification • Threshold • Cohort Speakers • Ratio
Speaker Verification and Speaker Recognition • Accessing confidential information areas • Access to remote computers • Voice dialing • Banking by telephone • Telephone shopping • Database access services • Information services • Voice mail • PIN code for your ATM