IO performance
In this retrospective analysis, I delve into the myriad challenges faced during a programming project amidst complex data-driven environments. From the pitfalls of overly intricate T/P implementations to the consequences of code bloat and inadequate testing infrastructure, my reflections reveal significant design issues and management shortcomings. I highlight essential improvements needed, such as better tools for automatic code generation, effective analysis recommendations, and the necessity for proper feedback mechanisms. The lessons learned aim to inform future projects to prevent repeating past mistakes.


IO performance
E N D
Presentation Transcript
IO performance Lessons
Disclaimer • I won’t be mentioning good things here. • In hindsight things look obvious • No plan survives the first data intact
Design problems • T/P is way too complex for an average HEP physicist turned programmer • This lead to copy/paste approach • Even good documentation can’t help that • Code bloating • Very difficult to remove obsolete persistent classes/converters • Tools needed added late: custom compressions/DataPool/ only now working on error matrix compression • No unit tests infrastructure • Should have had a way to create “full” object • Should have forced loopback t-p-t • No central place to control what’s written out • No tools for automatic code generation • Fabrizio spent 3 months just fixing part of Trigger classes
management problems • At least some performance tests should have been done before full system deployment. At least to understand what affects performance. • Trying to understand changes in what was written out after the fact is not the way things should go. • Way too many tools (ara, mana, event loop …) • No real support • Code bloat • Opportunity cost • Still there is no one good tool • that people would be happy to use • would provide us possibility to monitor and optimize • to start thinking about analysis meta data storage and access one year after data taking started is a bit late.
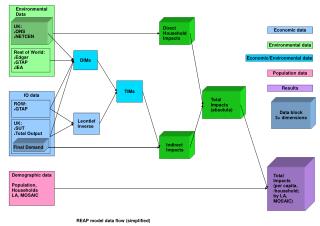
management problems • No recommended way to do analysis • Waiting to see what people would be doing is not the best idea. People can’t know if their way will scale or not. • We can’t test all approaches and surely can’t optimize sites for all of them Group production AOD G Grid Local CPU bound IO bound G D3PDmaker NTUPLE G L D3PD G Skim/slim download PROOF based Analysis L LG Simple ROOT Analysis
DPD problems • Having thousands of simple variables in DPD files is just so … not OO. • DPDs are expensive to produce • Train based production will alleviate problem • If train production will not use tag db, tag db should be dropped. • Probably way too large – and difficult to overhaul. If we have problems finding out if AOD collection is used or not, problem is 10 times bigger with dpds • Too small • Should/could be merged using latest ROOT version • Even worse with skimmed/slimmed. No simple grid based merge tool? • No single, generally used framework to use them • In half a year it will be way to late to start thinking about all of this as people will be already used to their hacked together but working tools.
DPD problems • Current situation • local disk • ROOT 5.28.00e • A lot of space for improvement! • Improvements to come • Proper basket size optimization • Too many reads with TTC • Multi-tree TTC • Now so much better that we are getting HDD seeks limited even for 100% of data read • Two jobs or one read/write job brings CPU efficiency down to unacceptable level • Calculations typically done in analysis jobs wont hide disk latency on 4 or 8 core CPU • Needs better file organization • Even reordering files would have sense
NO efficiency feedback • Up to now we had no resource contention. That’s changing. • People would not mind running faster and more efficiently, but have no idea how good/bad they are and what to change. • Will someone see the effect of not turning TTC in grid based job? Not likely. Consequently won’t turn it on. • I don’t know how to optimally split task. Do you? • Can be changed relatively easily: once a week send a mail to all people that used grid on what they consumed, how efficient they were and what they can do to improve.
My 2 cents • If one core is not 100% used when reading fully optimized file why bother with multicore things? • Due to very low “real” information density in production DPDs any analysis/slimming/skimming scheme is bound to be very inefficient. • A user that have done at least one round of slim/skim can opt for a map-reduce approach in form of proof. • But proof not an option for really large scale – production DPDs. • Thinking big – SkimSlimService • Organize large scale map-reduce at a set of sites capable of having all of the production DPDs on disk. • Has to return (register) produced skimmed/slimmed dataset in under 5 min. Limit size of the returned DS. • That eliminates 50% of all grid jobs. • Makes users produce 100 variable instead of 600 variable slims. • Relieves them of thinking about efficiency and gives result in 5 min instead of 2 days. • We don’t distribute DPDs. • We do optimizations.